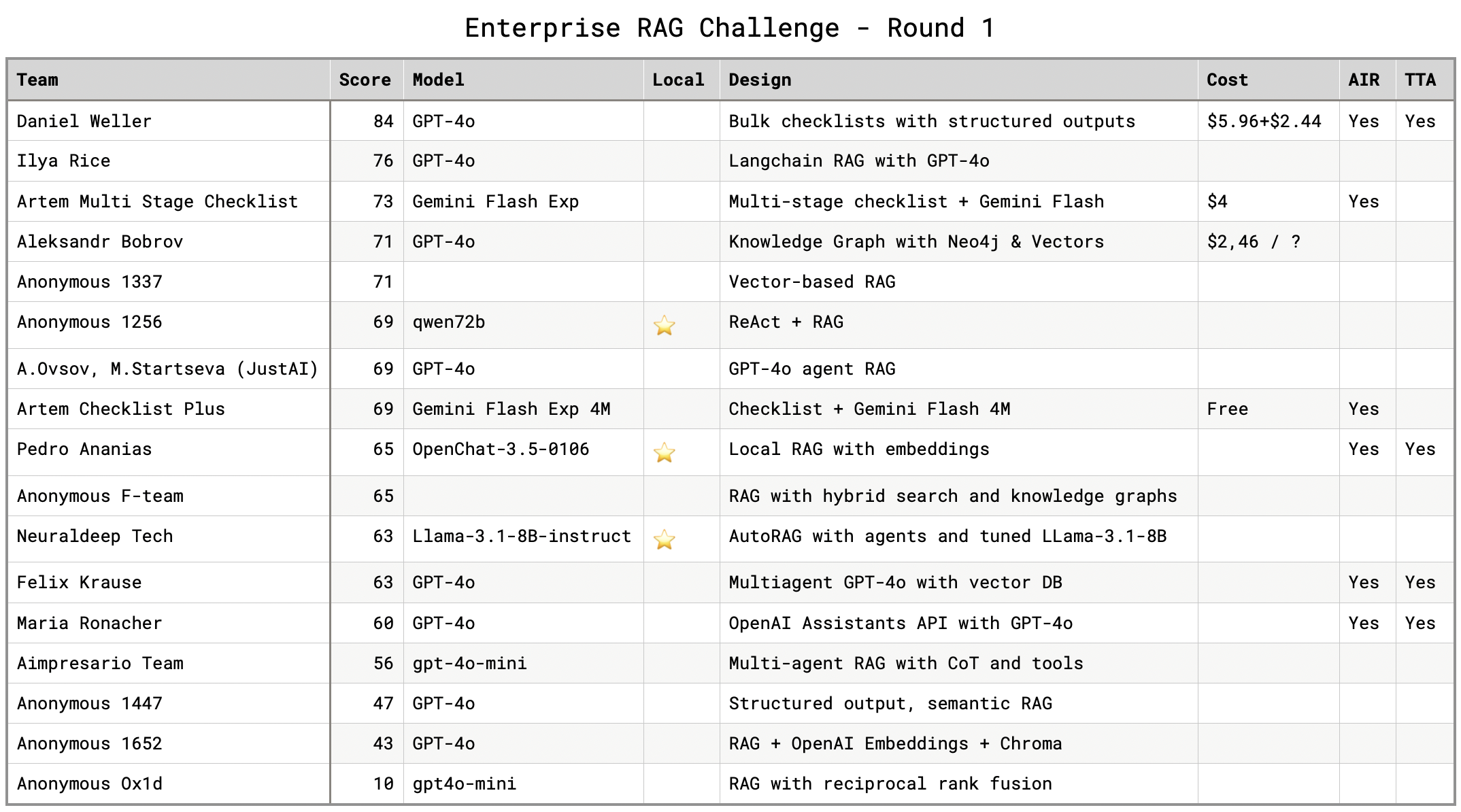
| 1. ▶Ilia Ris 🤗 |
49 min |
83/81 |
123.7 |
Ilya Rice
Models used:
Architecture
Ilya Rice solved the problem by making it easy to run numerous experiments before the competition has even started. He created an evaluation pipeline that let him quickly evaluate different architectural solutions. The best solution was also among the fastest ones.
The winning experiment had this configuration:
- PDF Analysis: Documents are processed using a highly modified Docling Library from IBM. Modifications were needed to preserve page references.
- Router Pattern: First step in question answering flow picks the most suitable agent.
- Dense Retrieval: The system searches for relevant information based on semantic similarity (FAISS library and OpenAI vector embeddings).
- Parent Document Retrieval: Instead of retrieving only the chunk, full page is loaded to preserve relevant context.
- LLM Reranking: Retrieved information is re-evaluated and reordered by the LLM.
