High Availability and Performance
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
This is a summary of interesting things we've achieved at SkuVault since the previous blog post on LMDB and emerging DSL.
Current stats are:
1.43Bevents with the total size of316.3GB. ~450 event types.
System Architecture
System architecture didn't change much since the last update. However, we improved our ability to reason and communicate about it.
Let's go quickly through.
The core building block of the system is something we call a service. It has a public API which can handle read and write requests according to the public contract of the service.
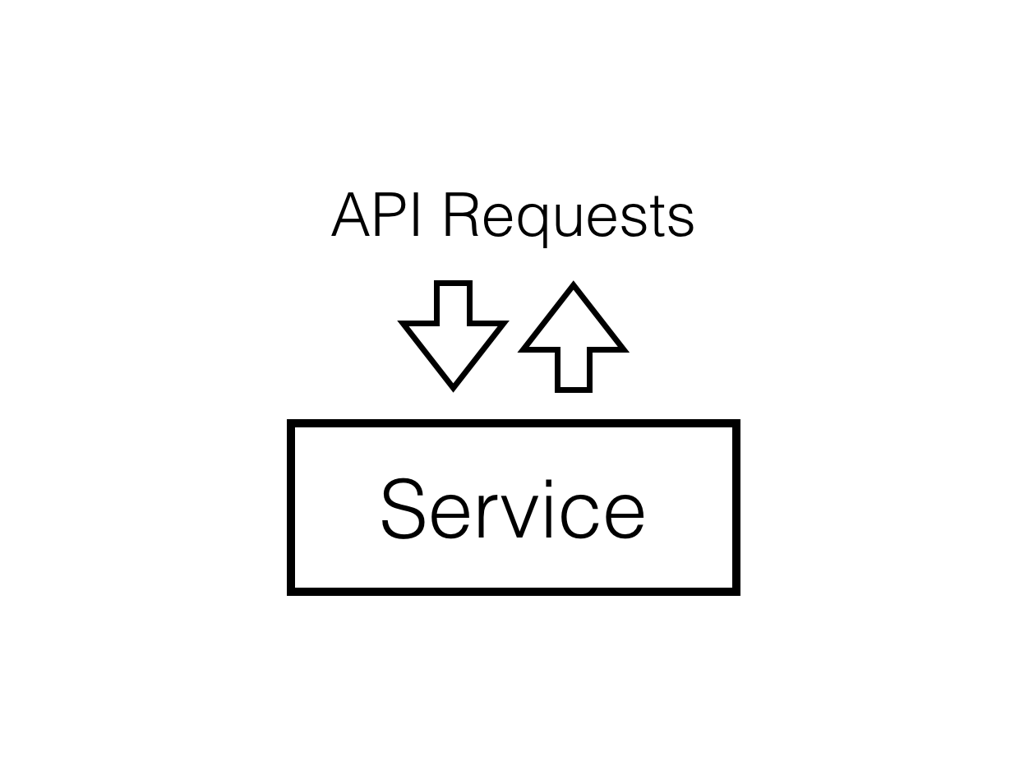
We do an event-driven variation of service-oriented architecture. Whenever a service needs to persist a state change, instead of overwriting DB state with new values, we craft change events and append them to the distributed commit log.
Apache Kafka could work as such distributed commit log. You can also try rolling your own commit log on top of a distributed transactional key-value store (to act as a buffer and a serialization point) and a replicated blob storage.
