Evaluating LLM in business workloads
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
Here for the latest LLM Eval and report? Go to Monthly Reports!
I've been benchmarking various LLM models on business evals for quite some time.
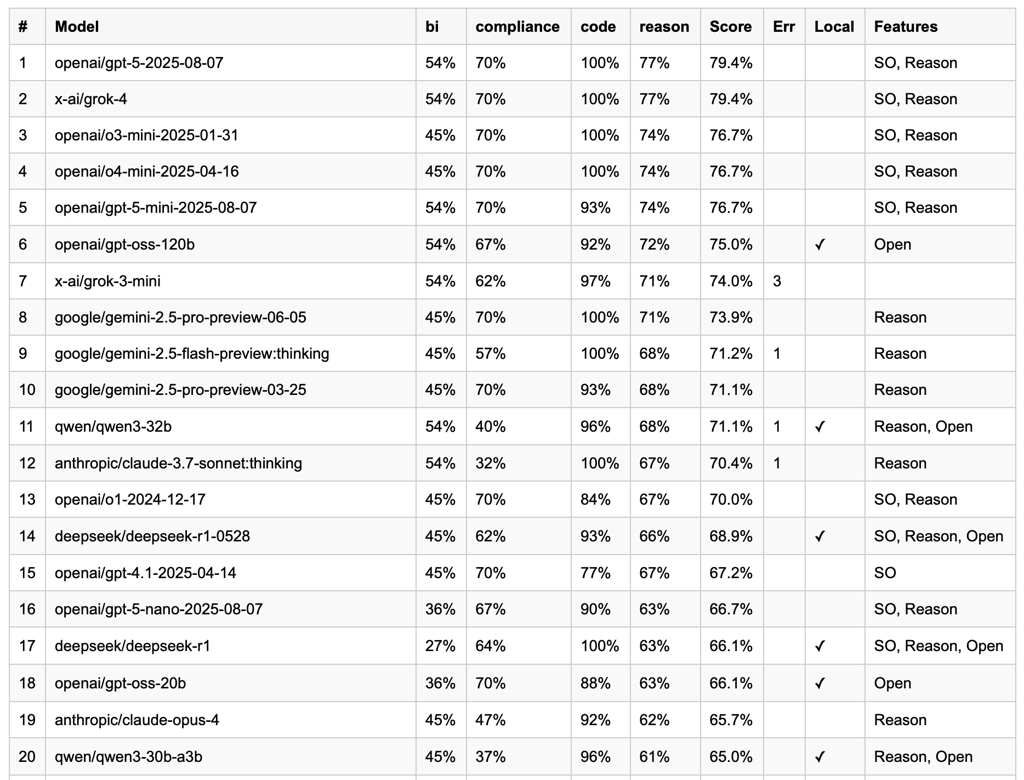
These evals are based on a private collection of prompts and tests that were extracted from real products and AI cases. They don't test how well LLMs talk, but rather how accurately they accomplish various tasks relevant for business process automation.
A typical user of this benchmark - R&D department of a popular soft drink company. They use it to track performance of various models in business-specific tasks.
Questions answered in FAQ below :
- Which models do you test?
- Can you test my model via an API that I will provide?
- Can you share benchmark data to help us improve our model?
- Why is Claude 3.5 Sonnet ranked so low in Code + ENG?
- Why is model X so low/high on this benchmark, compared to LLMArena?
- Why is the model X is ranked too high or too low compared to my expectations?
Monthly Reports
My findings are documented in a series of monthly reports that are published on TimeToAct / Trustbit websites.
Starting from 2025, benchmarks include more complex tasks and leverage Schema-Guided Reasoning (SGR) to solve them:
- Summer 2025 (interactive, pdf): OpenAI GPT-5, Grok-4, DeepSeek, Qwen-3, ERCr3 announcement, SGR
- April 2025 (interactive | pdf) : OpenAI o3, o4 and 4.1, Qwen3, Gemini FLash 2.5 and Pro 2.5, AI+Coding insights
- March 2025 (interactive | pdf): Gemini 2.5 Pro and Gemma, DeepSeek V3 0324, Llama 4
- February 2025 (interactive | pdf): AI Coding tests, OpenAI o3-mini and GPT-4.5, Claude 3.7 and Qwen versions
- January 2025 (interactive | pdf) - Early preview of reasoning benchmarks v2
Simple benchmarks (v1, pre-SGR)
- December 2024 - Benchmarking OpenAI o1 pro and base o1, Gemini 2.0 Flash, DeepSeek v3, Amazon Nova, Llama 3.3 our predictions for the year 2025 and o3 (backup PDF)
- November 2024 - Update: Claude Sonnet 3.5 v2, latest GPT-4o, Qwen 2.5 Coder 32B Instruct and QwQ, Plans for LLM Benchmark v2 (backup PDF)
- October 2024 - Grok2, Gemini 1.5 Flash 8B, Claude Sonnet 3.5 and Haiku 3.5 (backup PDF)
- September 2024 - Chat GPT-o1, Gemini 1.5 Pro v 002, Qwen 2.5, Llama 3.2, Local LLM trends over time
- August 2024 - Enterprise RAG Challenge
- July 2024 - Codestral Mamba 7B, GPT-4o Mini, Meta Llama 3.1, Mistal
- Juny 2024 - Claude 3.5 Sonnet, Confidential Computing, Local LLM Trend
- May 2024 - Gemini 1.5 0514, GPT-4o, Qwen 1.5, IBM Granite
- April 2024 - Gemini Pro 1.5, Command-R, GPT-4 Turbo, Llama 3, Long-term trends
- March 2024 - Anthropic Claude 3 models, Gemini Pro 1.0
- February 2024 - GPT-4 0125, Anthropic Claude v2.1, Mistral flavours
- January 2024 - Mistral 7B OpenChat v3
- December 2023 - Multilingual benchmark, Starling 7B, Notus 7B and Microsoft Orca
- November 2023 - GPT-4 Turbo, GPT-3 Turbo
- October 2023 - New Evals, Mistral 7B
- September 2023 - Nous Hermes 70B
- August 2023 - Anthropic Claude v2, Llama 2, ChatGPT-4 0613
- July 2023 - GPT-4, Anthropic Claude, Vicuna 33B, Luminous Extended
Frequently Asked Questions
Which models do you test?
