FoundationDB Layers
A few days ago Apple open-sourced FoundationDB - a transactional (ACID) key-value database with crazy testing and ability to scale to peta-byte clusters. I wrote more on why this is so exciting in FoundationDB is Back!.
A few companies have been using FoundationDB in the past years:
- Apple - bought FoundationDB 3 years ago;
- WaveFront by VMWare - running petabyte clusters;
- Snowflake - cloud data warehouse.
What I didn't tell at the time: SkuVault happily used FoundationDB in the past years as well. This is the story.
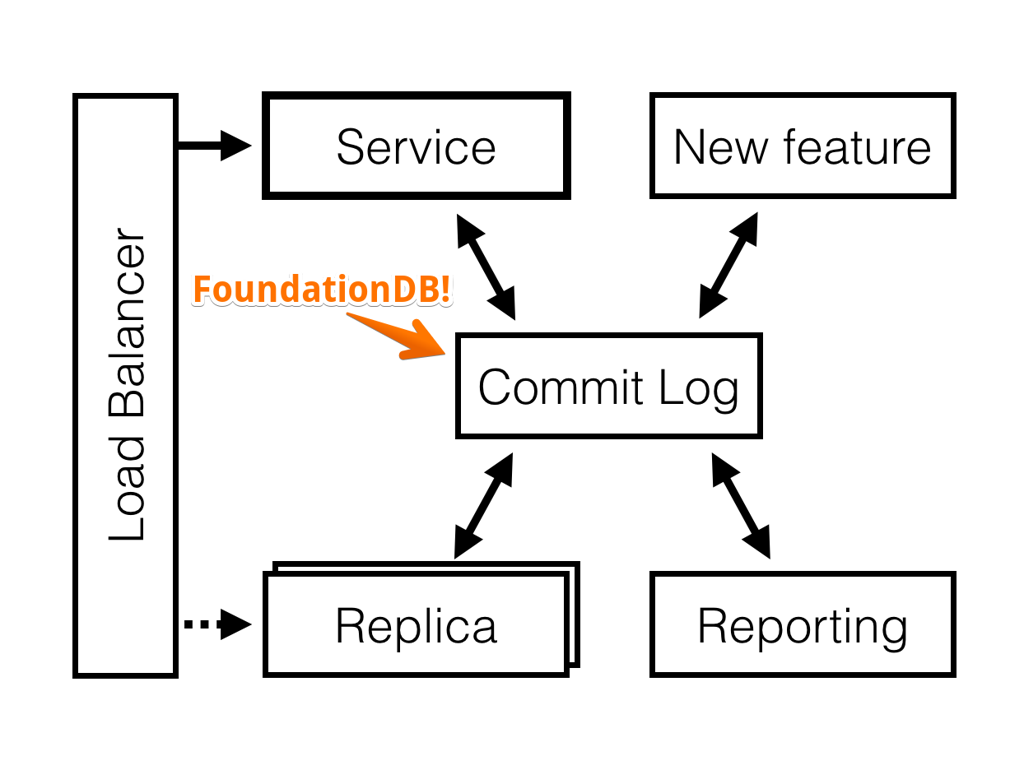
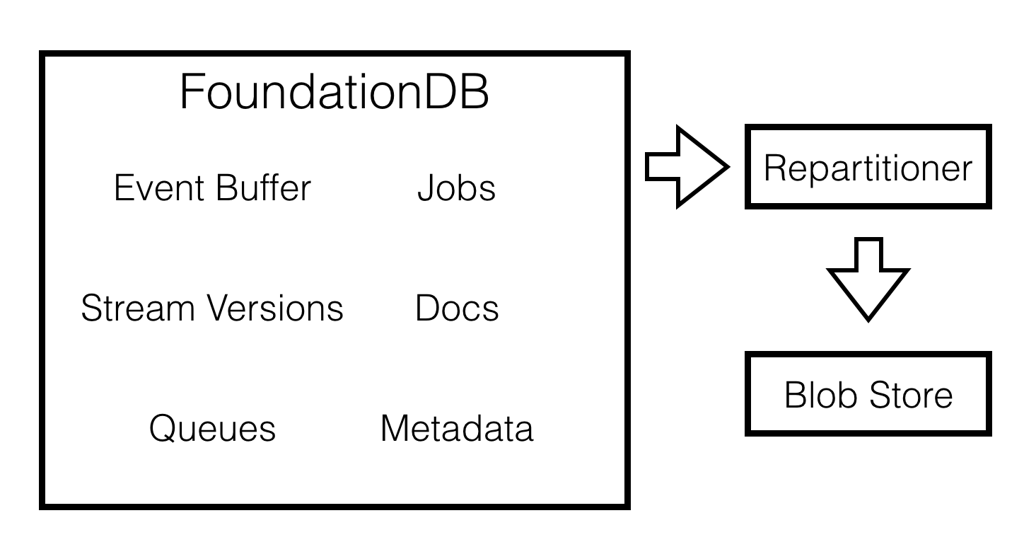
Commit Log Layer
Initially SkuVault V2 was designed to run on top of a MessageVault - a custom highly-available hybrid between Kafka and EventStore, designed to run on top of Windows Azure Storage. We referred to it as the Distributed Commit Log.
Distributed Commit Log at SkuVault holds 1.5B events spanning 400GB of data and growing. It is split into 4 partitions and a few thousand event streams (stream per customer). Some streams have 10M events and more.
That implementation was good enough to let the development move forward.
Further on it became apparent that we wanted better throughput, predictable and low tail latencies. It was hard to achieve while writing to Azure Storage. Commits that took a few seconds were fairly common.

We also needed some kind of stream version locking while doing commits. Otherwise nodes had a slim chance of violating aggregate invariants during fail-over.
Version Locking is similar to how aggregate invariants are preserved in classical event sourcing with aggregates. When any node attempts to commit an event, we want to ensure that it used the latest version of the view state in decision making (view state is derived by subscribing to the events).