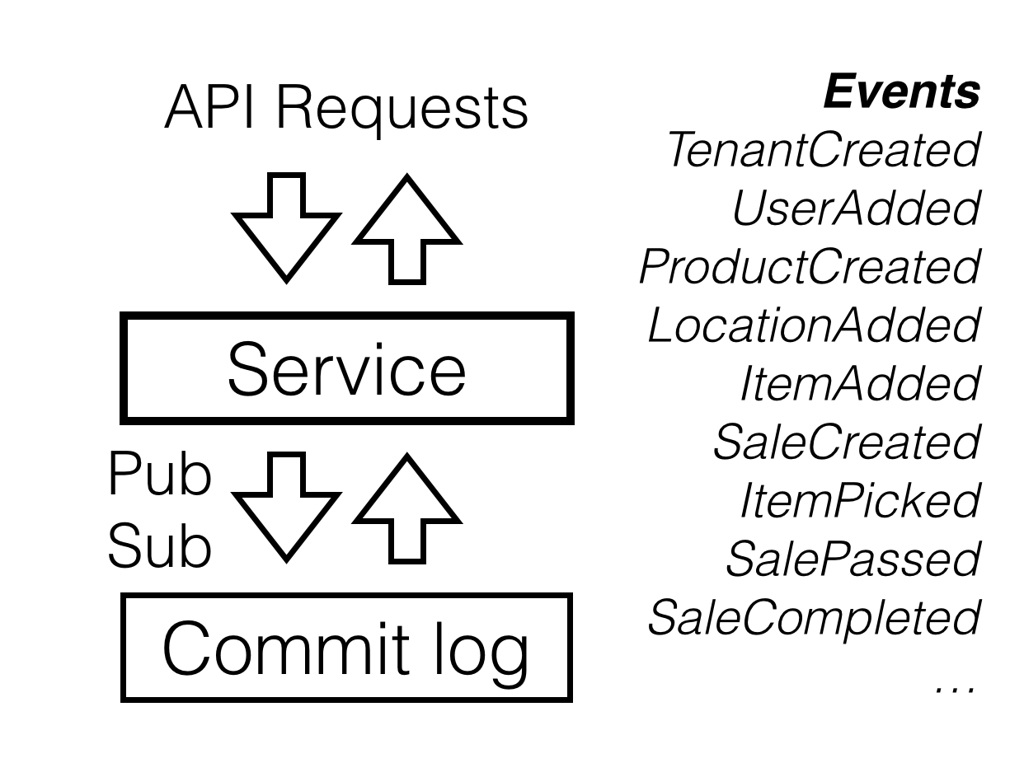
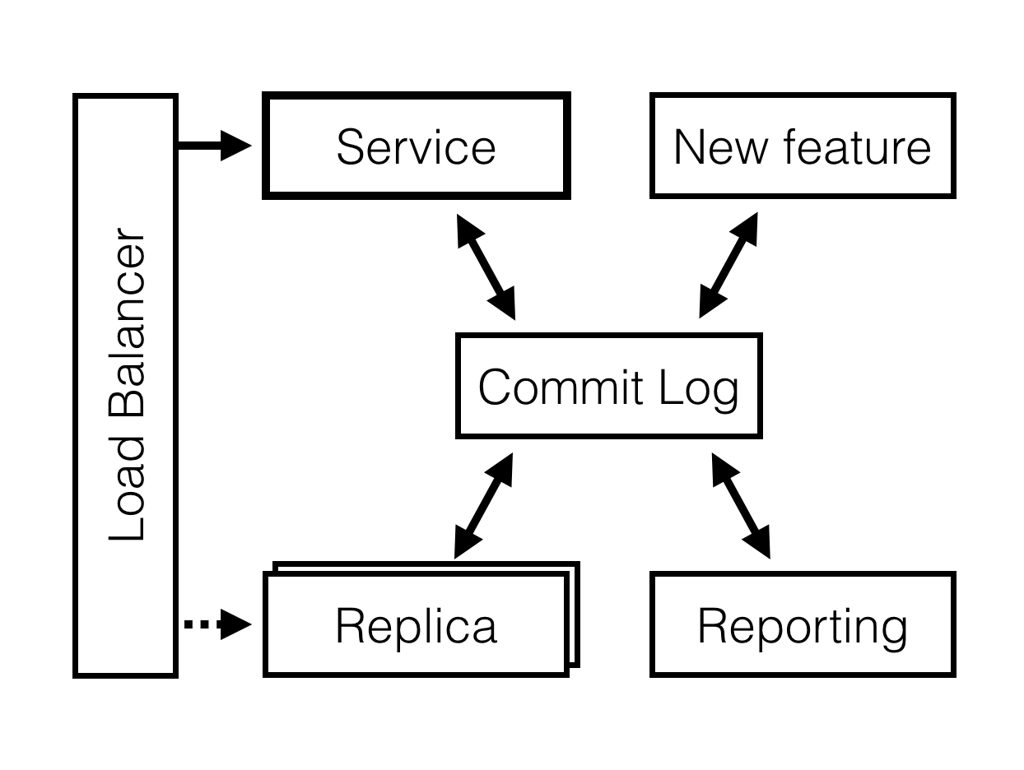
Any interested service could subscribe to this commit log, replay interesting events and get its own version of the state. This state will stay in sync with the global commit log via the subscription mechanism.
This means that you can roll out new service versions, features or even specialized services (e.g. analytics and reporting that have different storage requirements) side-by-side with the existing services.
Further in this blog post you will discover the term
module- it is a monolithic unit of deployment for a group of services that share similar functional, performance and availability characteristics. In other words, it is convenient to deploy, manage and version them together.
You could scale by placing a load balancer in front of a cluster to route different requests to the service instances that are designed to handle it. The same load balancer would allow you to fail over to replica nodes in case of outage or a simple rolling upgrade in the cluster.
This approach also allows multiple teams work together on a large system while building software on different platforms.
