Real-Time Analytics with Go and LMDB
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
I'd like to share a few details about a project I've been working this year: a lean platform for real-time analytics and batch reporting.
Project Inception
The project started as an internal tool for running ad-hoc reports on business event streams. Existing tools took 5-8 hours to download a billion of events, replay them and produce useful reports.
Event replay within 5-8 hours is good enough for warming up local caches on production nodes. However, it doesn't fit well with data analysis which has to iterate through multiple theories and experiments. You will probably forget 80% of the experiment by the time the results are ready.
In my spare time I started working on experimental tooling to speed up the process and figure approaches that combine iterative and incremental event processing with occasional full replays.
Constraints
This project had a few constraints from the start:
- No multi-node data processing frameworks. Although Kafka and Spark could do the job, they come with dependencies like ZooKeeper and DevOps related overhead. I needed something simple that could efficiently utilize hardware on a single machine.
- Encryption and compression had to be supported by the infrastructure from the start. While modern file systems could handle both aspects, in some specific cases it would be more efficient to let the application layer handle these concerns.
- Throughput over latency is a trade-off that allows to avoid a lot of complexity in the code. Analytical pipelines are likely to spend seconds and minutes digging through the numbers anyway, so there is no need to optimize for sub-millisecond latency for the individual events.
- Simplicity and reuse - an inherent constraint, since the project was initially running on a limited time budget (roughly 15 hours per month).
First Version in .NET
The initial implementation was mostly done in .NET, since that is the platform I was most familiar with.
I evaluated .NET Core, but at the moment tooling was too fragile and important libraries were still missing from the ecosystem. Despite the promise of Linux-friendliness (which halves hosting costs), actually developing in .NET core would've blown my time budget out of the water.
Implementation consisted of:
- Analytical event storage, optimized for throughput and supporting a single writer with multiple readers.
- Data processing stages responsible for incremental event import, compression, filtering and aggregation; they operated on event storage streams (similar to how Kafka is used in multi-node systems), using durable in-process database for indexes, metadata and non-stream artifacts.
- Full replay stages which operated on compressed event streams, feeding them to in-memory actors for anomaly detection and fine-grained analysis.
- Visualization and report generation was done with python (charting) and lisp (html dahboard generation) stages.
Due to the nature of Lisp, I inevitably ended up with a DSL for defining tiles and dashboards. That is something worth exploring in more detail later.
This overall setup was similar to what you'd do these days with Apache Kafka, Spark and Spark Streaming, but it lived on a single machine. It was able to provide up-to-date visual and numeric answers to complex questions in matter of minutes instead of the hours.
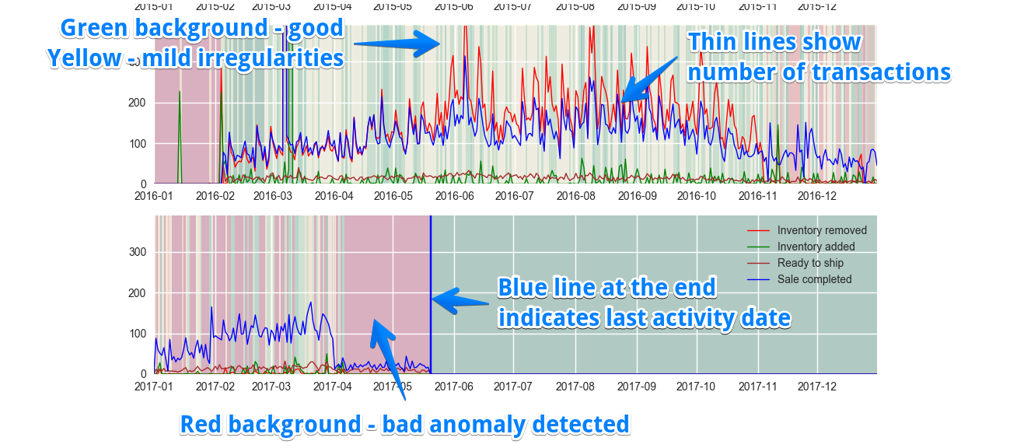

This worked because "heaviest" data transformations were incremental, while full replays operated on optimized datasets.
LMDB - The Transactional Heart
Almost all of the storage needs were handled with LMDB, which saved a ton of time in development without sacrificing performance.