- Reasoning Patterns: Improve LLM accuracy within a single prompt by controlling its thinking process with Custom Chain-of-Thought and Structured Outputs.
- Final Answer generation: The optimized result is generated using o3-mini.
- Self-Consistency with Majority Vote: Multiple answer variations are generated, compared, and the most consistent one is selected.
R&D Experiments
Total experiments submitted: 11
Other approaches:
- Dense Retrieval; LLM Reranking; Router; SO CoT; o3-mini
- Dense Retrieval; Router; SO CoT; llama3.3-70b
- Dense Retrieval; Tables serialization; Router; LLM reranking; o3-mini
- Dense Retrieval; llama-3.3 70b
- Dense Retrieval; llama-3.1 8b
- Full Context; gemini-2.0 thinking
- Dense Retrieval; Router; LLM reranking; Self-Consistency; o3-mini
- Dense Retrieval; Router; LLM reranking; Self-Consistency; llama-3.3 70b
What didn't work?
- Using llama-3.1 8b for reranking
- Incorporating Full Context with gemini-2.0 thinking
Future experiments:
- Evaluating various local embedding models for fully offline solutions
Experiment journal:
- 16 min → R: 83.9, G: 72.8, Score: 114.8 ▲ - Dense Retrieval; LLM Reranking; Router; SO CoT; o3-mini
- 23 min → R: 81.4, G: 74.7, Score: 115.4 ▲ - Dense Retrieval; llama-3.3 70b
- 49 min → R: 83.8, G: 81.8, Score: 123.7 ▲ - Dense Retrieval; Router; LLM reranking; o3-mini
- 50 min → R: 81.1, G: 68.7, Score: 109.3 - Dense Retrieval; llama-3.1 8b
- 51 min → R: 75.5, G: 75.0, Score: 112.8 - Full Context; gemini-2.0 thinking
- 66 min → R: 83.0, G: 78.8, Score: 120.3 - Dense Retrieval; Tables serialization; Router; LLM reranking; o3-mini
- 22 hours → R: 83.5, G: 81.8, Score: 123.6 - Dense Retrieval; Router; LLM reranking; o3-mini
- 22 hours → R: 80.8, G: 75.7, Score: 116.1 - Dense Retrieval; llama-3.3 70b
- 33 hours → R: 83.4, G: 79.8, Score: 121.6 - Dense Retrieval; Router; LLM reranking; Self-Consistency; o3-mini
- 33 hours → R: 81.3, G: 79.7, Score: 120.3 - Dense Retrieval; Router; LLM reranking; Self-Consistency; llama-3.3 70b
|
| 2. ▶Emil Shagiev 🤗 |
55 min |
86/78 |
121.6 |
Emil Shagiev
- Best experiment: LLM_Search
- Signature:
0a8782
- Summary: A multi-step process involving query expansion, efficient search, question answering, and answer finalization.
Models used:
- gpt-4o-mini-2024-07-18
- gpt-4o-2024-08-06
- o3-mini-2025-01-31
Architecture
The best solution didn't use vector embeddings, it leveraged a structured approach:
- the input query is expanded to enhance search coverage and enable semantic search;
- relevant pages are retrieved using a cost-effective and rapid LLM;
- retrieved information is then passed to powerful LLM to generate answers;
- answers are refined and finalized for presentation.
R&D Experiments
Total experiments submitted: 3
Other approaches:
- LLL_Search_2: Similar architecture with added capability for mathematical operations.
Experiment journal:
- 55 min → R: 86.3, G: 78.5, Score: 121.6 ▲ - LLM_Search
- 21 hours → R: 86.1, G: 77.5, Score: 120.5 - LLL_Search_2
|
| 3. ▶Dmitry Buykin 🤗 |
8 hours |
81/76 |
117.5 |
Dmitry Buykin
- Best experiment: Dynamic Structured Output with SEC EDGAR Ontologies
- Signature:
6b0d78
- Summary: Dynamic structured output with query expansion and page-focused chunking.
Models used:
Architecture
Used SO/CoT approach with ontologies to retrieve relevant information.
Key highlights:
- embeddings and vector databases were not used;
- dynamic structured output approach combined with SEC EDGAR ontologies for query expansion (SO CoT);
- utilized CBOW similarity for majority selection across multiple runs, focusing on balancing pages versus tokens during chunking
- significant effort was dedicated to evaluating PDF quality heuristics to optimize OCR input
- synthetic tags were implemented to stabilize page detection and assess model quality.
|
| 4. ▶Sergey Nikonov 🤗 |
30 hours |
85/73 |
116.4 |
Sergey Nikonov
- Best experiment: main v2
- Signature:
00c0e1
- Summary: For every question, all pages are processed using gpt-4o.
