Lokad.CQRS Retrospective
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
Lokad.CQRS was a framework for building “complex” business applications running on Azure. It was born out of very limited experience and a desire to have CQRS/ES applications on Windows Azure. I knew only a few patterns back then and tried to use them to solve all possible domain problems.
Note: this article requires some previous painful experience with Lokad.CQRS. It wouldn’t make sense to you otherwise (which would be a good thing).
This approach worked to some extent. It provided an entry point to building relatively complex distributed systems that run on Windows Azure: hundreds of messages and views, dozens of aggregate roots.
At Lokad, we initially built Salescast and Hub with Lokad.CQRS. AgileHarbor delivered SkuVault with it. Many other projects used Lokad.CQRS entirely or reused some parts.
Over time, I discovered (in a painful way), that this specific approach had many limitations:
- Lokad.CQRS made developers focus on low-level implementation details, instead of high-level domain design.
- it allowed to quickly prototype a software solution, that would be painful to evolve and maintain afterwards.
- Implementations were tightly coupled to Windows Azure Storage.
- Approach didn't provide solutions for really important matters like testing, scalability, production logging and performance monitoring.
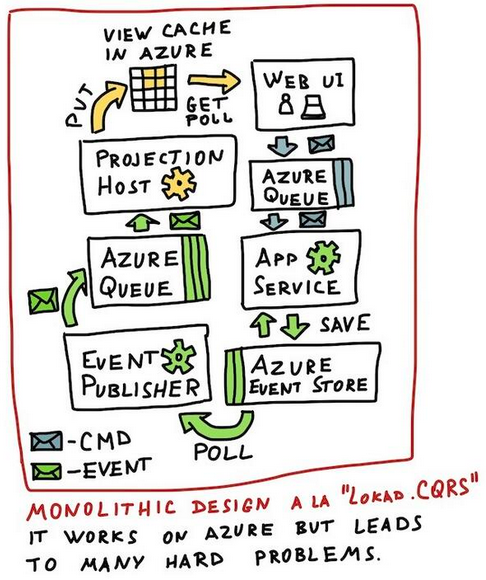
Let's go over the most painful parts!
Building Blocks
Lokad.CQRS focused on the idea of having a few “well-developed” building blocks. They provided abstractions for storage, messaging and event processing on Windows Azure.
Implementations could also be swapped to use local file system or memory, which allowed for faster development or testing (since Windows Azure Storage Emulator was horribly slow back then).
Business solutions were to be built out of these building blocks. As it turns out, the ability to swap different storage engines was the only good thing in here. However, even the implementations were very limiting and had many flaws.
More than that, the entire premise of developing universal building blocks upon which the different implementations were to be built - was wrong. We’ll talk about issues with the specifics blocks first, then we'll switch to the problems with the design approach.
Atomic Key-Value Storage
Atomic key-value storage allowed you to store documents by keys and perform atomic updates on them. It had multiple storage implementations: Windows Azure Storage, file system and memory storage. These could be swapped in and out via a configuration setting.
Search and indexing capabilities had to be created manually with this approach. Usually this was done by defining a single-key index document, which would be updated on every write.
This storage was very good for small projects and rapid prototyping. However, as the project grew, it was very easy to end up with millions of document instances with this approach.
Eventually somebody would want to do some bulk operation (like deleting all products for a tenant) and that’s where things would start breaking down:
- Azure storage (just like any other storage) has a latency for accessing individual blobs. Bulk operations would be slow even with async non-blocking operations.
- Bulk updates were never atomic with this storage. If something was to go wrong, the storage would end up in a very inconsistent state.
- While trying to read or write blobs in large bulks, Azure storage would start hitting scalability limits and time out. Some timeouts could be handled by retry policies, turning it into a very slow operation (e.g. hours) that might still eventually fail.
- As databases increased in size, so did many secondary indexes. Any change to the primary document was followed by an update to an index. This update could be slow or even fail, leading to an inconsistency in the data.
These days I’d try to avoid introducing such a limiting concept into the project, especially in data-intensive applications. It would be more efficient to pick a proven data storage technology (or a set of them) which fit the domain model very well, then let it handle all the bulk work.
By fitting well I mean ease of use and management, simplicity, predictability, ability to meet scalability and consistency requirements of the project.
Append-only storage
Append-only storage was another building block in Lokad.CQRS. It used Azure page blobs of 512KB to store information. Whenever a system restarted or the blob got filled, a new blob would be created.
There were also in-memory and file-based implementations of this storage, usable for demoing and local development.
This storage was mainly designed to work as an underlying transaction log for the event stores.
It worked well for short transaction logs (e.g. a few GBs), but turned out to be bad in large-scale production. Consider a realistic case of having 20GB of event history. If the store was optimally filled, it would have about 40960 of separate page blobs inside. Backing this storage up or simply enumerating might take some time.