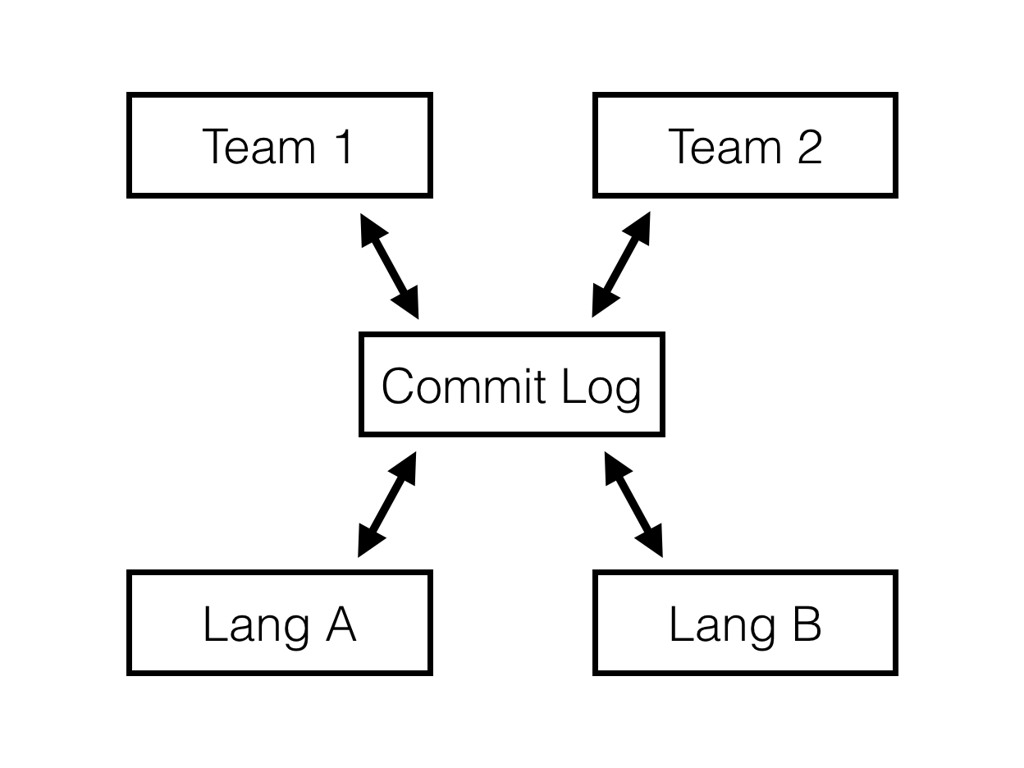
In this environment, the service behavior can be expressed via its interactions with the outside world:
- events it subscribes to;
- API requests it handles;
- API responses it returns
- events it publishes to the commit log.
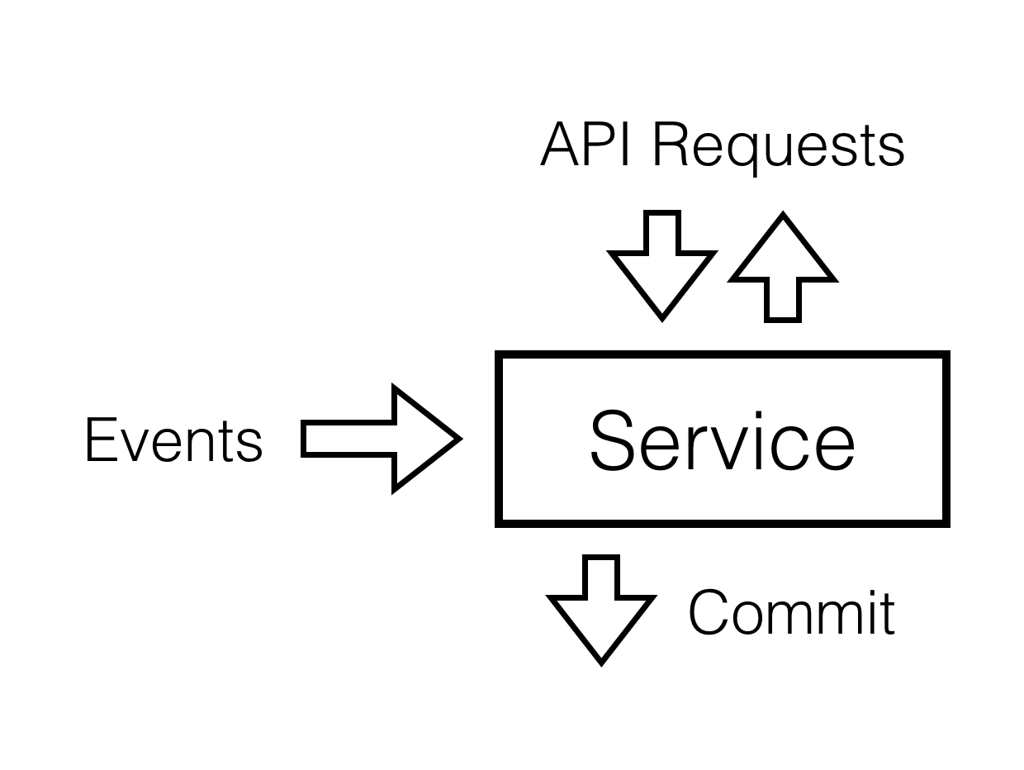
If we somehow were able to capture all important combinations of these interactions of the service, then we'd probably specify its behavior well enough to prevent future regressions.
