Emerging DSL
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
This is a quick update on the progress of our migration from Cassandra to LMDB (initial plan outlined in previous blog post).
Fast Tests
We started by rewriting one of secondary systems from event-driven Cassandra to event-driven LMDB design. We kept all the tests and API contracts, everything else was rewritten by a team member in a week or two.
This system is read-heavy with a short burst of writes on event replay, when it builds local read models. At this point it needs to replay of 100M events taking 50GiB. Cassandra implementation took 10 hours, LMDB does it in 2-3 without any serialization optimizations.
Here are immediate observations:
- Cassandra implementation used to run our tests (they verify behavior of the entire system at the API level) at the speed of 1 test per second. LMDB tests currently run at the speed of 950 per second on the same laptop.
- Since all ~700 tests now run in a second, we enabled test auto-generation by default. This added 2200 tests, and improved edge case coverage at the cost of 3 more seconds.
- Cassandra and LMDB data access patterns tend to be similar (despite the obvious differences between the databases). Structure of the keys and values stays roughly the same. This made migration straightforward most of the time.
Screenshots are from my own development laptop, which runs Windows in a separate VM and gives it only two hardware threads out of 4 available. Benchmark laptop has 8 of them and runs Windows directly.
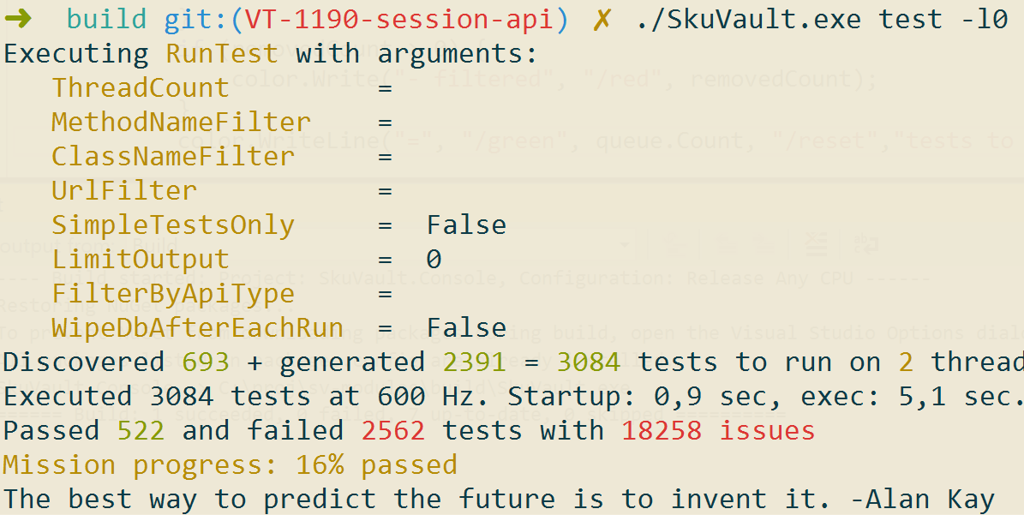
We achieved high test throughput with two trivial things: switching LMDB to async flushing and creating a database per thread.
High availability
LMDB is an embedded transactional database (unlike Cassandra which is a replicated eventually consistent data storage). Transactions make life better, but in exchange we need to deal with high availability and fail-over. This will come via:
- Partitioning nodes by tenants.
- Running multiple replicas of a partition behind a load balancer (we could pick which partitions are replicated and how). Nginx can easily handle routing and failover in this scenario.
- Having secondary hot replicas in a different data center. If the primary datacenter goes down, we could switch to the secondary by updating DNS records (good enough for now).
This is the hard part. Fortunately, we can make some business-specific trade-offs and simplify the overall design considerably:
- write-side could survive 1-5 seconds of downtime (especially, if API clients can queue up work) as long as it is consistent;
- read-side could lag behind up to 5 seconds as long it is always available, transactionally consistent with version numbers and fast.
Emerging design
While porting system to LMDB we agreed to start by writing everything by hand. FoundationDB client libraries made our life simpler, but still required some manual byte wrangling.
public void When(Tx tx, StatusRenamed e) {
var oldKey = FdbTuple.Create(
ModuleTables.StatusByName,
e.RefInfo.TenantId.Id,
GetCorrectKey(e.OriginalName.Name)).ToSlice().GetBytes();
try {
tx.Delete(oldKey);
}
catch (Exception) {}
var newKey = FdbTuple.Create(
ModuleTables.StatusByName,
e.RefInfo.TenantId.Id,
GetCorrectKey(e.NewName.Name)).ToSlice().GetBytes();
tx.Put(newKey, BitConverter.GetBytes(e.Id.Id));
}
After a week of work we reviewed the system and identified emerging patterns. Instead of writing a data access library to made them simpler (that would've involved some reflection and complex performance optimizations), we just plugged in a simple codegenerator which replaced 30-40% of the code with the generated stuff.
