SGR Examples
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
Let's go through a few examples that illustrate application of Schema-Guided Reasoning (SGR):
- simple math task
- text-to-sql
- document classification
- advanced reasoning in compliance
1. Simple Math Task
Here is an easy example with small reasoning customisation. Let's say we have the following Python classes:
class Step(BaseModel):
explanation: str
output: str
class MathReasoning(BaseModel):
steps: list[Step]
final_answer: str
Note, that BaseModel comes from pydantic typing library of Python, frequently used to define response formats. Other languages might leverage different libraries and tools for this purpose.
Given this MathReasoning response format and a prompt Solve the equation 8x + 7 = -23 step by step. LLM can respond like this:
{
"steps": [
{
"explanation": "Start with the equation 8x + 7 = -23.",
"output": "8x + 7 = -23"
},
{
"explanation": "Subtract 7 from both sides to isolate the term with the variable.",
"output": "8x = -23 - 7"
},
{
"explanation": "Simplify the right side of the equation.",
"output": "8x = -30"
},
{
"explanation": "Divide both sides by 8 to solve for x.",
"output": "x = -30 / 8"
},
{
"explanation": "Simplify the fraction.",
"output": "x = -15 / 4"
}
],
"final_answer": "x = -15 / 4"
}
Note, that it thinks in a predefined way before providing an answer. This uses more tokens by investing them to think through the problem aloud, but improves model accuracy.
2. Text-to-SQL example
In the real world, we would want to have more precise reasoning schema to boost answer accuracy. For example, when prompting LLM to perform query expansion from human request to a precise SQL query over a predefined schema, adding Schema-Guided Reasoning (SGR) increases the accuracy by 6% out of the box.
On the image below this was done by adding strategy field before the sql_query field. It forced LLM to perform analysis according to a custom checklist.
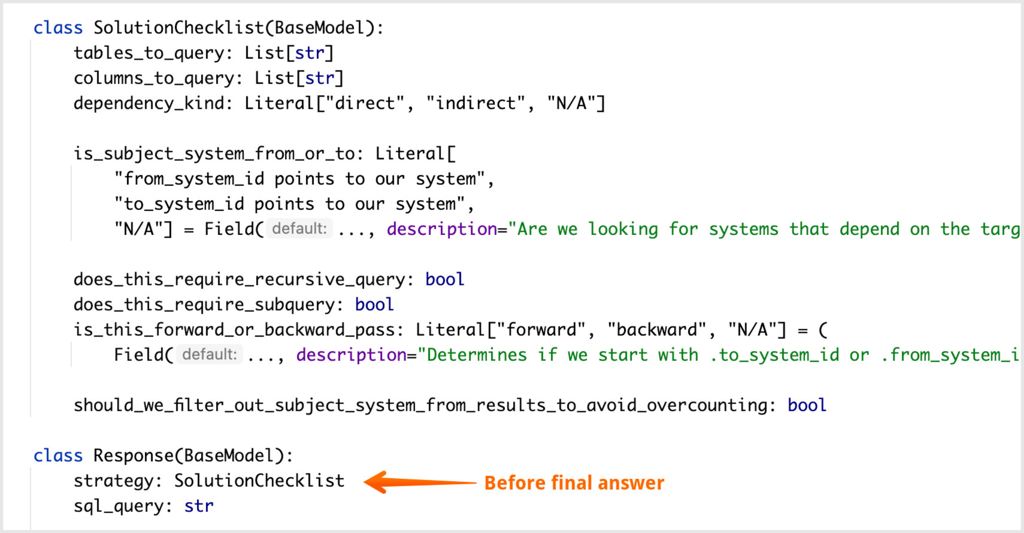
In essence, we programmed LLM to reason in a predefined way without writing any executable code.
3. Document classification example
Here is an example of a Schema-Guided Reasoning (SGR) from a system for classifying business documents in a RAG:
DOCUMENT_TYPES = ["invoice", "contract", "receipt", "email", ...]
ENTITY_TYPES = ["payment", "risk", "regulator", "employee", ...]
class DocumentClassification(BaseModel):
document_type: Literal[tuple(DOCUMENT_TYPES)]
brief_summary: str
key_entities_mentioned: List[Literal[tuple(ENTITY_TYPES)]]
keywords: List[str] = Field(..., description="Up to 10 keywords describing this document")
In this case, LLM is forced to think through the classification challenge in steps:
- Identify type of the document and pick it.