This is what event-driven specifications are for.

These specifications come with a few potential benefits:
- separate design phase from coding phase (which reduces cognitive burden);
- help you to decompose complex requirements into simple event-driven tests;
- break rarely (see aside);
- let you refactor services by moving around requirements, behaviors and functionality.
In my experience these specifications almost never break. They just keep on being added to the codebase when new requirements and edge cases show on the horizon. This comes with a potential downside: code that never breaks - never gets refactored and cleaned up. So you might end up with specifications written in different flavours.
Imagine, you have a service with some complex functionality inside. This functionality has evolved over time. Service accumulated specifications for the behavior, weird edge cases and strange regressions that slipped through.
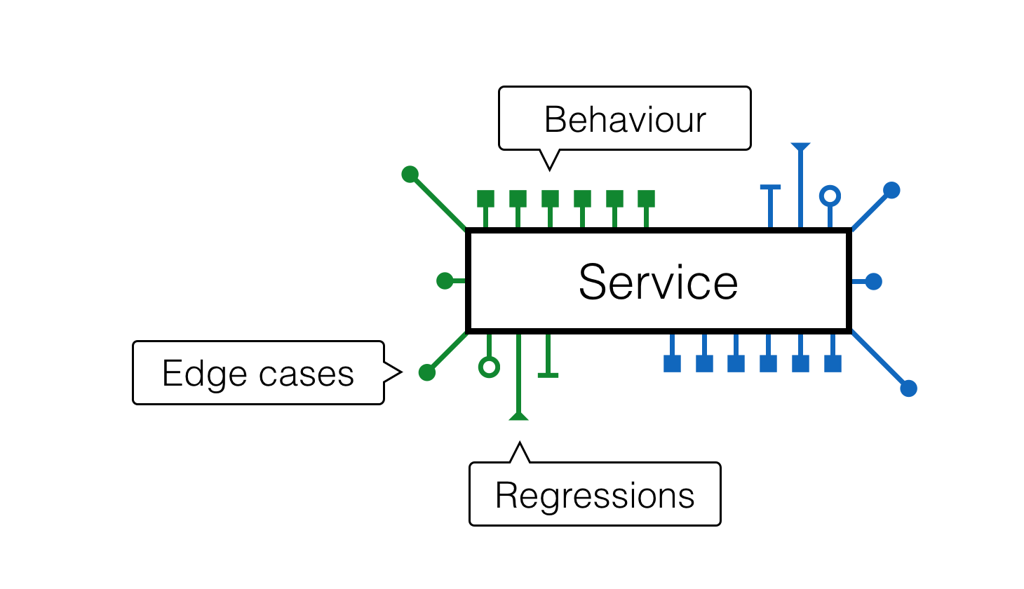
Over the time, it became apparent that this service implementation houses two distinct feature sets. They are currently intertwined but would live better if separated.
What you can do in this situation:
- split specifications for these services into two different groups;
- discard the implementation completely (or keep it as a reference);
- iterate on new versions of the services until all tests pass.
What if there are important behaviors that weren't covered by the scenarios? This is very good - thanks to this refactoring exercise you've just discovered gaps in your test suite.