We wanted this new code to be boringly simple and things turned out well.
Given these DSL definitions from the single schema file:
(space "StatusByName"
[tenant/id status/name]
[status/id]
(put "AddStatusName")
(del "DeleteStatusName")
(fetch "GetStatusIdByName"))
Developers would have boring LMDB access methods generated for them.
public void When(Tx tx, StatusRenamed e) {
var tenantId = e.RefInfo.TenantId.Id;
var statusId = e.Id.Id;
Lmdb.DeleteStatusName(tx, tenantId, GetCorrectKey(e.OriginalName.Name));
var dto = Lmdb.NewStatusByNameDto().SetStatusId(statusId);
Lmdb.AddStatusName(tx, tenantId, GetCorrectKey(e.NewName.Name), dto);
}
These generated methods simply spell out method parameters and pass them in a proper order to byte managing routines.
public static void AddStatusName(Tx tx, long tenantId, string statusName, StatusByNameDto dto) {
var key = DslLib.CreateKey(Tables.StatusByName, tenantId, statusName);
DslLib.Put(tx, key, dto);
}
Dtos are also generated automatically in such a fashion that we could later swap out Protobuf serialization format for values to something more performant without requiring developers to rewrite business logic.
Currently we are evaluating FlatBuffers/Cap'n Proto for storage of complex objects that rarely change. Native multi-value capability of LMDB would work well for frequently changing property groups. Custom bitstream compression is the ultimate goal.
Edge cases
While doing that we agreed to codegen only the cases which were repeating all over the place. Edge cases will have to be written by hand until we get enough of them to see emerging patterns.
Resulting code feels trivial and fast, if compared to the other versions of the same logic. Like a breath of fresh air on a clear and chilly autumn morning in the Hudson valley. This is the goal we are striving for: boring code designed to run fast and scale well for new features. This should ultimately let us create more value for the customers, while making our own days more enjoyable and less stressful.
Linguistic complexity
Technically, the language of the system is more complex - we have two languages instead of one (with a codegen step). Practically, it still feels simpler. Probable reasons for that are:
- our handwritte code uses only a small (good) subset of C#/.NET features. It is just a bunch of static methods that transform data between different reprentations, while being conscious about performance.
- DSL doesn't hold much magic. It is just a bunch of Clojure files doing obvious transformations according to the simple rules. Anybody could rewrite it to another language (e.g. Racket or CommonLisp) in a couple of days.
Side benefits
DSL design forces us to write out type aliases before referencing them in LMDB layer. They spell out types of data (properties) within a linguistic (bounded) context, while aliasing them with short namespaced identifiers and descriptions.
(group "tenant" "tenant-related schemas"
(alias id "Numeric tenant id" positive-long)
(alias name "Tenant name" string not-empty))
(group "user" "User within a tenant"
(alias id "Unique user id" positive-long)
(alias name "User name" string not-empty)
(alias email "User email/login" string not-empty)
(alias role "User role, affects permissions" string not-empty)
(alias password-hash "Password hash" string not-empty)
(alias enabled "Set to false to disable access" bool))
(group "product" "product details"
(alias capped-key "Capped sku/code that fits 200 chars" string (max-len 200))
(alias is-kit "Is this a kit or not" bool)
(alias id "Product id" positive-long)
(alias key-type "Product key type constant" byte))
These aliases can also be associated with data specs, which spell out
how should the data look like. For example, if we know that
product/capped-key will always comply with (max-len 200), then we
don't even need to define types or write argument checks.
These aliases will help in defining consistent APIs with auto-generated documentation. We can also perform consistent argument validation not only in API implementations, but also in client libs in multiple languages.
Generating Swagger definitions (to get beautiful API explorer) and JavaScipt client libraries are the next planned steps in this direction.
Developer onboarding and knowledge transfer
It takes a couple of days to get a first commit from a developer new to LMDB and this DSL (provided that API design and scenarios are already done). It would probably take him 3-4 weeks to get used to writing finely-tuned LMDB code in places, where this matters.
We're planning to add continuous performance testing to shorten the feedback loop and improve productivity in this area.
Rewriting existing DSL from scratch or porting it to a new language is probably a week of effort for a senior developer familiar with Lisps and AST manipulation. There are just 450 lines of code there (mostly with C# code fragments).
Destination - golang
In the long run we plan to migrate the core business logic to golang. The language itself is a good fit for the job: simple, fast and runs natively on Linux. We don't care much about the advanced features from C#, since they are handled by the DSL layer anyway.
DSL design pursues the goal of streamlining migration from C# to golang: generated code doesn't have to be rewritten by hand, only the edge cases.
Published: January 22, 2017.
Next post in SkuVault story: High Availability and Performance
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.