FoundationDB felt like the only option that would let us implement these features fairly quickly.
It worked as planned. Given the green light, I was able to implement the first version of the new Commit Log Layer for FDB a few days. In comparison, it took a few months to implement the initial Message Vault.
Layer implementation was simple. We designated a subspace to act as a highly available buffer to which nodes would commit their events. Key tuples included a stream id and UUID (that was also a lexicographically ordered timestamp when persisted) which ensured that:
- there would be no transaction conflicts between the different nodes, allowing high commit throughput;
- events would be ordered within the stream (and somewhat ordered globally).
Another subspace acted as a stream version map. Commit Log Layer took care of consulting with it while performing a commit. If node acted on stale data, there would be a conflict, forcing the application to back off, get the latest events and retry the operation again.
Both the commit and version check were a part of the same transaction, ensuring the atomicity of the entire operation.
There was also a background repartitioner process that was responsible for downloading messages from the buffer in bulk and pushing them to the blob storage.
Performance picture improved noticeably as well:
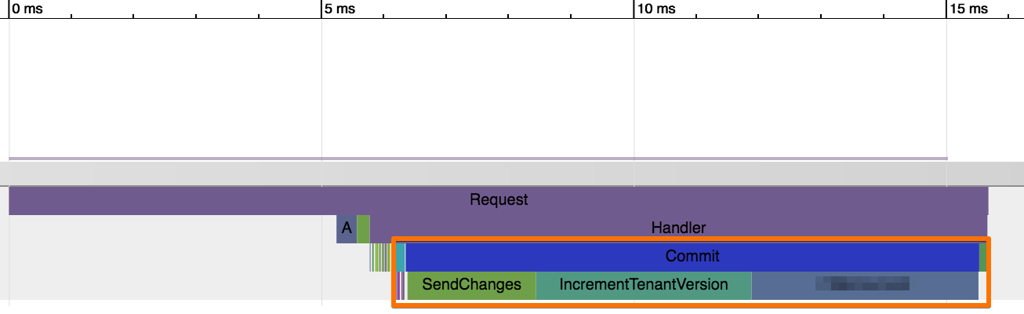
Were I challenged to improve this layer, I'd use newly introduced versionstamps instead of UUIDs (for the global order). Write contention within a stream could also be reduced by bringing the concept of conflict ranges into the application code.