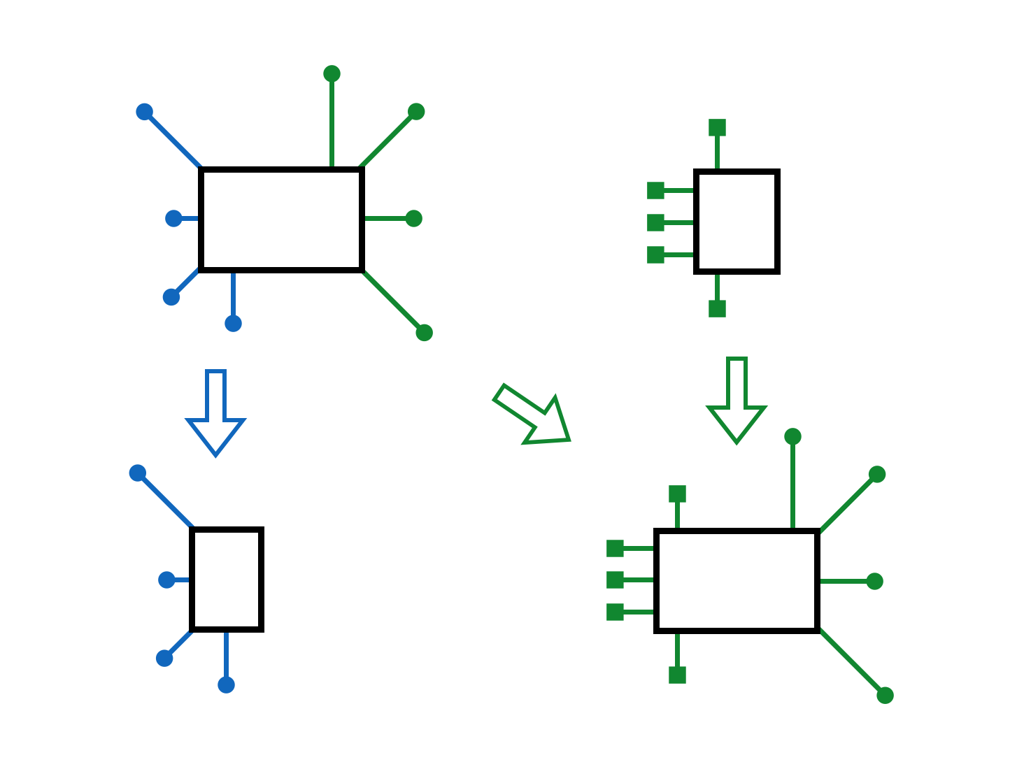
Throwing out the implementation logic and rewriting services from scratch might be scary. In practice it is a bit simpler and safer than it looks like:
- these event-driven specifications capture all important design decisions and service interactions (including edge cases and error responses);
- developers can focus on one specification at a time, iterating till all specs pass.
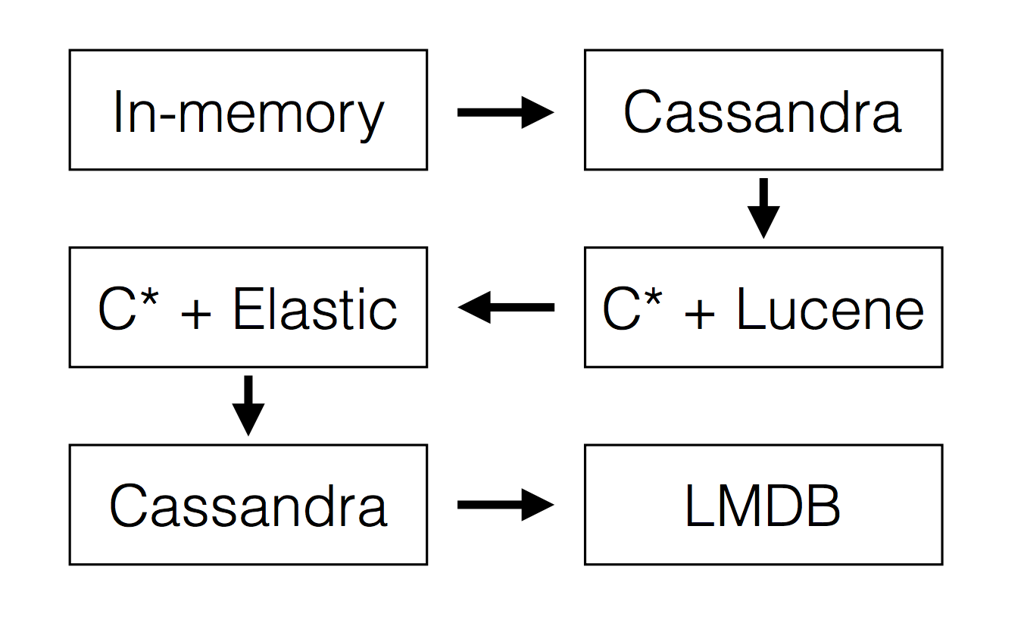
These specifications are the reason why SkuVault V2 backend was able to evolve through multiple storage backends till it arrived to a place we are quite happy with: LMDB.
Cassandra to LMDB
At this moment we completely migrated away from Cassandra to an embedded LMDB as a data store. Outcomes: better (and more predictable) performance, reduced DevOps load and simpler scalability model.
This also means that:
- We have to write our own application-specific data manipulation layer, which would've been difficult without lisp DSL and code generation.
- Our reads are served from memory (best case) or local SSD (worst case). This simplifies scenarios like route generation for wavepicking algorythm or running complex search filters - you have to worry less about the performance.
This also means that our operations are currently mostly IO-bound, while CPU is under-utilized. Were we to switch API from JSON to binary format, while also compressing event chunks, then CPU would become the next bottleneck.
