Planning Event-Driven Simulation
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
In my previous article I shared with you through some of growth pains of an event-driven business system. We also discussed some possible solutions:
- use API calls and event contracts as the language of the system;
- capture system behavior with event-driven scenarios;
- create a simple in-memory implementation with the purpose for explaining the system; make it pass the tests;
- create robust and scalable implementation that also passes the tests;
- keep both solutions around, use them to reason about the system and run comparative tests.
This approach worked rather well in practice and the system was pushed to production. We kept on adding more features and inviting more users. 6 months later, it faced peak season of 2016 and survived.
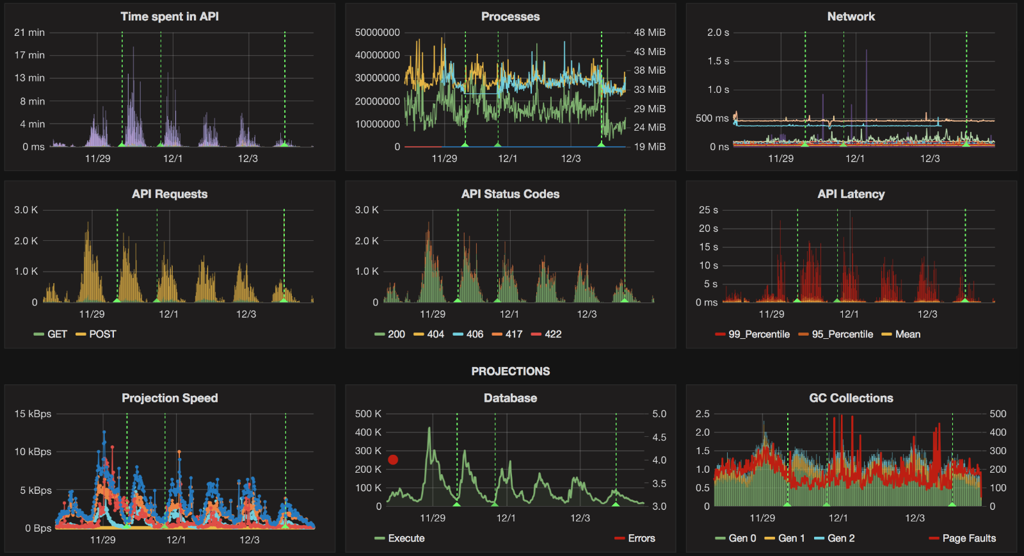
Grafana and Kibana were an invaluable source of insight into the system under the stress. Coupled with various canaries and real-time alerting, they saved the day more than once.
Practice also showed us the pain points of this design: complexity, speed and scale limitations.
This blog post will present a short retrospective over the last 6 months: what worked, what didn't and what we are going to change.
The Good Parts
Here are the things that worked as advertised:
- Event-driven approach in modeling, design and collaboration.
- Given-when-then scenarios (these event-driven specifications are the most valuable part of the codebase by now).
- Statically compiled web app as a front-end.
As you can see, the core of our event-driven approach held strong.
However, some other implementation parts didn't work out as well.
The Fallacy of Two Implementations
The idea of running two implementation side by side looked good in the beginning, but couldn't handle complexity growth in the long term:
One implementation stores everything in memory, helps to validate API and design, runs demo and development modes. The other is obeys the same specifications but is for production.
- Code is a liability, maintaining two implementations of the back-end takes more effort.
- Fixing a bug in memory implementation doesn't necessarily translate to the corresponding fix in the production implementation; models started diverging in subtle ways not described by the scenarios.
In the long run, having a separate memory version of the system felt like a dead-end for us.
Cloud Scale
Cassandra storage back-end didn't work that well for us for a number of project-specific reasons:
- Once you reach 500 event-driven scenarios, verifying production implementation starts taking 20-25 minutes and hence is bound to happen less frequently.
- If you think about it, running a Cassandra cluster in the cloud can get rather expensive for the work it actually does. You need to consider: performance overhead of running a replicated DB on top of replicated SAN, DevOps overhead even with Terraform, unpredictable tail latencies that are inherent to any SAN but somehow are worst on Azure Storage.
- Cassandra is an eventually consistent database (it picks AP from the CAP). Cassandra is very good at what it does, but can't guarantee strong consistency even if you are using something like RF >= 3 with QUORUM on both reads and writes. This is the dark side of deceptively simple CQL that we've been burnt more than once.
Terraform and Packer are amazing tools from HashiCorp. With them we were able to benchmark different cluster configurations in the cloud, iterating through them quickly.
ScyllaDB felt like a worthy contender. This C++ implementation of Cassandra promises 2-10 improvement, but currently lacks some features we use in Cassandra.
In the long run, having a production system running on top of Cassandra felt like a dead-end for us.
If I have enough money for the load and a single writer per entity, I'd pick Cassandra in a heart-beat. It makes a perfect view storage.
