Scala, Modular Design and RabbitMQ
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
Our system is event-driven in nature. Almost everything that happens
is an observation of some fact: message-sent, photo-liked,
profile-visisted. These facts are generated in streams by users
interacting with a system. Due to the nature of human interactions,
there is little concurrency in these streams and it is ok for them to
be eventually consistent. In other words:
- A user is likely to interact with the site through one device and a single browser page at a time.
- While communicating through the system, users don't see each other and don't know how fast the other party responds. If a system takes 1 second to process and deliver each interaction then probably nobody will notice.
- The system should feel responsive and immediately consistent (especially while viewing your writes on the profile page and chatting).
These considerations are very aligned with designs based on reactive and event-driven approaches. During the last 2 weeks we played with multiple implementation ideas of that:
- Use replayable event streams for replicating state between modules.
- Use either FDB-based event storage (which we already have) or the one based on apache Kafka.
- Use a messaging middleware cabale of durable message delivery across the cluster with a decent failover (read as "RabbitMQ")
- Use a pub-sub system without a single point of failure and relaxed message delivery guarantees (read as NSQ or Nanomsg with ETCD).
Each of these approaches has its own benefits and some related complexity:
- mental - how easy or hard is it to reason about the system;
- development - how much plumbing code we will have to write;
- operational - how easy or hard will it be to run it in production.
Obviously, we are trying to find approaches which reduce complexity and allow us to focus on delivering business features.
Scala Theorem
While talking about Apache Kafka Tomas had an idea of switching the entire codebase to Scala and JVM. Java has a lot of big supporters and a large set of great solutions fit for us. A few days last week were dedicated to evaluation on how easy or hard would it be to drop all go code and switch to Scala / JVM. Here are the conclusions:
- Scala is a nice language, although builds are insanely long slow (if compared to sub-second builds in golang).
- Porting our core domain code to Scala is not going to be a problem, it could probably be done in a week (code is by-product of our design process).
- Devil is in the details, learning the rest of JVM stack is going to take a lot more time than that (e.g.: how do we setup zookeeper for Apache Kafka or what is the idiomatic approach to build modular web front-end with Java?).
In the end, switching to Scala was ruled out of the question for now. Even though this switch has its long-term benefits, it would delay our short-term schedule too much. Not worth it. Besides, Java stack seems to introduce a lot of development friction hurting rapid development and code evolution. These are essential for us right now.
RabbitMQ
We also switched to RabbitMQ for our messaging needs - Pieter single-handedly coded bus implementation which plugged into our bus interface and worked out-of-the-box. Previous implementation used in-memory channels.
So far RabbitMQ is used merely do push events reliably between the modules:
- all modules publish events to the same exchange;
- each module on startup can setup its own binding and routing rules to handle interesting events.
Although we no longer consider using event streams for replaying events as part of the development process, we could still have a dedicated audit log. This can be done by setting up a dedicated module to persist all messages, partitioning them by user id.
Modules
We spent some time discussing our design with Pieter. One of the important discoveries was related to a deeper insight into Modules. Previously we talked about our system using components, services, packages interchangeably. This was partially influenced by the term micro-services which was one of the ideas behind our current design. Some confusion came from that.
Instead of "micro-services architecture" at HPC we started talking about "decomposing system into focused modules which expose services"
These weeks we were able to refine our terminology, starting to clarify the codebase as well:
- our application is composed from modules - tangible way to structure code and visual way to group design concepts into;
- we align modules at the design level and modules in the code - they share the same boundaries and names;
- at design level modules are boxes that have associated behavior, we need them to contain complexity and decompose our design into small concepts that are easy to reason and talk about;
- in the codebase our modules are represented by folders which also are treated as packages and namespaces in golang;
- we like to keep our modules small, focused and decoupled, this requires some discipline but speeds up development;
- each module has its own public contract by which it is known to the other modules; implementation details are private, they can't be coupled to and are treated as black-box;
- Public contract can include: published events (events are a part of domain language), public golang service interfaces and http endpoints; there also are behavioral contracts setting up expectations on how these work together;
- in the code each golang package is supposed to have an implementation of the following interface, that's how it is wired to the system; all module dependencies are passed into the constructor without any magic.
type Module interface {
// Register this module in execution context
Register(h Context)
}
type Context interface {
// AddAuthHttp wires a handler for authenticated context which
// will be called when request is dispatched to the specified path
AddAuthHttp(path string, handler web.Handler)
// AddHttpHandler wires raw http.Handler to handle unauthenticated
// requests
AddHttpHandler(path string, handler http.Handler)
// RegisterEventHandler links directly to the bus
RegisterEventHandler(h bus.NodeHandler)
// ResetData wipes and resets all storage for testing purposes
ResetData(reset func())
}
Getting the notion of modules right is extremely important for us, since it is one of the principles behind our design process. We think, structure our work and plan in terms of modules.
