FoundationDB is Back!
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
I'm very excited today - Apple has just open-sourced FoundationDB.
What is FoundationDB?
FoundationDB is a distributed scalable transactional (ACID) key-value database with crazy thorough testing. It was so good that three years ago the entire company was bought by the Apple and shut down. Despite that unfortunate fact, FDB was still used as an unsupported product in companies like:
- Snowflake - Data warehouse for the cloud. They say that FoundationDB "is a key part of our architecture and has allowed ... to build some truly amazing and differentiating features".
- Wavefront - Cloud monitoring and analytics by VMWare "has been using FoundationDB extensively with over 50 clusters spanning petabytes of data in production".
- Update: SkuVault - online warehouse management system, used FoundationDB as a distributed event store (commit log) holding billions of events and a coordination layer for nodes in the cluster.
Obviously, Apple used FoundationDB internally as well, pushing a lot of improvements into it over the years. One of the improvements was the system keyspace sharding which, as Will Wilson mentioned, was the major blocker for the petabyte-scale databases.
Another interesting improvement since 3.0 is the introduction of version stamp operations - atomic operations that put the commit version and batch number of a transaction into a key or value. That could help, for example, when you need to push a lot of writes in order to a cluster (e.g while building a consistent and distributed commit log).
I used FoundationDB in my projects, too. It is just that good and reliable, even when the cluster runs in the cloud environment with flaky networks and rebooting machines. In fact, it is perfectly designed for that environment because of the rigorous testing.
Data Model
FDB is a key-value database with a "weird" design. You can think of it as a giant sorted dictionary, where both keys and values are byte arrays. You can do your normal operations with that dictionary (e.g. set, get, delete, get range) while joining multiple operations into a single ACID transaction.
It is similar to the LMDB - an embedded B-Tree database which I also love and use. It works best, if you use FoundationDB data modeling primitives with it.
This interface is very low-level, however it allows you to build up your own data layers on top, while hosting them on a single cluster:
- object storage;
- lists;
- tables;
- graphs;
- indexes;
- blob storage;
- high-contention queues;
- distributed commit-logs;
- pub/sub.
In essence, FoundationDB is a database constructor.
We've implemented all sorts of layers at SkuVault. Once you get used to the data modeling approach, using traditional specialized data storage systems feels very limiting.
At some point in the past I scraped Web Archive copy of FoundationDB to preserve their data modeling recipes.
Testing
FoundationDB team developed the database inside a deterministic simulation. They abstracted away IO operations like network and disk, which allowed injecting all kinds of faults while running clusters under the load inside an accelerated time.
Examples of faults that could be introduced in such environment:
- network outage;
- buggy router (dropping network packets, duplicating or delaying them);
- disk outages (corrupting data, running out of the disk space or slowing down);
- machine reboots and freezes;
- human errors (e.g. swapping IP addresses or disks).
FoundationDB also had a real hardware cluster which had all kinds of faults thrown at it: power outages, network disruptions and disk filling.
Deterministic simulation in this context means that you can simulate an entire cluster using a single thread. When a bug manifests itself, you could replay that simulation as many times as you want. It will always be the same. Just keep the initial rand-seed.
Running the simulated system under a custom scheduler also enables you to accelerate the time, just like with any discrete-event simulation. If you know that for the next 10ms nothing interesting is going to happen, you could instantly fast-forward the world to that point in time.
Time acceleration means that you can simulate years of cluster life in hours of real time. FoundationDB runtime is extremely rigorous and probably has an acceleration factor of x10. Simpler approaches can get acceleration of x100 to x1000.
You can learn more about the approach from this brilliant talk by Will Wilson: Testing Distributed Systems w/ Deterministic Simulation.