Currently I'm testing only models served by Google, OpenAI, Mistral, Anthropic and OpenRouter.
This also covers local LLMs (models that you can download and run on your hardware) - any decent model will be served on OpenRouter by somebody.
For example QwQ showed up on OpenRouter within a few days after the release.
Can you test my model via an API that I will provide?
I do not test private LLMs or models offered via APIs outside of the list above.
If you want to test your model, just make sure it gets supported by OpenRouter and ping me.
Can you share benchmark data to help us improve our model?
No, benchmark data is private. But if I tested your model, I can provide general feedback on the types of the mistakes it commonly makes.
Why is Claude 3.5 Sonnet ranked so low in Code + ENG?
While Claude 3.5 Sonnet is really good for coding assistance (in chats and IDEs), it frequently fails on more complex tasks like code review, code architecture analysis or refactoring. These are the tasks that are needed in business process automation related to Code+ENG.
Why is model X so low/high on this benchmark, compared to LLMArena?
LLM Arena is a place where people chat with large language models and ask them questions. Responses are evaluated by people based on personal preferences. Chatty but factually incorrect models have a chance of winning.
This LLM Benchmark is designed for business process automation. If a model is incorrect - it will be downgraded. If a model doesn't follow precise instructions - it will be downgraded. If a model talks too much - you get the idea.
Why is the model X is ranked too high or too low compared to my expectations?
Because we probably have different cases and use LLMs differently.
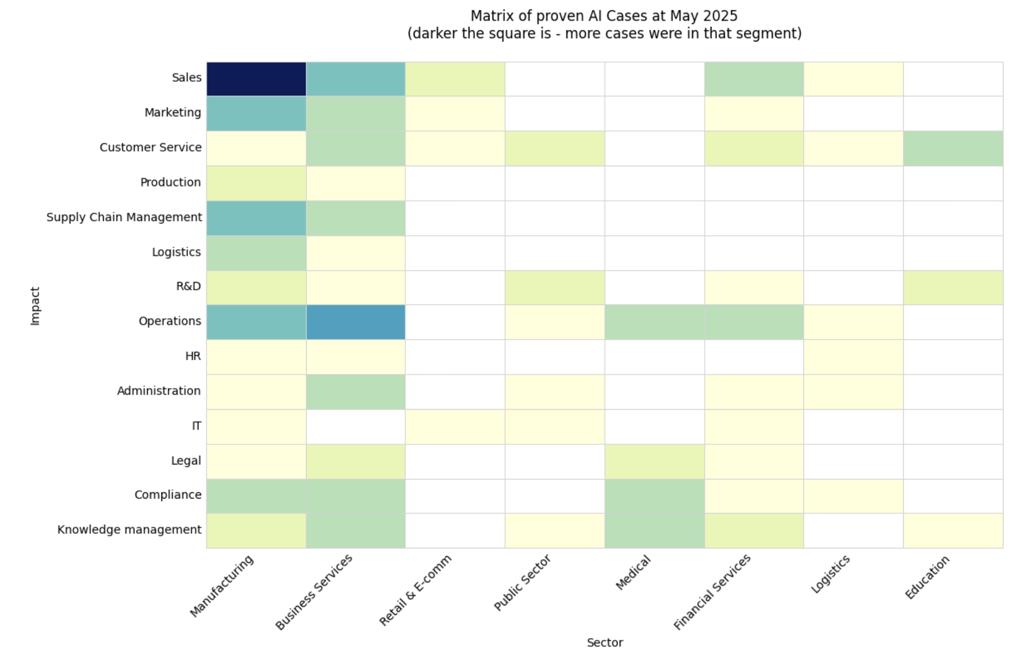
Tests for this benchmark were taken from the AI Cases around business process automation or products with LLM under the hood (companies in Europe and USA). Below is the matrix of AI cases that I've encountered. Darker the square is - more cases were in that segment.
Published: December 02, 2024.
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.