Queue Layer
Given the new Commit Log implementation, server-side logic became fast. Commit latencies were low and predictable.
However, occasionally, the server would just block for a long time doing nothing. This often happened when we had to dispatch a message to Azure Queues. The tracing picture looked like this:
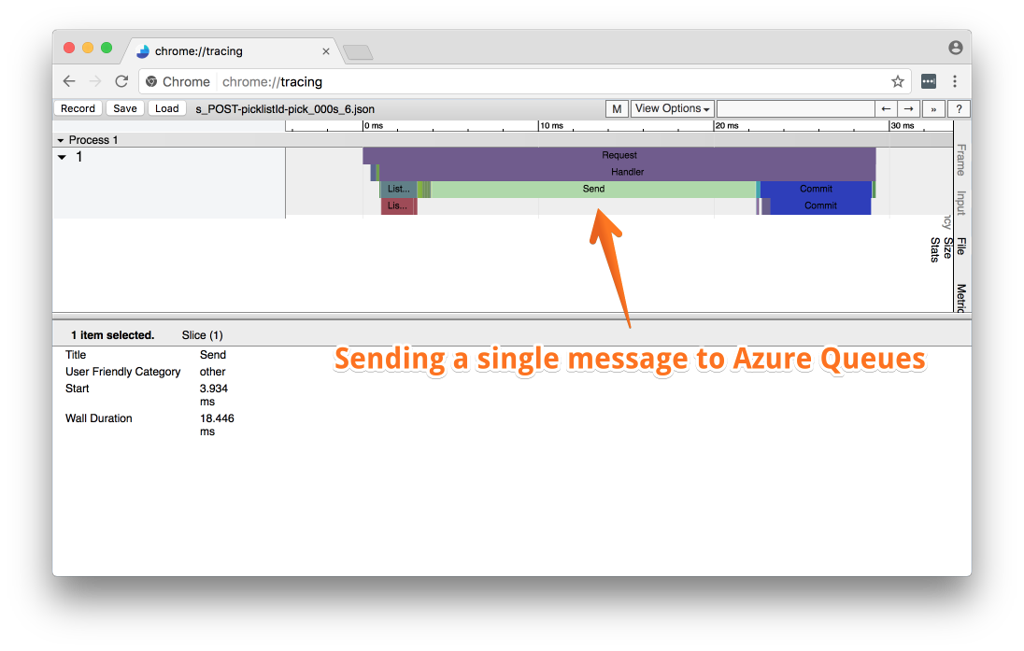
20ms delays were common, however we saw occasional queuing operations that blocked everything for a second or two.
Given an existing FoundationDB setup, it was trivial to add a Queue Layer that would allow us to push messages in the same transaction with the events. Tenant version checks were improved along the way (switched to async mode) leading to a prettier performance profile:
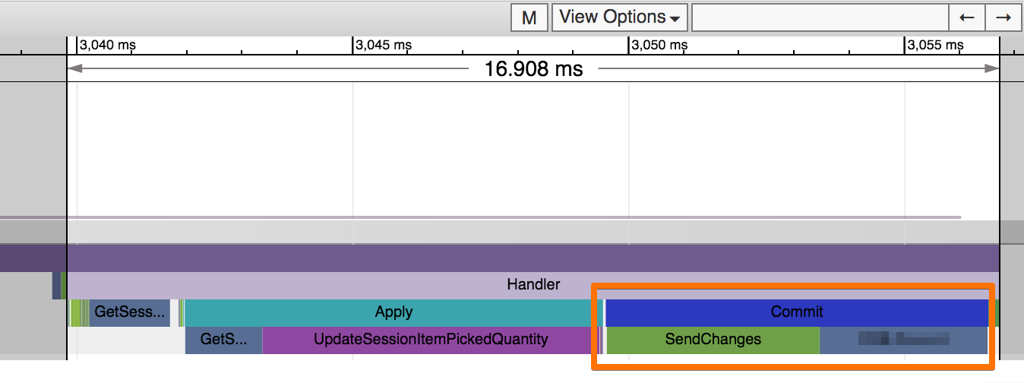
Messages would still be forwarded to a Azure Queues, but that was a side process, operating in bulk.