For now, event replay speeds on smallish nodes look like this:
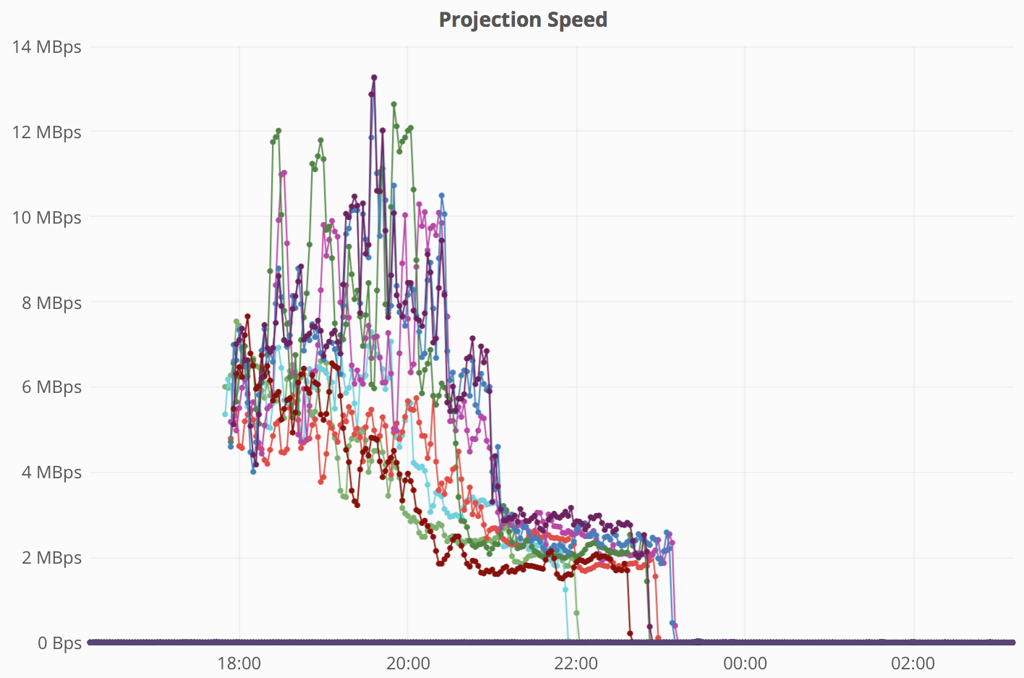
Replay is the process of downloading relevant event chunks from the commit log, getting interesting events and dispatching them to local handlers in order to rebuild node state. We tend to do that on every new deployment.
This is the last step in our journey from one storage engine to another. It looks like we'll stay here for some time.
Idempotency didn't work out
Exactly-once delivery of messages or events in a distributed system is hard. Initially we've tried to work around this problem by enforcing idempotency in the code via auto-generated scenarios.
You take an ordinary Given-When-Then scenario and mutate it by duplicating one event at a time. If the scenario produces the same result, then the affected code paths are idempotent.
However, as it turned out, it can be hard or plain impossible to implement idempotent event handlers in some cases. Especially, when you have to deal with events coming from the legacy code.
So we are planning to push this deduplication concern into the subscription infrastructure. It could handle deduplication automatically by checking up on known message IDs before passing messages to handlers. New IDs could then be pushed into LMDB within the same transaction in which handlers are executed.
This would also solve an edge case when a node crashes after pushing event to the commit log but before writing down acknowledgement from it.
Edge case looks like this. Imagine that
node-1produces anevent-Aand pushes it to the distributed commit log. However, beforeACKcomes back, the node crashes. System will fail over to the replicanode-2and continue working there. Later, whennode-1comes back online, it will receive the sameevent-Afrom the commit log, ignoring it - the event is stamped withnode-1identity (so it is supposed to already be in the local state).
Cluster Simulation
At the moment of writing, V2 part of SkuVault backend has 3 different types of modules: public (serving web UI), internal (serving legacy systems) and export (handles export jobs). Each module has a couple of replicas. Public module also has 4 partitions (each with a replica).
These modules collaborate with each other via our cluster infrastructure:
- distributed key-value store acting as event buffer, tenant version dictionary and a queue;
- replicated commit log;
- forwarder process - single writer responsible for pushing events from the buffer into the replicated commit log.
Options for such a distributed key-value store are: Google Spanner, VoltDB, CockroachDB and MarkLogic.
Existing cluster infrastructure works fine for development, qa and production purposes. It requires some setup, though.
We needed another way to run the entire cluster locally with zero deployment. That's when we finally started tapping into the simulation mode:
- replaced the distributed key-value store with local LMDB implementation, while keeping all cluster-enabling logic intact;
- replaced the azure-locked version of the commit log with the file-based simulation;
- launched all modules in one process in this simulated environment that works very similarly to the production setup (there are some caveats, of course).