Databases like SQLite, LevelDB, RocksDB were evaluated, but discarded for performance or complexity issues (out-of-process databases were ignored). Besides, designing data models in terms of lexicographically sorted byte ranges is something I'm very comfortable with (provided the store provides true ACID guarantees).
LMDB responsibilities:
- meta-data of the analytical event store: event chunk headers, event processing checkpoints;
- indexes, lookup tables, aggregated counters and mappings used by the data processing stages;
- final reporting artifacts: tables, lookups, time-series and meta-data.
Switching to golang
Some time along the way, I started porting core parts of the platform to golang for following reasons:
- Golang offers lightweight concurrency primitives that work well for real-time data ingestion, aggregation, incremental and batch processing.
- I wanted to migrate deployments to Linux/Unix to reduce hosting costs and gain access to its ecosystem: tools and knowledge on performance optimization.
- Golang also works well for fast and efficient API gateways that ingest data into the system or expose resulting data to the other systems.
Rewrite took some time, but it was quite straightforward. There were some nice performance gains along the way. For instance, the new version of event storage layer can read event partitions at the speed of ~600 MB per second on a modest Intel Xeon server with NVMe SSD. This includes decryption and decompression of event data. My Windows Azure deployments were ~10x times slower and way more expensive for obvious reasons.
First Linux deployment
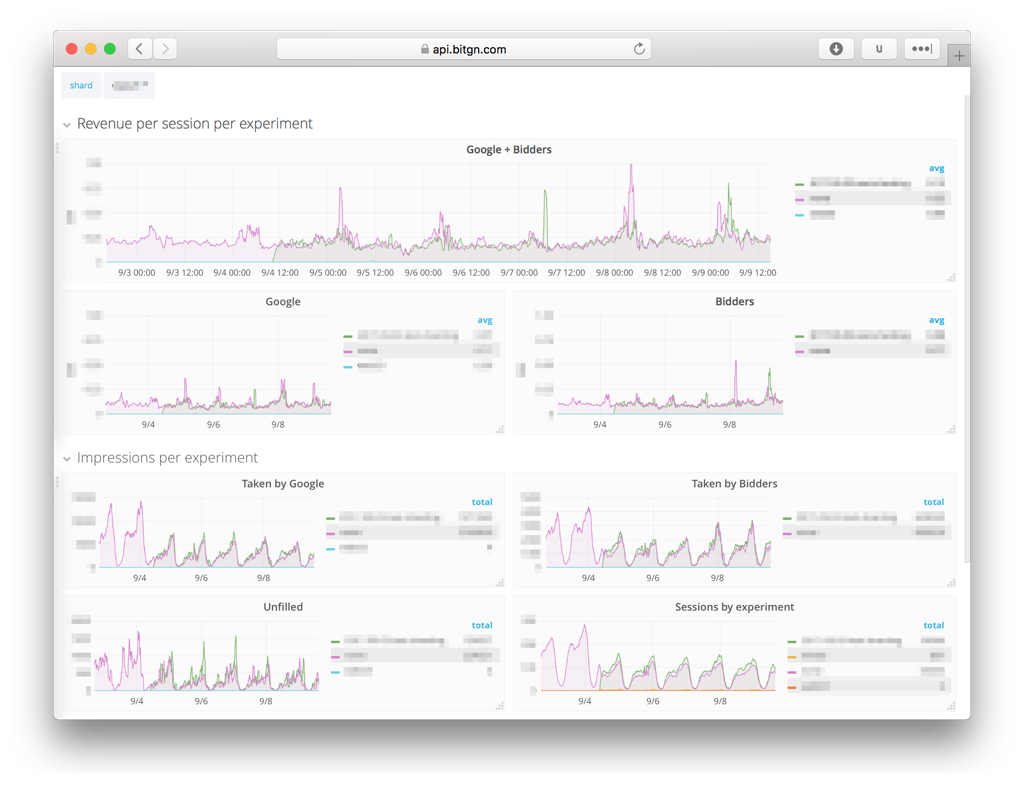
First deployment of the new version was rolled out recently. It is an analytical platform that captures events from real-time bidding auctions (header bidding and google AdX) coming from thousands of sessions running in parallel. This data can then used for real-time insight, experiments and long-term reporting driven by the financial indicators.