Miscellaneous Layers
Eventually a few more application-specific layers were implemented:
- Cluster Jobs - to schedule jobs for the background workers.
- Settings and CRUD Storage - to persist metadata and documents that don't need event sourcing.
- Async Request Processing - for the cases when a client wants to process a lot of request in bulk, caring only about throughput.
Application logic can chain changes to all these layers in the same transaction, making sure that all operations either succeed or fail together.
In the end we had half a dozen of various application-specific data models living on the same FoundationDB cluster. All that - without introducing and maintaining a bunch of distinct servers.
Cluster Simulation
API of the FoundationDB is quite similar to the one of Lightning Memory-Mapped Database (LMDB). Both operate with key-value ranges where keys are sorted lexicographically. Both support true ACID transactions.
The difference:
- FoundationDB is a distributed database used to coordinate the cluster;
- LMDB is an in-process database with a single writer, used to persist node data.
This synergy allowed us to leverage FoundationDB layer modeling principles and primitives while working to the LMDB databases.
That was even before we started using FDB! Later all that experience made us feel right at home while working with FoundationDB itself.
We were also able to use LMDB to simulate FoundationDB cluster for the purposes of local development and testing. The last part was particularly amazing.
You could literally launch an entire SkuVault V2 cluster in a single process! Nodes would still use all these FDB Layers to communicate with one another, background repartitioner would still run, jobs would still be dispatched. Except, in that case all the layers would work against LMDB.
This meant that you could at bring up the debugger, freezing the entire "cluster" at any point, then start poking around the memory and stored state of any node or process. How amazing is that?!
This capability was later reused in SkuVault demo mode, which is a special deployment type that creates new accounts on-demand, wiping the data after some time. We packed the entire V2 backend cluster into a single process and instructed it to restart and wipe all data when requested.
By the way, if you are interested in this kind of engineering and live in Louisville, KY (or are willing to relocate), SkuVault is hiring.
Done Anything Different?
Would I have done anything differently at SkuVault? Yes, I'd make a better use of FoundationDB.
- Use FoundationDB to split event blobs into chunks and store the metadata, making it easier to operate event stores at the terabyte scale. This would also simplify event versioning and GDPR compliance.
- Switch event pub-sub mechanism from blob polling to watches, reducing event delivery latency.
- Switch aggregate version locking from a single version number to aggregate conflict ranges (just like FoundationDB does it internally), increasing write throughput to large aggregates.
- Embrace the synergy between LMDB and FoundationDB, making sure that internal tools (debugging, dumps, REPL, code generation DSL) can target both from the start.
- Double down onto deterministic simulation testing, making it easier to learn, debug and develop fault-tolerant application logic.
Epilogue
All the way through the development process at SkuVault, FoundationDB was an invaluable asset. SysOps team particularly liked it - they never had to touch the production cluster. The cluster required zero maintenance during the Black Friday load (barely breaking a sweat under the load) or when Microsoft started pushing Meltdown and Spectre patches across the cloud.
I'm overjoyed that this outstanding database is now open-source and available to everybody.
Published: April 23, 2018.
🤗 Check out my newsletter! It is about building products with ChatGPT and LLMs: latest news, technical insights and my journey. Check out it out