Message Vault
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
This week with SkuVault was 10 hours long, like the previous one. It was purely dedicated to long-term design evolution.
After going through a series of scenarios we ended up with the following plan:
- Introduce Message Vault - a simple pub/sub message streaming systems for Windows Azure.
- Make all existing modules publish events to Message Vault.
- Extract some projection code from the existing SkuVault code and
move them into simple modules with API on top:
Search,Reports,ProductViewsetc. Cover these modules with use-cases. - One by one, start migrating aggregate logic from existing SkuVault codebase to the new design. Remove commands and simplify aggregates, where appropriate.
Implementing Message Vault is the biggest step here. All the other steps are going to be smaller and more incremental.
Message Vault
Message vault provides publish-subscribe with replay and batching for Windows Azure.
It is heavily inspired by Apache Kafka. However, it is going to be a lot more simple than that. We are going to simply add a thin wrapper around Azure Blob Storage, to act as an API and write synchronization point. Windows Azure is going to do all the heavy-lifting.
We need to embrace Windows Azure in order to keep the implementation simple, yet scalable.
At the moment of writing, SkuVault stores more than 100000000 events with total size above 25GB.
Semantics are going to be similar to Apache Kafka (this way we could migrate to Apache Kafka or any other implementation of a distributed commit log, if needed). Producers push messages to the Vault which serves them to consumers. Consumers can replay events from any point in time or chase the tail.
We partition messages by streams. Each stream is an immutable and ordered sequence of messages. All messages in a stream get a unique offset and timestamp. Absolute order between messages in different streams is not guaranteed, but we can still sort by timestamps (within the time drift on Azure).
Message Vault is not going to be an Event Store, it is not designed for event sourcing with aggregates" (you need NEventStore or EventStore for that).
Design Trade-offs
Message Vault makes following trade-offs:
- optimize for high throughput over low latency;
- optimize for message streams which are gigabytes large;
- prefer code simplicity over complex performance optimizations;
- http protocol instead of binary protocol;
- rely on Windows Azure to do all the heavy-lifting (this simplifies code, but couples implementation to Azure);
