Messaging - Heart of a Social Site
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
At the beginning of the last week I had a simple responsive prototype of a chat server. It was a simple in-memory implementation in go, delivering messages and "user is typing" updates instantly over long polling http requests.
Obviously, a single server chat application wouldn't be enough for HappyPancake.com. We want to serve live updates to 20000 online visitors (numbers from the current version of the web site), while also adding in some headroom for the scalability and fault tolerance.
So the last week was dedicated to search, trials and failures on the way to multi-node clustered chat server.
I started by reading a lot about existing chat designs and approaches outside of golang. Erlang and Akka were recurring theme here. So I tried to move forward by implementing something like akka's actor model (Singleton actor patter) in golang while using Leader Election module of ETCD.
What is ECTD? ETCD is a highly-available key-value storage for shared configuration and service discovery. It is written in GO and uses RAFT algorithm (simpler version of PAXOS) for maintaining consensus across the cluster.
That was a dead-end:
- Re-implementing akka in golang is a huge effort (too many moving parts that are easy to get wrong)
- Leader Election module in ETCD is theoretically nice. Yet, in practice it is considered as experimental by CoreOS team. Besides, go-etcd client library does not support it, yet.
At some point we even pondered if switching to akka was a viable strategy. However, NSQ messaging platform (along with the other projects from bitly) served as an inspiration of getting things done under the golang. A few more days of consuming information on the design and evolution of social networks and I had an extremely simple working design of a multi-node chat.
There were 2 small "break-throughs" on the way:
- You can use basic functionality of ETCD keys (with TTLs and CompareAndSwap) to implement entity ownership across the cluster
- We don't really need a concept of actors to implement a scalable cluster. Dead-simple semantic of Http redirects would do the job just fine.
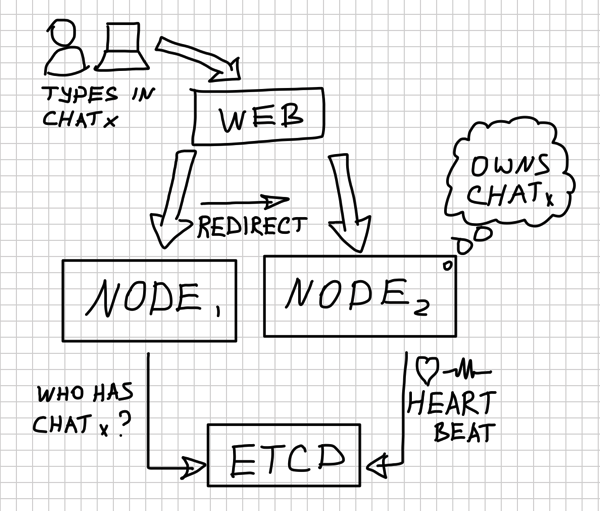
All chat conversations are associated with one out of N (where N is an arbitrary number) virtual chat groups through consistent hash of the conversation ID. A chat group can either be owned by a node (as indicated by the renewed lease on ETCD key) and be available in its memory. All other nodes will know that because of the ETCD registry and will redirect requests to that node.
Alternatively, a chat group can be owned by nobody (in case of cold cache or if the owning node is down). Then a random node (smarter algorithm could be plugged later) would take ownership of that chat group.
Why bother with concept of chat groups? Querying ownership of 100000 of chat conversations can be pretty expensive, besides we would need to send heartbeats for each of this conversations. It is easier to allocate N chat groups, where N is a fixed number. This can be changed later, though.
Result of all that : a dead-simple chat prototype that runs on 1-K nodes, where nodes are extremely simple and can discover each other dynamically, sharing the load. If a node dies - another one would take ownership of the chat conversation.
All chats are reactive. "user is typing" notifications and actual messages are immediately pushed to the UX over http long-polling connections. More types of events will be pushed over these channels later.
Part of that simplicity comes from the fact that golang simplifies work with concurrency and message passing. For example, the snippet below flushes all incoming messages to disk in batches of 100. If there were no messages for a second, it will also flush captured messages.
var buffer []*Record
for {
select {
case r := <-spill:
buffer = append(buffer, r)
if len(buffer) >= 100 {
persistMessages(buffer)
buffer = make([]*Record, 0)
}
case <-time.After(time.Second):
if len(buffer) > 0 {
persistMessages(buffer)
buffer = make([]*Record, 0)
}
}
}
For this week I plan to move forward:
- Finish implementing a proper node failover (currently nodes don't load chat history from FoundationDB)
- Made nodes inter-connected between each other (we actually need to publish notifications for a user in real-time, if he gets a message, flirt or a visit from another user). NSQ (real-time distributed messaging platform in golang by bitty) seems like a really nice fit here.
During the week I also did some benchmarking of ID generation algorithms in golang for our event store layer on FoundationDB (not a big difference, actually). Here is the speed of appends (1 event in a transaction, 200 bytes per event, ES running in 1 node on Glesys with 5GB RAM, 2 Cores and VMWare virtualization; client - 4 core VM with 8GB RAM):
10 goroutines : 1k per second, 10ms latency (99) 50 goroutines :
3.5k per second, 12ms latency (99) 100 goroutines : 5k per second,
20ms latency (99) 250 goroutines : 7k per second, 35ms latency
(99)
Meanwhile, Pieter was working on profiles, news feeds and registration flows. He was stressing out different database engines by uploading data from the existing user base of happypancake.com. There is a lot to learn about the behavior of different technologies in our scenarios. In the end we seem to be converging back on FoundationDB as the primary storage. Tomas was mostly busy with admin, UI design and maintenance of the first version (protecting Pieter and me from the boring stuff).
Here is some reading of the week:
- NSQ Messaging platform (project)
- Lessons learned optimizing NSQ(slides)
- About NSQ(slides)
- About NSQ(video)
- Service discovery in the cloud(article)
- Distributed algorythms in noSQL databases(awesome article)
Published: April 21, 2014.
Next post in HappyPancake story: Event-driven week
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.