Data, Use Cases And New Module
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
Last week I was simply developing in a pleasing and steady way:
alerts- clean JSON API and more use cases to verify its behavior;diary- clean JSON API, more use cases and support of member blocking;chat- more use cases;like- clean JSON API and use cases;favorite- implemented full module, including JSON API, major use-cases, etl and seeding.
Data Extraction from v1
I spent some more quality time with .NET/C# last week, adding more data types to our script responsible for graceful data extraction from HPCv1 databases into compact binary representation (GZIPped stream of length-prefixed binary-encoded objects). This representation works very well for further data processing even at the scale of terabytes.
So far I extracted data from all of the largest tables in Finland database, writing event generation code for all matching modules and smoke-testing them on glesys. HPCv2 handles that data pretty well, although RabbitMQ gets a little strained while handling 1500000 messages and copying them into a dozen queues. We'll probably need to optimize our message routing strategy a little here.
Fortunately, we can simply reuse data from our wonderful use case suite.
I'll be on a vacation next week, so we tried to reproduce process of data retrieval (from binary dumps) and event seeding on the machine of Pieter. It worked without issues.
Use Cases
We are slowly falling in love with use case approach in the codebase of HPCv2. Writing them is a pleasure, and they actually speed up and simplify the development. At the moment of writing we have 50 of them, verifying different behaviors of JSON API for the frontend that Tomas will be working on when he gets back.
I added ability to render use cases into a dependency graph, helping to see development results from a different perspective. Visual representation allows your brain to understand code from a different perspective, making it easier to spot new dependencies or gaps in the code. It is easier to communicate, too.
For example, while developing favorite module from scratch,
its graph looked like this:
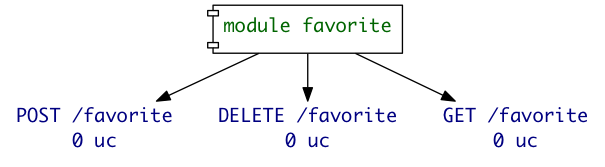
Later that day, when the module was complete and covered with 7 use cases, it looked like this:
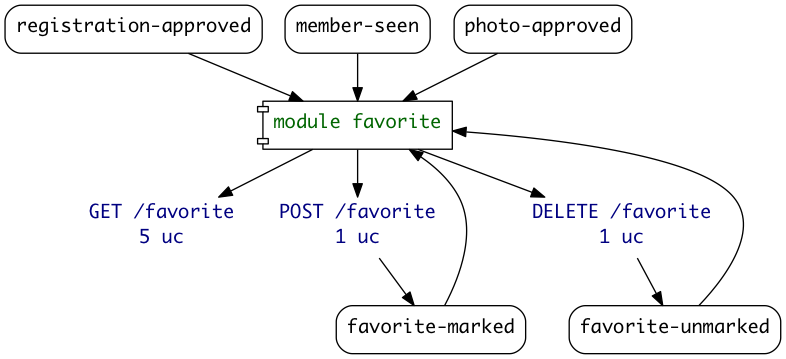
This graph is auto-generated from the code via this process:
- Load a specific module (or all of them), inspecting registrations in the process.
- Inspect all use cases for input events, HTTP requests and output
events. We can do that because each use case is simply a data
structure, describing:
GIVENprevious events,WHENwe call API endpoint,THENexpect API result and 0 or more events. - Print resulting data model in a
dotfile format forgraphvizprogram to render.
Of course, if some dependency is not covered by a use case, then it is not visible on such graph. I consider this to be a good feature, since it encourages me to cover all important cases.
Of course, it is possible to graph all modules and their dependencies. That map would be useful for spotting some loose ends or old dependencies.
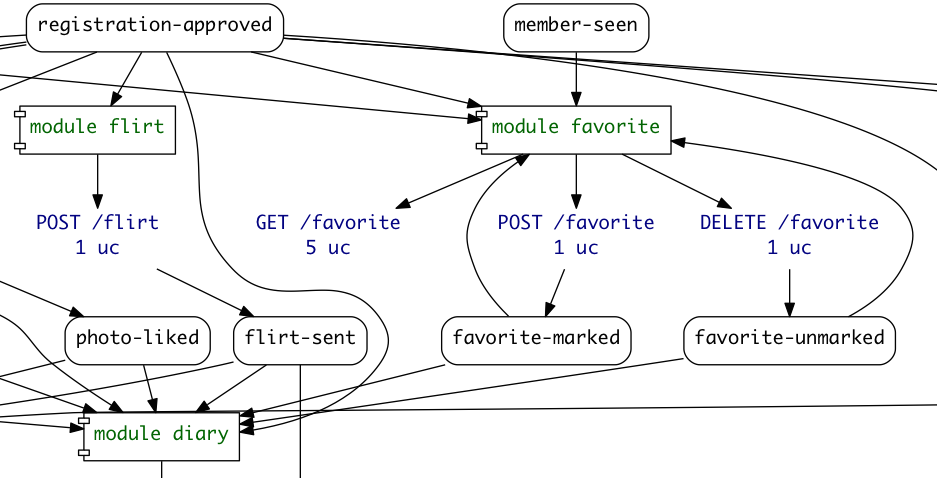
Pieter was busy cleaning up the overall codebase, working on the
implementation of draft, review and getting read of some obsolete
logic.