While it is possible to reason about behavior of the distributed system in some edge cases, seeing it happen under the debugger with your own eyes is much better. It helps to reproduce and fix infrastructure-related bugs, while building an intuitive understanding of the system behavior.
A first edge case that was reproduced locally - behavior of the system, when cluster fails from a node-A to a node-B that isn't fully up-to-date yet (e.g. it could be in another datacenter). And this happens while a user edits a version-sensitive entity. In that case UI negotiated with the new node to postpone the edit until the node received all the relevant events.
Besides, having a simulated local cluster works well for demo deployments, where you regularly wipe everything and restart from a preset state. It is also a prerequisite for on-premises deployments that can sync up with the remote data-center or fail over to it.
Note, that this isn't yet a deterministic simulation that can be used to test distributed systems. It is merely the first step in this direction.
Missing bits include:
- bringing all event handling loops to run on a single thread (for determinism and ability to rewind time forward);
- simulating transaction conflicts in the cluster infrastructure (current LMDB implementation never conflicts - it takes write lock);
- simulating load balancing, its error handling and fail overs;
- injecting faults and adding code buggification in the simulation layer and above;
- running this setup for a couple of months.
If you are interested in this kind of setup, check out things like: Discrete event simulation, The Verification of a Distributed System and especially Testing Distributed Systems w/ Deterministic Simulation.
Why Does Deterministic Simulation Matter?
Let's imagine we are building some distributed system that deals with business workflows across multiple machines. It might deal with financial transfers or resource allocation. Let's also assert that bugs in this system are very expensive.
In theory, implementing that distributed logic shouldn't be a challenging task. We either have a cluster with distributed transactions or implement a saga (I'm oversimplifying the situation, of course). We can even prepare for the problems by planning compensating actions at every stage (and covering this logic with unit and integration tests).
To be even more rigorous, we can even have multiple teams implement the same system on different platforms. These implementations would then double-check each other.
In practice, how do you know that this implementation would actually work out in real world? How would it deal with misconfigured routers, failing hardware or CPU bugs? What if network packets arrive out of order, double-bit flips happen or disk controller corrupts data?
Remember, we've said that bugs in this distributed system are very expensive.
Studies by IBM in the 1990s suggest that computers typically experience about one cosmic-ray-induced error per 256 megabytes of RAM per month.
This is where deterministic simulation comes into play. If you design your system to run in a virtual environment that is deterministic, simulates all external communications and runs all concurrent processes on a single thread (pseudo-concurrency), then you can get a fair chance of:
- fuzz-testing random problems and reactions or your system to them;
- injecting additional faults and timeouts for extra robustness;
- being able to reproduce any discovered failure, debug and fix it.
In essence, this approach is about upfront design of the distributed system for testability and determinism. It allows to throw more machines at the problem of exploring the problem space for costly edge cases, giving us a chance to build a system that is better prepared for random failures the universe might throw at us in real life.
Zero-downtime Deployments
No much to say here. You throw a couple of load-balancers in front of your nodes, telling them how to route traffic and fail over. With that, a deployment turns into a process:
- spin up new node instances and let them warm-up local state (if needed);
- switch LB forward to the new version for a portion of the users (ssh, swap config and do nginx reload);
- if all goes well - switch more users forward;
- if things go bad - switch users back.
Switch takes only a few seconds, since we don't have long-running requests that need to be drained.
We are currently using nginx as the load balancer. However I see lyft/envoy as a promising replacement with a better high-availability story.
Single-Writer Caveat
The system is designed to have a single writer per process. This design decision lets us benefit from LMDB and its ability to have unlimited isolated reads in parallel.
Read throughput is usually limited by the network IO in our case - services process incoming requests faster than they can arrive to the network card. There are some exceptions where CPU, memory and disk IO are the bottleneck; for example: routing and complex filtering which require deep graph-like traversal of persisted state.
The caveat is: write requests have to be optimized for low latency (taking more than 15-50ms per write is too much). At the same time, we have a lot to do within a write:
- check local state to ensure that the write request is valid;
- generate a new event (or a couple of them);
- apply this event to the local state;
- commit events, jobs and any other messages to the cluster
- generate a response to the user (e.g. include newly generated IDs or totals).
As it turns out, it isn't very hard to profile performance and improve. For that we hijacked Google Chrome tracing tools.