- high-availability via master-slave setup (uptime limited by Azure uptime, no writes during failover);
- no channel encryption (if needed, use SSL with Azure Load Balancer or your load balancer);
- no authorization schemes (if needed, configure your load balancer or add a proxy on top);
- implemented in imperative C# (.NET runtime is heavy, but Windows Azure optimizes for it);
- client library is intentionally simple (view projections and even checkpoints are outside the scope);
- each stream is a sepate page blob (they can grow to 1TB out-of-the-box, having thousands of streams isn't a good idea).
Implementation
Implementation should be rather straightforward, since we brutally optimize the implementation for the task at hand (SkuVault project itself). We allocated 20 hours for that.
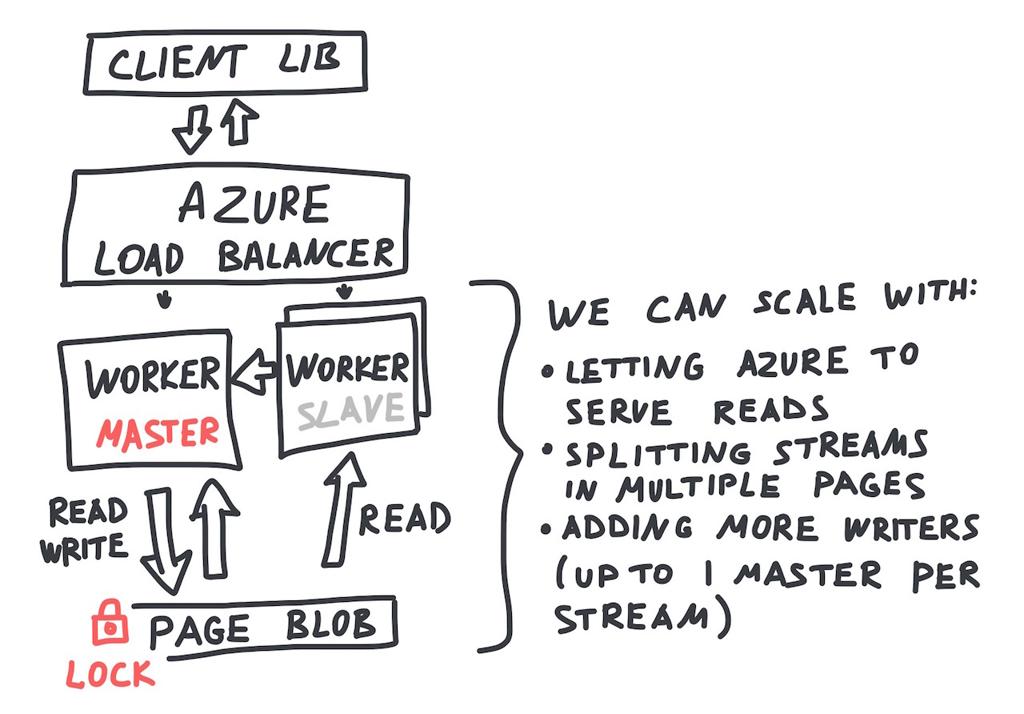
The most tricky part is going to be: write and test master-slave failover (we need high availability) and handling writes between the moment the master goes down and moment, when azure lock expires.
By the way, awesome folks from AgileHarbor (company behind the SkuVault) agreed to make the project open-source under the New BSD license. The project will be hosted on github.
New BSD License (or _3-clause BSD_) allows you almost unlimited freedom with the code as long as you include the copyright notice. You don't need to share your code. You cannot use the names of the original company or its members to endorse derived products.
Evolution
Once we have MessageVault in place, we could start extracting some view-based logic into new modules. This will help us:
- we reduce complexity of existing codebase;
- new modules are designed for new performance requirements, take off the load from the existing codebase;
- new modules (at least the ones with pure denormalization logic) are going to be brutally simple.
Eventually, we are planning to have SkuVault composed from the modules like this one:
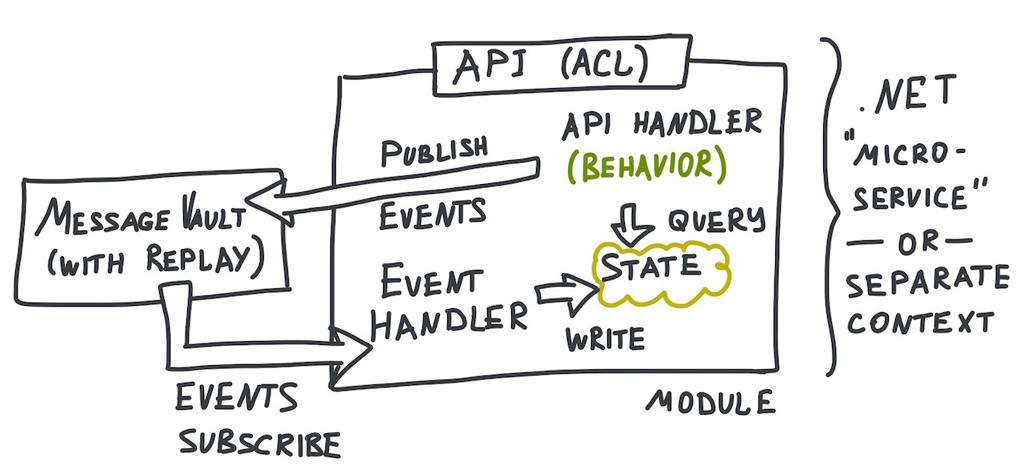
In essence, this is an application of "event-driven micro-services" paradigm to .NET environment.
SkuVault C# modules are probably going to be "larger" than equivalents in erlang or golang. That is because C# .NET ecosystem is shaped by enterprise mindset. As a side-effect, everything tends to be bigger on .NET: libraries, classes, variable names and build times.
Published: December 07, 2014.
Next post in SkuVault story: Delivering First Bits to QA
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.