Literalenforces that. - Summarise the document
- Identify key entities mentioned in the document.
List[Literal]ensures that the response will be a list fromENTITY_TYPES - Come up with 10 unique keywords.
List[str]ensures that the response is a list of strings, while description kindly asks LLM to keep the list at 10 items or less.
In this specific example, first two fields are discarded from the response. They are used just to force LLM to approach classification from a predefined angle and think a little about it. Ultimately this improved prompt accuracy in this task.
4. Advanced Reasoning in Compliance
This is an example of more advanced workflow that is "packed" into a single prompt. While executing this schema, the model will be forced to go through that sequentially.
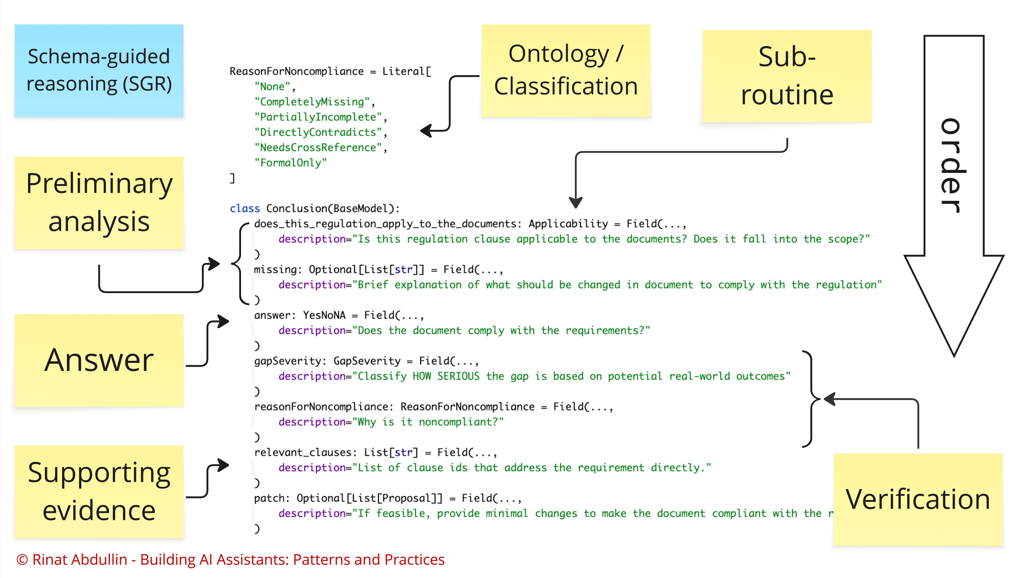
First, we are instructing the model to do preliminary analysis, where most of the analysis is encoded in Applicability reasoning sub-routine (it is implemented as a reusable nested object). The task is phrased explicitly in the field description and field name.
field name will get more attention from the model, because it will be copied to the output prompt by the model just before it starts answering the question.
Afterwards model has to reason about concrete gaps in the document. These gaps, represented as a list of strings, will be the mental notes that the model gathers before providing a final answer.
Note, that
descriptionfield is passed to the LLM automatically by OpenAI. Other providers might not include that.
The answer itself is a fairly straightforward ENUM of three options. However, the reasoning doesn't stop there. Benchmarking has shown that sometimes this reasoning workflow gets too pessimistic and flags too many gaps. To handle that, we are forcing a verification step after the answer:
reasonForNoncompliance- model has to pick a categorygapSeverity- also another list of categories
Information from these two fields is useful in 3 ways:
- allow to prioritise important gaps by assigning scores to each category
- allow to test classification precision with our test evals
- a model gets a chance to review, all the information again and mark the gap as valid, but less relevant.
And the final step is to list most important supporting evidence for the concrete identified gap. It happens in the same prompt because we already have all the information loaded in the context, so there is no need in second prompt.