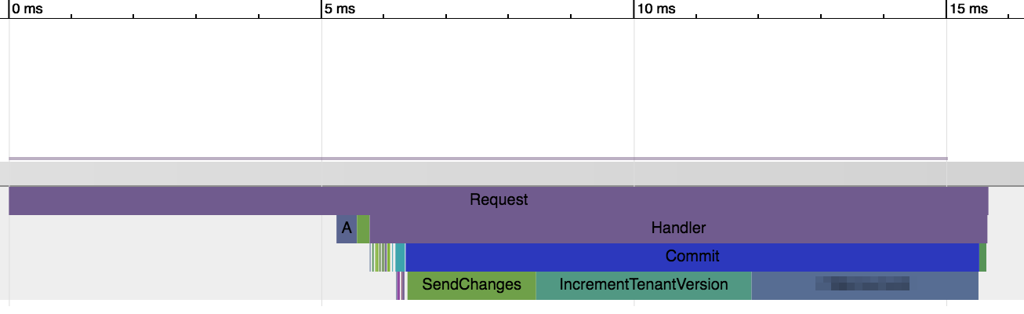
We simply collect method call timings in memory (it helps that most of the code is auto-generated) and render them in Trace event format which could be opened with
chrome://tracing. We've also added passive sampling to the servers - they will try to capture and store traces of potentially interesting requests.
Note: for some important requests we also check with the cluster to ensure that the node has the latest version of relevant event stream. This adds a network round-trip to the commit cost.
If we find the need to increase write throughput of the system, there are a few options:
- split the system into more partitions (since single writer limitation is per partition); a single machine could handle multiple partitions;
- move heavy reads to read-only replicas;
- trade off some latency for throughput by batching multiple writes together;
- migrate from Windows to Linux/Unix with optimized network and IO;
- switch from virtual machines to the dedicated hardware;
- move from .NET C# to golang (or even lower).
The only memorable lesson during these optimizations was: don't use services provided by some cloud vendors, if you value consistently low latency. These services tend to value overall throughput for all customers over consistently low latency for one customer (which makes sense).
Next Problems
Below is the list of the problems that lie ahead for the project.
You might find these problems a little bit less exciting than simulating cluster or running hundreds of full-stack tests per second. This is probably due to the fact that the technical design is established for this project, important challenges are mapped. Further scaling would mostly take place in the realm of people, teams and organization.
Development Processes and Training
Initial development processes were quite flexible. This was possible thanks to the small size of the team: we just went to the office kitchen and drew on the whiteboard till consensus emerged.
As new developers come to the project (including developers from the remote locations), it has to switch to a more formal development model. Training process, methodology and materials also have to be established.
Client libraries and DSL
Code generation of client libraries (along with the API) will speed up development inside the company, while simplifying integration story for the partners and customers.
It will save API consumers from doing double work and re-implementing half of the domain validation logic in their own language. Besides, shipping client libraries with a nice interface would save us the effort of precisely documenting our API along with intricacies of the transport layer, fail-over, back-off, authorization and version management.
A client library would let us switch from JSON API to something more performant (e.g. GRPC with HTTP/2) without customers investing any development effort (aside from updating dependencies).
Cluster Management and Visualization
Imagine a clustered system with 3-4 types of the modules, where:
- each module has a different deployment profile (e.g. one scales by partitioning, another - by running multiple replicas, third - by adding more queue consumers);
- each module can have multiple versions running on the cluster (some versions could be enabled, others disabled, some more - partially rolled out);
- some modules could be in warm-up state (replaying commit log to build their local state);
- there could be additional deployments of modules used to test or demo new features (currently incompatible with the rest of the cluster);
- in order to save resources, multiple module instances could be crammed into a single VM (as long as doing that doesn't hurt high availability).
This situation might look like a mess. It definitely can confuse project managers, stakeholders, testers and even developers. Confusion can lead to mistakes, anger and the dark side. We don't want that.
One way to remedy the situation is to visualize cluster state for people and provide tooling to manage this state, while enforcing domain-specific rules.
Fortunately, all this is simple to achieve with some diagnostic endpoints, shell scripts and d3.js.
For example:
- never remove the last active node from the load balancer;
- never add a stale node to the load balancer;
- keep partition replicas on different machines;
- ensure replication factor of 3 for VIP replicas.
Summary
This design isn't doing anything particularly novel. We are essentially building application-specific database engine tuned for the challenges and constraints of the domain. Event sourcing and Domain-Driven Design are used as higher-level design techniques that let as align "what people want to achieve" with "what computers are capable of" in an efficient way.
In more concrete terms, the current solution:
- solves existing scalability problems and provides foundation for solving future challenges, should the business experience rapid growth;
- lays groundwork for bringing in new developers, training them and organizing multi-team collaboration around the core product, services and add-ons;
- maps a way to tackle complexity in the software, while adding new features (including some that are unique for this industry) and maintaining them through implementation rewrites.
Published: July 14, 2017.
Next post in SkuVault story: Black Friday Boring
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.