How to segment texts for embeddings?
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
Let's say you want to build an information storage and retrieval system.
There are two major options for retrieving text and documents:
- full-text search, similar to how Elastic or Lucene do it. You need to know the words in order to find the answer.
- similarity search, that is based on embeddings and vector databases.
Products built with ChatGPT and the other LLMs mostly use similarity search with embeddings, because it finds correct information even if you didn't guess the write words. Results also tend to be better. We'll focus on that approach.
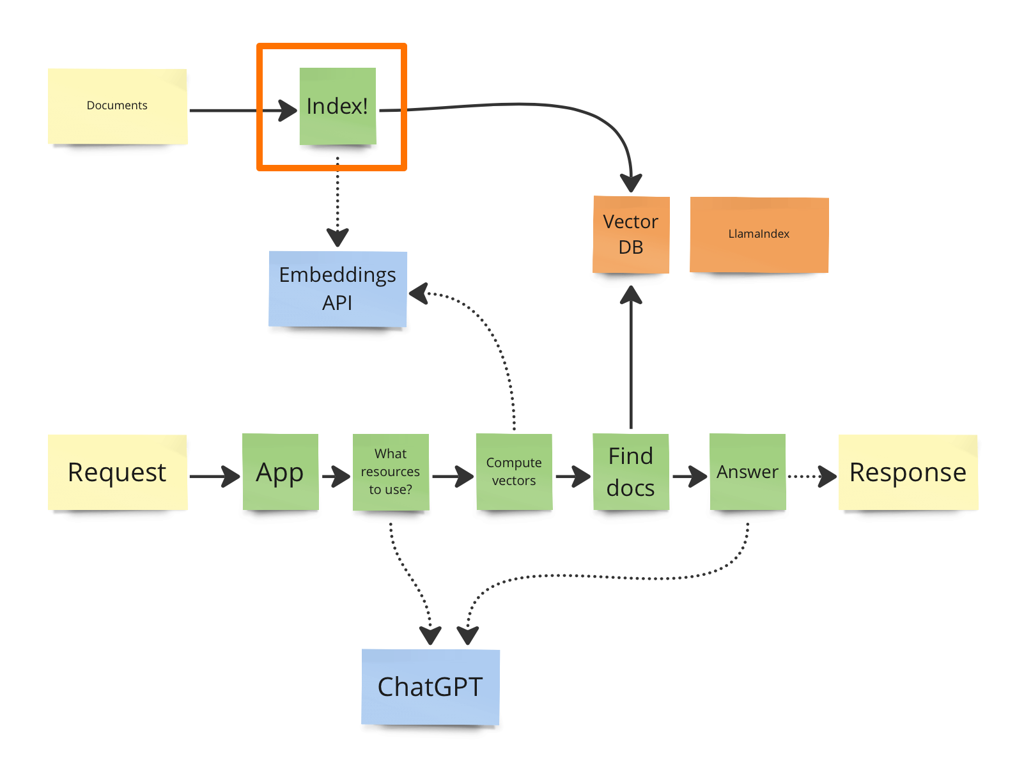
So how do we compute embeddings for a text? Normally we split the text into smaller chunks, compute embeddings for each and then store everything in a vector database.
How to split text for embeddings? The answer depends on each specific domain. Your basic options are:
- split by paragraphs
- split by sentences
- split by N words, letters or tokens.
You can also use a sliding window approach, where each chunk includes a portion of the previous chunk.
More advanced options for calculating embeddings:
- Summarise chunks
- Extract possible questions or keywords with LLMs
You can also check out LlamaIndex for samples of specialised indices that include:
- List index - just a sequential chain
- Vector store index - storing embeddings in a dedicated DB and retrieving top-k most similar node
- Tree index - hierarchical tree with traversal
- Keyword table index - extracts keywords from each node (text chunk) and builds a mapping
- Knowledge graph index
LlamaIndex plugs into LangChain, making it easier to integrate language models with rich information retrieval.
Once you have indexed your corpus in a vector DB with some index, you could pass control to a LLM for answering questions. Here is an example of the prompt chain for a ChatGPT:
You need to answer question of a user. List phrases to search for with top-k similarity search in order to answer the question. Question follow.You need to answer question of a user. Information retrieval got these X chunks. Provide an answer nowUser liked answer to the question X, provide a list of additional keywords for retrieving this answer in similar scenarios
Here is a good example of how things could work together beautifully in a single prototype: twitter.
Success will depend on domain-specific factors in each case: prompts, terminology, information indexing and retrieval strategies. Experiment!
Published: April 18, 2023.
Next post in Ship with ChatGPT story: How to talk to your knowledge base?
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.