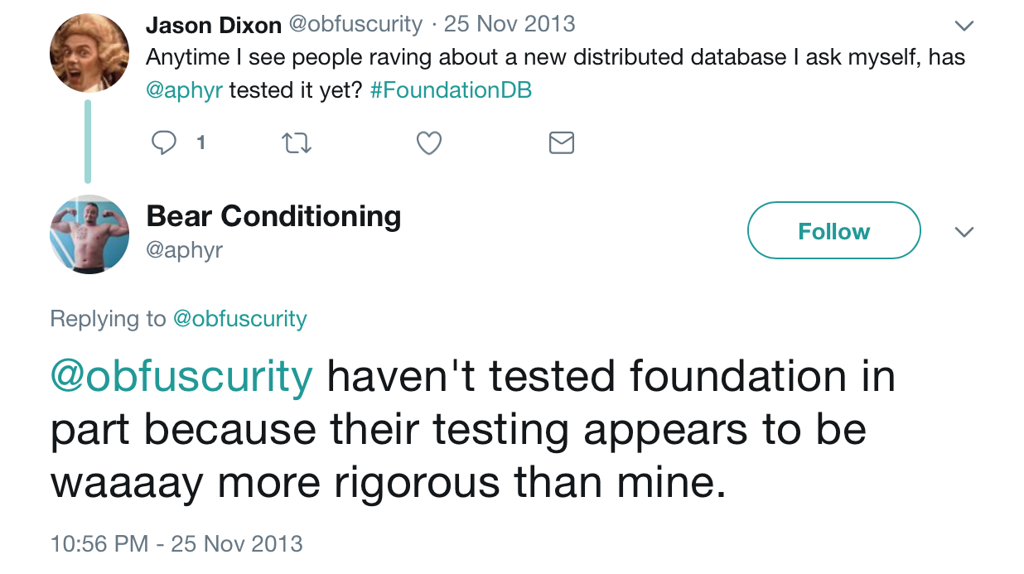
By the way, Kyle Kingsbury ("Aphyr") didn't bother running Jepsen against FDB because FoundationDB's internal testing was much more rigorous that Jepsen.
Simulation Prototype
I've been trying to reverse-engineer and replicate this approach for some time. The research started with a simple CPU job scheduler but quickly escalated to a distributed cluster simulation.
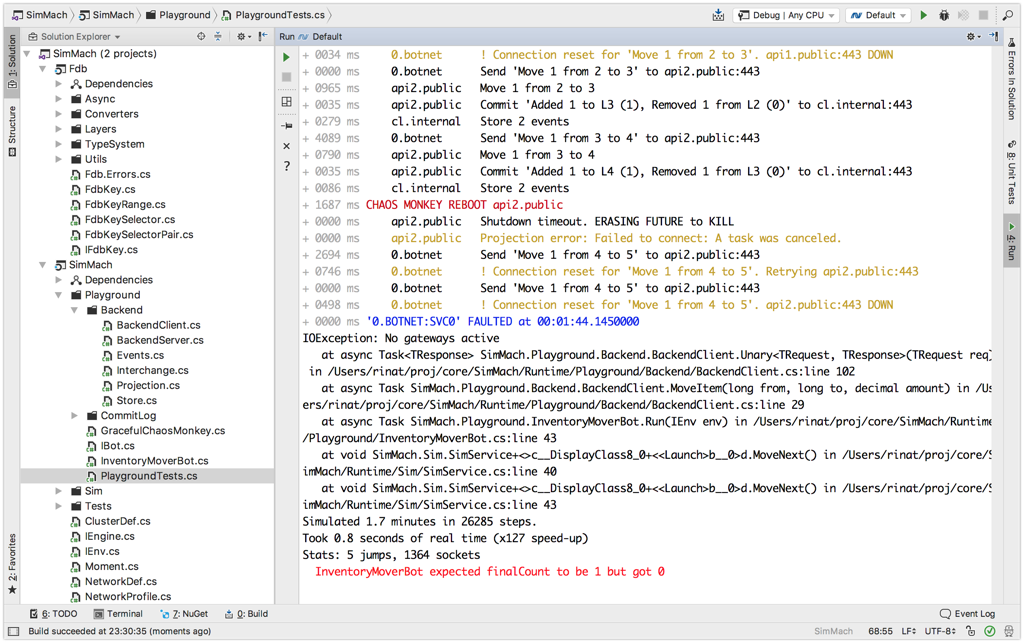
You can check out the last prototype which introduces:
- Configurable system topology - machines, services and network connections.
- Simplified simulation of TCP/IP. This includes connection handshake, SEQ/ACK numbers and reorder buffers. There is now proper shutdown sequence and no packet re-transmissions.
- Durable node storage in form of per-machine folders used by the LMDB database.
- Simulation plans that specify how we want to run the simulated topology. This includes a graceful chaos monkey.
- Simulating power outages by erasing future for the affected systems.
- Network profiles - ability to configure latency, packet loss ratio and logging per network connection.
The prototype builds upon the C# async/await to mimic the benefits
of the FoundationFB Flow language and allow writing code that looks
like normal parallel async but could be run sequentially in a
simulation, rescheduled or erased.
Unlike his naive simulation research, FoundationDB is the real thing. It has all the edge-cases worked out, internal transaction pipelines - tuned and the overall experience battle-tested with huge clusters.
Summary
I'm very excited that Apple has decided to open source FoundationDB. It is an outstanding piece of engineering that helps to build scalable and self-healing distributed systems.
FoundationDB is free to use at any scale. Check it out on github.
You can continue reading this story in a blog post about how SkuVault used FoundationDB all these years.
Published: April 20, 2018.
Next post in Opinionated Tech story: Problem-driven design
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.