Plus, supporting evidence is usually specified exactly by the unique identifiers of text chapters, clauses or snippets. This means, that we could also include this part of the reasoning into the test datasets that ensure quality of the overall system. It would look like this:
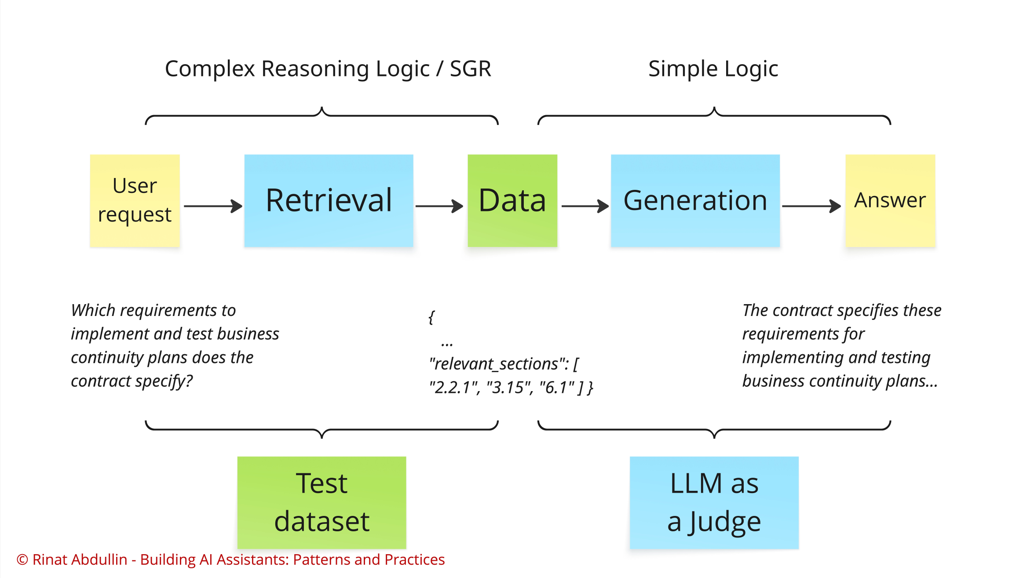
Q: how to apply that to test pure chat applications that have free text as response?
A: split prompt into SGR-controlled part and final text answer. Put most of the complexity and reasoning in SGR part, keep text interpretation trivial. Include grounding and proofs into SGR part as well (see ERC). Cover SGR schema fields with an eval dataset. Use LLM-as-a-judge or human oversight for testing the tail.
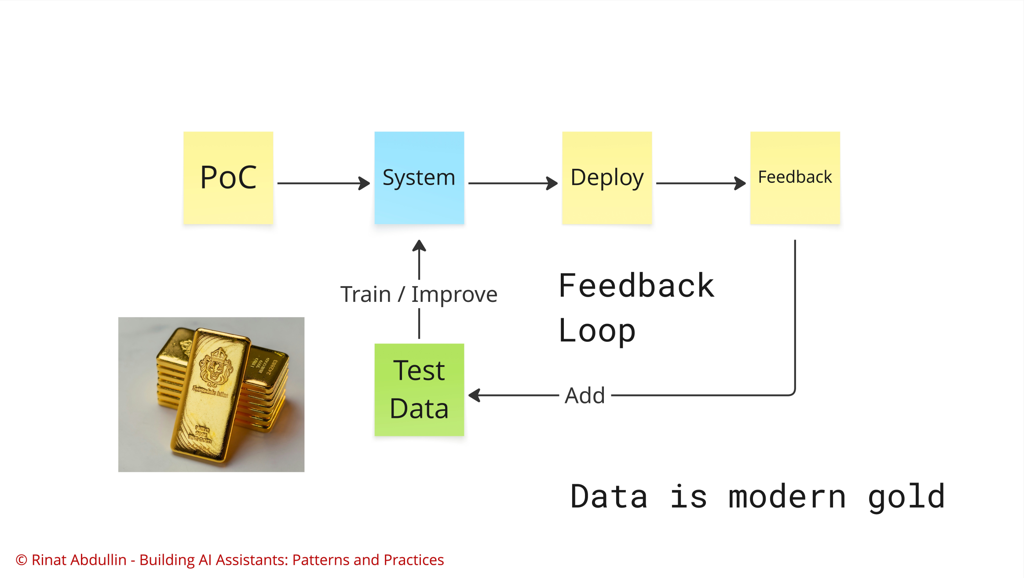
This way Schema-Guided Reasoning helps to establish faster the the feedback loops that generate valuable test data. This works because with SGR we get more easily-testable parameters per each reasoning process.
Next post in Ship with ChatGPT story: SGR Demo
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.