Besides, we wanted transactions. This is similar to what the paper on Google Spanner talked about:
We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions.
Smart Scenario Testing
Advanced verification modes (idempotency, delta and random testing) didn't work out for us either. They take a lot of time to run and hence were bound to be used even less frequently than basic verification runs.
To be precise, idempotency tests were used occasionally, delta tests stopped being used after models diverged a little, random tests were never used.
This was a pity, since I liked the idea of catching more bugs simply by running a console in an advanced "hunter" mode.
What Next?
We've been thinking about possible solutions to our problems for quite a while. We needed a solution that would make the code simpler and faster:
- get rid of model duality, reduce the amount of code that we write and maintain;
- replace Cassandra with something that allows us to run tests much faster (at least 30-50 times faster on a development machine);
- be able to handle our ever-increasing amount of data (more than 200GB of events by now), provide good throughput with bounded latency;
- run the same code in the cloud, on dev machines and on-premises.
As we dug deeper, we've realized that the only way to have really fast verification runs was to move data storage inside the application (to get rid of the inter-process communication and also emulate the storage reliably).
However, that option would come at a cost:
- we need to implement our own replication and fail-over;
- fast low-level embedded databases usually come with a simple key-value interface, where both keys and values are byte arrays, so we'd need to implement our own storage layer on top.
FoundationDB Legacy
Fortunately, there once was a nice database called FoundationDB, that was acquired by Apple. The database itself was unique - distributed key-value storage with strong ACID transaction guarantees. It scaled very well and self-healed.
Apple has a policy of wiping out every trace of existence of the companies they buy. This disappointed FDB customers and made everybody else wary of closed-source storage engines.
The engineering team behind that database was even more impressive. They tested their database in a simulation, running entire clusters on a single thread using emulated networking and storage. This approach allowed them to:
- inject faults that would be hard to get in a real world (swapping IPs, flipping network packets, emulating network partitions);
- reproduce any faults or problems deterministically under the debugger;
- emulate days of cluster lifetime in minutes.
@aphyr said: "haven't tested foundation in part because their testing appears to be waaaay more rigorous than mine".
So if we managed to implement some fairly simple (but robust enough) replication and fail-over approach while supporting proper system simulation, then we could test the living daylights out of them under different failure scenarios. We already have the building blocks for simulating everything except the storage, anyway.
Here are a few inspiring resources that we could steal ideas from:
- Consistent Transactions with Inconsistent Replication
- Cheap replication via ordered multicast on the network
- Simple Testing Can Prevent Most Critical Failures
- Use of Formal Methods at Amazon Web Services
- Combining Model Checking and Testing
- Automating Failure Testing Research at Internet Scale
- The Verification of a Distributed System
- Testing Distributed Systems w/ Deterministic Simulation
Lightning Memory-mapped Database
Roughly at the same time we discovered a wonderful piece of engineering called LMDB. It is a very opinionated embedded key-value database with predictable performance and strong ACID transactional guarantees. LMDB is based on B+Tree design, and works very well with read-heavy workloads.
LMDB also leverages memory-mapped files. This means that you can read an object from the database with zero memory allocations. You just need to encode your data using FlatBuffers or Cap'n Proto serialization format. Early benchmarks for event-driven projection with indexes achieved on my laptop 7k/sec (multi-write ACID tx); in event replay mode - 150k/second (ACI).
Luckily for us, FoundationDB also left a lot of legacy in tutorials on how to model various storage layers on top of a key-value database. If you look at things from their perspective, Cassandra storage can map rather cleanly on top of an ordered key-value database. Same for SQL databases as well.
DSLs for Boring Code
We are already using Lisp-based DSL to generate all message contracts with schema validation. It is a natural next step to move even more of the boring and verbose code into a higher-level DSL:
- API definitions and DTOs (with added benefit that we can generate swagger definitions, client libraries and documentation);
- storage layer for key-value database (hand-coding tuple and byte operations is boring);
- pull application-specific consistency controls into the code.
Why bother with Lisp? Check out this great article on Lisp and Racket written by a newcomer.
Next Steps
These insights helped us to plan our next design iteration:
- keep event-driven design, all scenarios and APIs;
- discard in-memory implementation completely;
- replace Cassandra backend with LMDB implementation using FDB storage layer approach;
- use LMAX-style replication approach (master replicates events to followers, we fail over to them via the LB);
- take ideas from papers like TAPIR to make consistency decisions part of an application logic (which matches what business did for years anyway);
- simulate the system and beat it with failures, taking inspiration from giants like Netflix, Twitter, FoundationDB, Amazon;
- save money by replacing a rather expensive Cassandra cluster with smaller and cheaper application node replicas, partitions; also get a simulation cluster (running on buggy hardware);
- replace repetitive code (or code that tries to work around the limitations of OOP) with meta-programming.
In theory all this should work well.
Published: December 04, 2016.
Next post in SkuVault story: Emerging DSL
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.