Smarter Development
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
Shorter Feedback Loop
We have a continuous integration server responsible for running tests on code pushed to the repository. It is more diligent than humans and always runs all tests. However, in order to see build failures one had to visit a build page (which didn't happen frequently). Our builds were broken most of the time.
I tried to fix that by plugging build server directly to our main chat. All failures and successes are reported immediately. Build stays green most of the time.
Working with Finland
I spent time trying different strategies to populate our system with Finland dataset. This population happens by generating events from raw data dump and dispatching them to our system. Currently we generate only a subset of events, but that already is more than 1000000 of them, sent at once. If we can handle that, then we stand a chance against Sweden dataset.
I focused on news module, which has one of the most complicated and
time-consuming denormalization logic:
- each member has his own newsfeed;
- each member has an interest in some people (e.g. in females with age between 25 and 30 and living in city X);
- newsfeed is populated with events coming from other members which are interesting to this member;
- new members by default will have an empty newsfeed, we need to back-fill it with some recent events from interesting members;
- if member blocks another member, then events from the blocked member will no longer show up in a newsfeed, existing events have to be removed.
My initial implementation of news module was handling events at an
astonishing speed of 2-10 events per second. I spend multiple days
learning inner workings of our stack and looking for simple ways to
improve the performance.
StatsD and EXPLAIN ANALYSE from PostgreSQL helped a lot to reach
speed of 200-400 events per second.
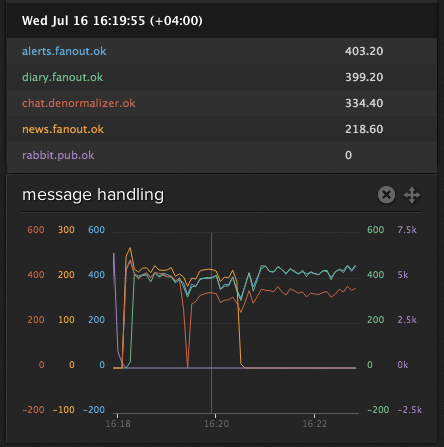
Solution was:
- push all event denormalization to PostgreSQL server (fewer roundtrips);
- handle each event within an explicit transaction (no need to commit between steps within the event handling);
- rewrite queries till they are fast.
So far the performance is quite good so we don't need to bother too much about pushing it further so far. Adding more features is the most important thing now.
Control is important
It is really important for members of our dating web site to know that they are in the control. They should be easily able to block out any unwanted communications. That's why we have block feature - ability to put another member into an ignore list, effectively filtering him out from all news feeds, conversations and any other lists.
I started working on that interesting feature only to realize that it has a lot of implications. Each other module would react differently to the fact that a user is being blocked.
We need to somehow keep a track of all these requirements. Preferably it will be not in a form of the document, since documents get stale and outdated really fast (keeping them fresh requires time and concentration which could also be spent developing new features). Ideally, these requirements could also be verified automatically.
Improving Use Cases
I invested some time to improve our module BDD tests, transforming them into proper use-cases. These use-cases:
- are still written in golang;
- are executed with unit tests (and provide detailed explanation in case of failure);
- can be printed out as readable stories;
- can be printed as a high-level overview of the system.

Of course, these stories aren't readable by absolutely everybody. That's not the point. Their purpose is:
- Give sense of accomplishment for developers encouraging them to write tested code (me and Pieter);
- align tests with expectations from the system (help to make sure that we are testing what is important);
- provide a quick up-to-date documentation of the API and scenarios for other developers who would be working with the system (Tomas);
- express behaviors of the system in a way that is not tied to any language (e.g.: Tomas will not need to dive into the golang code in order to consume API from node.js).
The best part is that these nice stories are generated automatically from the code. No extra effort is required (apart from writing a small rendering logic in golang while riding on a bus in Adjaria).
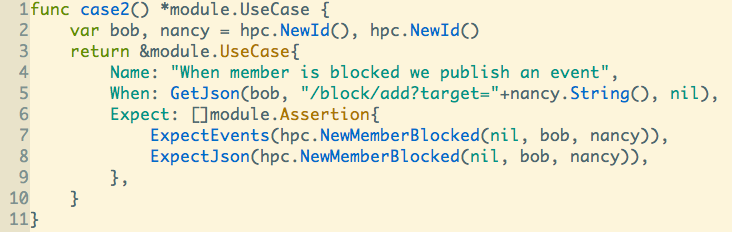
With this approach it becomes simpler to have high-level overview of what is already done in the system and what has to be done. Simply list names of all passing use cases per module and you have that kind of overview. Other interesting transformations are also possible (i.e.: dependency graphs between modules, event causality patterns etc). They all provide additional insight into the domain model, allowing to have greater insight into the code we write and maintain its integrity.
It is quite possible that we could completely discard this code once we hit the production. Need to maintain the integrity of domain model will be replaced by different forces by then.
My plans for the upcoming days are to keep covering our existing functionality with these use-cases and adding new functionality.
Published: July 21, 2014.
Next post in HappyPancake story: Delivering Features and Tests
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.