Next week I will be completely on a vacation, spending time around the
Elbrus mountain. If there are any free periods of time (e.g. long bus
rides), I'd love to clean up the profile module, adding a clean JSON
API to it.
Living Documentation
Tomas is coming back from the vacation that week. He'll probably get back to the front-end development on top of our new JSON API. When he does, he can see living documentation for out current system.
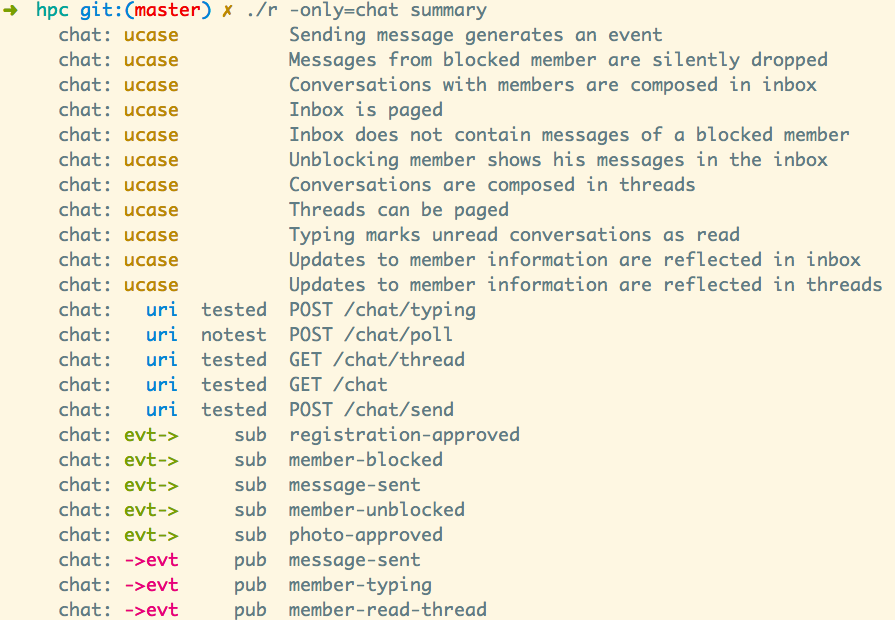
First, run ./r story to see all use cases.
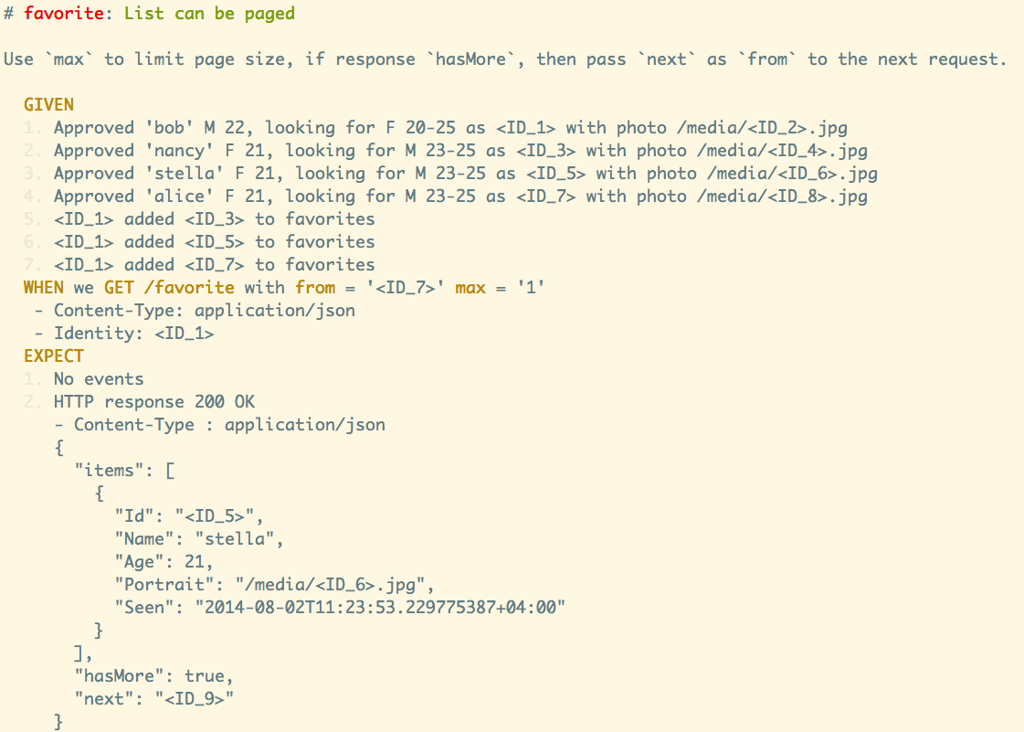
Second, run ./r summary to see grep-able metadata about the system
(mostly derived from the use cases).
Third, run ./r graph | dot -Tpng > graph.png to create dot file for
the system and then feed it to grapviz.
Of course, each output can be altered with other programs like grep
to filter, group and aggregate information in interesting ways.
This kind of documentation always stays up-to-date and does not need any effort to maintain.
Published: August 02, 2014.
Next post in HappyPancake story: Back from the Vacation
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.