This deployment handles 10M impressions per day across 4 different shards.
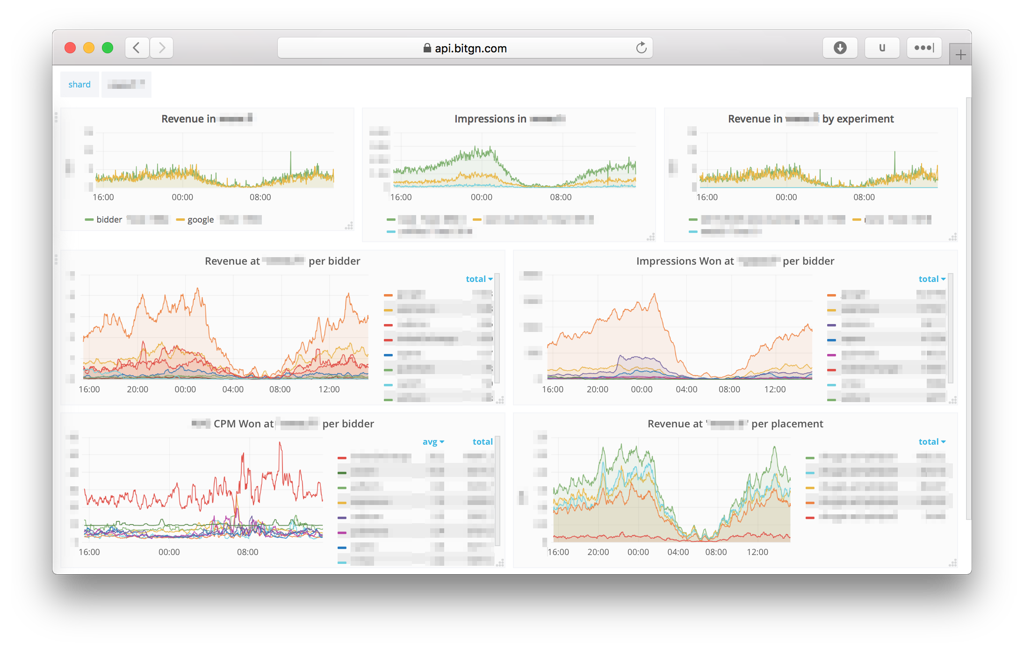
A few interesting features:
- real-time dashboards with statistics for CPM, revenue (including Google AdX estimate), Ad size performance, bidder performance and responses, placements, user segments and sessions;
- aggregating and slicing data across placements, bidders, shards and experiments;
- running experiments (fine-grained A/B testing) and tracking their financial impact in real-time;
- long-term data retention and analysis which enable tracking revenue indicators per session and user lifetime, bidder behavior changes and the long-term impact of experiments.
Storage and analysis layer is designed to support machine-assisted user segmentation and tuning of real-time bidding parameters within these segments. Experiments and revenue indicators provide a tight feedback loop for this process. All this is essential for publishers that want to increase their revenue in the world driven by players with large investments in automation and machine learning.