For the upcoming week we plan to:
- Cleanup the codebase (one module at a time), finishing the alignment to RabbitMQ;
- Capture and discuss next HPC features to be implemented (summer vacations are coming and we want to prepare work so that we could continue moving forward even when the rest of the distributed team is offline, taking motorcycle classes or hiking to the top of Mount Elbrus); this will add more stand-alone modules;
- Start writing two-phase data transformation tooling to export data from the current version of HappyPancake and transfer it into the event-driven version; this would allow to validate the design of existing modules and stress-test the system.
PS: Why Emacs is better than Vim?
Over my entire life I've been searching for a sensible way to handle tasks and activities, both everyday and job-related. Tooling ranged from MS Project Server (for large projects and distributed teams) to OmniFocus (personal todo lists).
Earlier this year I discovered org-mode - a set of Emacs extensions
for managing notes and tasks in text files. That was the reason for
switching to Emacs from sublime.
Recently I caught myself managing some small tasks and notes of HPC
project via org-mode as well. All hpc-related information is stored in
a textual hpc.org file kept in the repository with the source code.
Anybody could read or even edit this file.
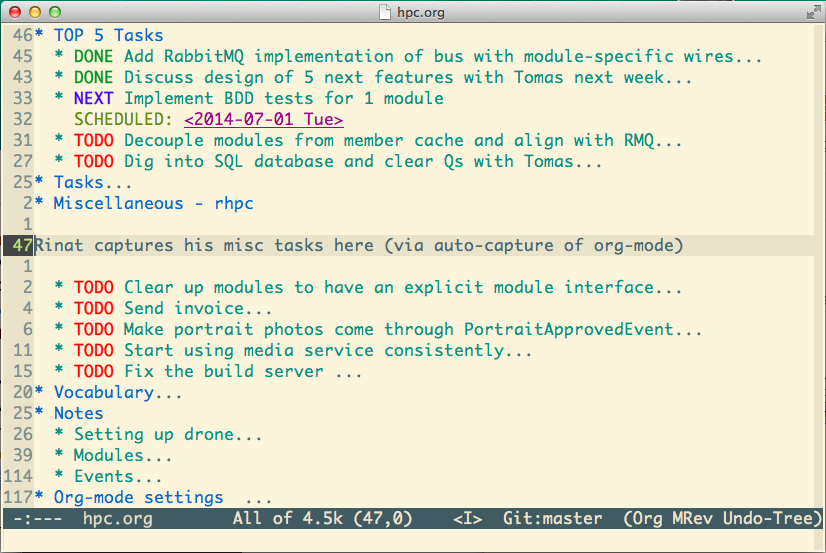
Emacs, of course, provides more benefits on top of that mode:
- ability to view and manage entries from all org-modes on my machine;
- capturing new tasks with a few key strokes;
- powerful agenda and scheduling capabilities;
- exports to a lot of formats;
- auto-completion, tags, categories, outlining, refiling, filtering etc.
For example, here is overview of my agenda, filtered by hpc tasks:
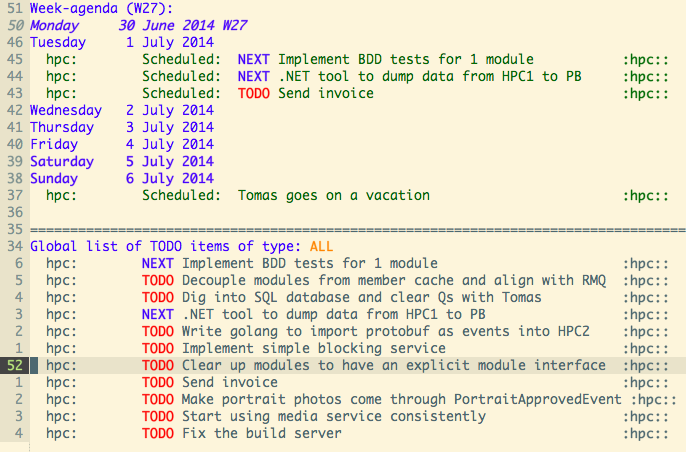
I think, I got Pieter thinking about giving a try to Emacs, since Vim does not have org-mode (or a decent port).
Published: June 30, 2014.
Next post in HappyPancake story: Distributing Work
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.