Concurrency is another issue here. This append-only storage can only be written by a single writer (multiple readers are ok), so we can’t use one of the strongest parts of Azure - increasing the number of worker instances.
Message Vault
Message Vault came as a temporary replacement to the append-only storage. It is a dedicated transaction log storage library for Windows Azure. Files in 100MB chunks are used by default, master-follower setup is used for higher availability.
MessageVault is available on github.
This implementation isn’t perfect (e.g. if a master dies, there would be some delay before the follower starts accepting writes) or battle-tested in multiple projects. However it is a decent replacement for medium-size event-driven projects running on Windows Azure.
Larger projects could switch from MessageVault to Apache Kafka, which is a battle-tested distributed commit log. Semantically MessageVault is similar to Kafka (if used with infinite retention policy), so the migration should be rather straightforward.
Microsoft plans to introduce Azure Storage append blob, which might be able to replace MessageVault in companies limited to Microsoft stack.
Event Store
Lokad.CQRS featured its own Event Store. It was based on the append-only storage and used in-memory cache to load streams by their id. Atomic stream updates were also possible (using an in-memory locks).
In theory, this allowed for building apps with event-sourced aggregates. In practice, this specific implementation failed badly in production:
- Worker node would need to read the entire storage and cache it in memory on startup. That would take some CPU and RAM. Imagine an event store with 20GB of history.
- We can’t have multiple workers writing to the same event store, so the scalability and HA go out of the window.
- In-memory cache implementation wasn’t thought through. For example,
streams were stored in a structure like this
ConcurrentDictionary<string, IList<byte[]>>. Any .NET developer could tell you that storing millions of events here wouldn’t be the most memory-efficient approach.
View Projection Framework
View Projection Framework in Lokad.CQRS was responsible for replaying events from Event Store to rebuild read model (views) and keep it up-to-date. It used atomic storage to persist views and smart logic to detect code changes that would require a total replay.
That description should already hint at the problems:
-
Any kind of replay would be slow, since it ends up with saving thousands of views to Azure Storage, which might not be able to handle the spike.
-
Change detection logic was smart and hard to reason about. It still didn’t catch all changes, forcing developers to change code of some projections by hand, just to trigger a rebuild (adding
ToString()overload was the most frequent choice). -
The framework “encouraged” building a lot of different views without thinking twice. These views could have thousands of documents each (or really large partitioned dictionaries). To speed up the replay in such situations, the framework cached all documents in memory. That used a lot of RAM, as soon as you exhausted it (and the system starts hitting the page file), your replay process would be doomed (unless waiting for a few days is ok for you).
A workaround for RAM starvation on replay in Azure would be to provision a large Worker Role just for the duration of the replay process (e.g. 112GB RAM is required sometimes), which isn’t a good thing for many reasons.
Code DSL for Message Contracts
Lokad Code DSL was a sister tool, frequently used in projects that were based on Lokad.CQRS. It generated proper message contracts on-the-fly out of the compact definition files.
For example, this code:
AddSecurityPassword?(
SecurityId id,
string displayName,
string login,
string password
)
would turn into this C# class on-the-fly:
[DataContract(Namespace = "Sample")]
public partial class AddSecurityPassword : ICommand<SecurityId>
{
[DataMember(Order = 1)] public SecurityId Id { get; private set; }
[DataMember(Order = 2)] public string DisplayName { get; private set; }
[DataMember(Order = 3)] public string Login { get; private set; }
[DataMember(Order = 4)] public string Password { get; private set; }
AddSecurityPassword () {}
public AddSecurityPassword (SecurityId id, string displayName, string login, string password)
{
Id = id;
DisplayName = displayName;
Login = login;
Password = password;
}
}
Magic!
Back then I believed that code generation was generally bad, but this case was an exception. After all, nothing should stand in the way of a developer creating new events.
As it turns out, this case was definitely bad. Lokad.DSL allowed you to create event and command message definitions really fast, without thinking too hard about them. This was very wrong, as I learned later.
Message contracts are one of the most important aspects of the design, as part of an API they touch multiple contexts. Badly designed message contract could poison all codebases it touches.
To make things more difficult, a badly designed event contract could mess up an event-sourced system for years.
Another (rather mild) drawback of code DSL was that it made it harder to tweak and customize message contracts for very specific scenarios.
These days, instead of relying on any sort of code generation, I prefer to take my time and write the entire contract by hand. Contracts are a very important part of the design, they deserve the attention.
One-Way Messaging
Lokad.CQRS also featured a one-way messaging framework, using Azure Queues or the file system. The implementation grew to be rather robust with features like deduplication, quarantines and retries.
As a part of Lokad.CQRS, that implementation was misused very badly. This misuse stemmed from my lack of understanding and experience. Here is the worst bit:
I advised developers to let different systems communicate by pushing one-way commands to each other. Whenever a system wanted to know about the result of the operation, it had to poll a view which would eventually contain the outcome of an operation. A client (e.g. web UI) had to also follow these rules.