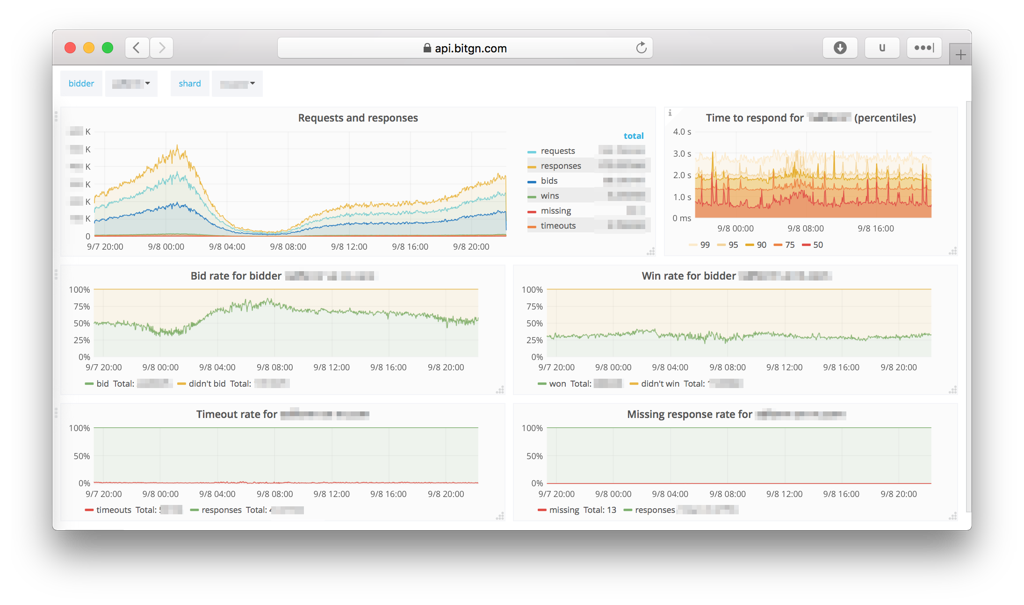
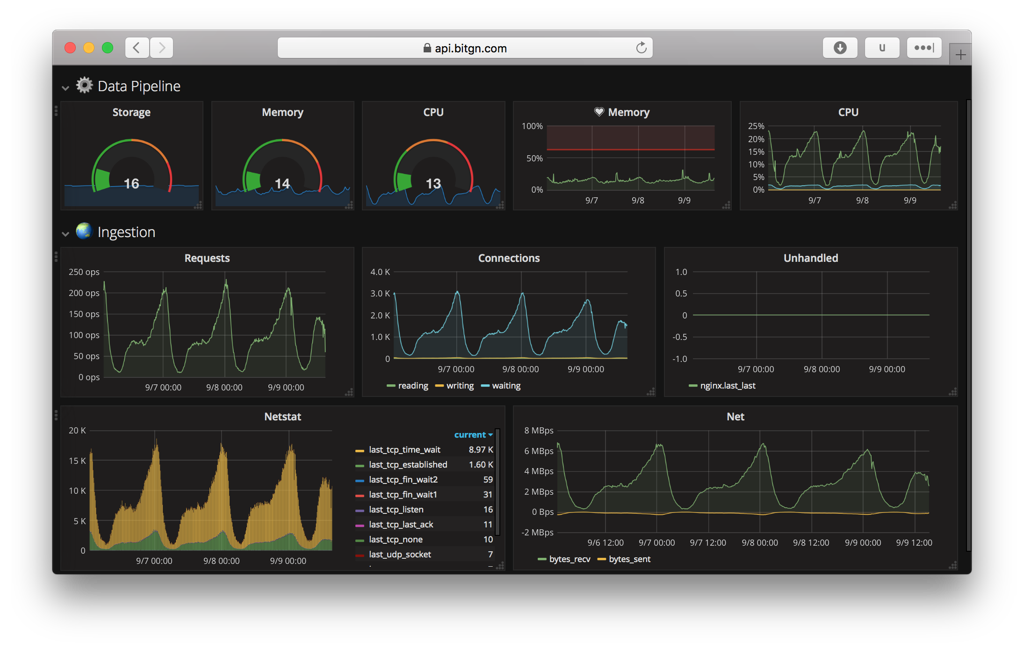
Implementation Details
Complete tech stack of this solution is rather simple:
- Ubuntu 16 LTS running on dedicated server (e.g.: Intel Xeon with DDR4 ECC RAM and SSD RAID on NVMe);
- Nginx for API intake and SSL termination;
- Golang and LMDB as the data processing heart of the system;
- Partitioned analytical event storage with AES encryption of data-at-rest (high-throughput, single writer and multiple readers);
- Telegraf with InfluxDB and Grafana for real-time display;
- python for custom reports that don't fit real-time UI.
I find python invaluable for some data manipulation and analysis tasks these days. Its rich ecosystem (e.g. starting from matplotlib, pandas and up to keras and tensorflow) can save a lot of development effort. Obvious fragility and complexity side-effects could be mitigated by freezing dependencies and exposed abstractions.
What Next?
It will be interesting to push this platform to its limits either with data loads or challenging ML tasks. So far, event streams running at rate of 10-30M events per day from thousands of connected devices aren't a big challenge for a single small-ish server with Linux, golang and LMDB.
Bear in mind that hardware is evolving rapidly these days. Catching up with these limits can be a challenge.
Published: September 12, 2017.
Next post in Opinionated Tech story: FoundationDB is Back!
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.