In theory, this made the systems more robust in the face of failure (especially, if you used Azure queues for the communication and azure blobs for view persistence). In practice, this complicated everything a lot.
Simple operations that need to know about the outcome of an operation (e.g. adding a user) would require a lot of boilerplate code: events, views, view projection logic, async logic for polling these views till the result arrives.
Repeat that many times and you get:
- a lot of very fragile code;
- component communication via data (key-value views), which is a very fragile integration point;
- codebase, where adding a single feature requires changing half a dozen of files or more,
- chatty implementation which talks to Azure Storage a lot. Any moderate load on a busy day is likely to hit a scalability limit, causing timeouts and failures.
These days, I prefer to start by using Remote procedure calls (e.g. by exposing an HTTP API) for the majority of client-server communications. These are easy to reason about and easy to use.
The entire WWW works with RPC and HTTP API. And that is the most complex and scaled distributed system in the world.
If there is a justified need for messaging in the project, then I’d try to use an existing and time-proven solution instead of rolling my own. Apache Kafka and RabbitMQ are among the ones that seem to excel at large scales.
As for eventual consistency and versioning, these can be easily solved
with well-designed RESTful APIs ExpectedVersion HTTP Header and
browser-level retries.
Failure of the Building Blocks
Out of these building blocks, append-only storage is the only one I still use these days. All the other building blocks either have a lot of issues with them or aren't that useful. That essentially renders the entire Lokad.CQRS useless and plain harmful.
The high-level design problem here was in trying to limit an implementation to a few known possible choices. It is the same as telling people: “I don’t know what you are trying to build, but here are tools and materials for that. By the way, be gentle with that sledgehammer, it could break, if twisted clockwise”.
This is a constraining approach which can lead to a lot of technical debt in later stages of the project.
Design Lessons
Lokad.CQRS was created with a very short-sighted design approach in mind, a reusable LEGO constructor.
These days I'd try to limit the damage I inflict upon the developers and avoid writing any widely reusable frameworks. They come with too much responsibility.
At most I'd help to setup a design and development process in a single project or a company:
- Align design with tools and solutions that already exist out there.
- Focus on high-level design, testability and integration, while deferring implementation details.
- Provide developers with means to understand how their implementation behaves in production, allow to optimize it and scale.
- Allow developers to switch between different tools and clouds, instead of coupling them to a single cloud provider.
- While working on the design, start by decomposing the solution into separate contexts, identifying the boundaries and capturing them in the code.
Code-wise that can be expressed as:
-
Light project-specific framework for defining backend modules with an API. Implementation has to be aligned with well-established frameworks like: Scala Play, Node.js express or .NET Nancy.
-
Tooling to write use-cases for these modules in a coherent and non-fragile way (event-driven use-cases), verify behavior against the working code, and print them as human-readable documentation. There is an example of that in omni project.
-
Examples of high-level sanity checks that protect code from hacks and rash decisions that are easy to catch. These could be run locally or on an integration server (using code introspection and information captured from the use-cases).
-
Tooling to render human-readable API documentation with samples out of the use-cases, embeddable into the API itself. This is similar to the work we did at the HappyPancake (HPC) project.
-
Make it easy for developers to gather telemetry from the systems running on dev, qa and production environments on many servers. That would include real-time performance metrics and structural logging (Serilog and StatsdClient). Provide guidelines for capturing information, along with the docker image for setting up a production-worthy Linux server for aggregating this data and displaying it.
-
Provide guidance for developers on how to deploy changes to dev and QA environment (with continuous delivery), how to handle production upgrades.
-
Provide tooling that would involve managers and QA people in the software development process. Expose specifications, real-time behavior, and system design to them via: rendering use-cases to human-readable specifications, allowing QA people to define new use-cases, providing audit logs from the running system in the same language as the use-cases.
-
Infrastructure and guidance to developers for developing client applications on various platforms (where this is applicable), train and help them find solutions to their problems.
-
Ideally, provide examples of setup for high-availability deployments, using existing solutions from the real-world (e.g. nginx for load-balancing, ZooKeeper/Basho Core/etcd for managing the cluster state, Apache Kafka for high-throughput event bus).
This list is by no means exhaustive. I didn't cover things like A/B testing, development workflow, feature toggling and deployments, integration and unit-testing, stress testing, handling on-premise deployments and many more.
However, none of that was even considered in Lokad.CQRS. So that, in retrospective, should give you an idea of how lacking and bad that framework was.
Summary
So, Lokad.CQRS was a big mistake of mine. I'm really sorry if you were affected by it in a bad way.
Hopefully, this recollection of my mistakes either provided you with some insights or simply entertained.
Published: June 16, 2015.
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.