Models used:
Architecture
Solution involves feeding all pages of the provided documents into the gpt-4o model for each question. This simple but practical approach ensures comprehensive coverage of the content to extract accurate answers.
R&D Experiments
Total experiments submitted: 2
Other approaches:
- Finding the PDFs that correspond to questions, cutting the PDFs by page, running the question against each PDF page by loading the PDF directly into gpt-4o (through the assistant API), scanning all PDF pages for the answer, and combining the answers by simple logic.
What didn't work?
- Using the o3-mini model instead of o1-mini in the architecture.
Experiment journal:
- 5 hours → R: 85.3, G: 69.0, Score: 111.6 ▲ - Main
- 30 hours → R: 85.1, G: 73.9, Score: 116.4 ▲ - main v2
|
| 5. ▶ScrapeNinja.net 🤗 |
23 hours |
82/71 |
112.5 |
ScrapeNinja.net
- Best experiment: fixed multiple companies search
- Signature:
417bbf
- Summary: Node.js-based architecture utilizing pgvector for efficient data handling.
Models used:
- Gemini Flash 2.0
- Gemini Flash Lite 2.0
- Flash Thinking Exp
Architecture
The solution used Node.js for backend operations and pgvector for vectorized data processing. It focused on efficient handling of complex queries and data retrieval tasks.
The team utilized:
- Gemini Flash 2.0
- Gemini Flash Lite 2.0
- Flash Thinking Exp.
R&D Experiments
Total experiments submitted: 2
Other approaches:
Experiment journal:
- 20 hours → R: 82.6, G: 64.2, Score: 105.5 ▲ - OCR and PG
- 23 hours → R: 82.6, G: 71.2, Score: 112.5 ▲ - fixed multiple companies search
|
| 6. ▶xsl777 🤗 |
16 hours |
79/71 |
110.9 |
xsl777
- Best experiment: multi-query, gpt-4o
- Signature:
66ab5c
- Summary: Structured PDF parsing, metadata extraction, query expansion, hybrid search, reranking, and CoT.
Models used:
Architecture
The architecture integrates following patterns:
- structured PDF parsing and chunking;
- metadata extraction;
- query expansion;
- hybrid search mechanisms;
- reranking strategies.
It synthesizes document metadata and chunks while utilizing Chain-of-Thought (CoT) reasoning to enhance response accuracy and relevance. gpt-4o and gpt-4o-mini help with high-quality language understanding and generation capabilities.
R&D Experiments
Total experiments submitted: 2
Experiment journal:
- 16 hours → R: 79.4, G: 71.2, Score: 110.9 ▲ - multi-query, gpt-4o
- 3 days → R: 80.1, G: 70.7, Score: 110.7 - Open source, Advanced RAG
|
| 7. ▶nikolay_sheyko(grably.tech) 🤗 |
25 hours |
81/69 |
110.4 |
nikolay_sheyko(grably.tech)
- Best experiment: nikolay_sheyko(grably.tech)_with_o3_mini
- Signature:
db8938
- Summary: Relevant pages are identified and processed to generate answers.
Models used:
Architecture
The solution employs a two-step process:
- first, it identifies relevant reports for a given question and evaluates the relevance of each page asynchronously using the gpt-4o-mini model;
- then , all relevant pages are compiled into a prompt, and the o3-mini model is utilized to generate the final answer.
R&D Experiments
Total experiments submitted: 7
Other approaches:
- Dynamic data extraction with pydantic classes
- Binary checks per page
- Parallel question splitting
- Subquestion generation for multi-entity queries
- Single-page reference experiments
What didn't work?
- Binary checks per page
- Single-page reference experiments
Experiment journal:
- 55 min → R: 77.2, G: 51.2, Score: 89.9 ▲ - grably.tech/with_extra_reasoning_from_different_pages_hacked96160725
- 25 hours → R: 81.1, G: 69.8, Score: 110.4 ▲ - nikolay_sheyko(grably.tech)_with_o3_mini
- 25 hours → R: 79.7, G: 60.2, Score: 100.1 - nikolay_sheyko(grably.tech)_dummy
- 8 days → R: 80.5, G: 64.3, Score: 104.6 - o3-mini-no-restrictions
- 8 days → R: 80.5, G: 66.3, Score: 106.6 - o3-mini-no-restrictions-fixed-names
- 12 days → R: 81.2, G: 67.1, Score: 107.7 - o3-mini-no-restrictions-single-reference
- 12 days → R: 80.5, G: 67.3, Score: 107.6 - o3-mini-no-restrictions-fixed-names-and-boolean
|
| 8. ▶Felix-TAT 🤗 |
7 days |
80/69 |
109.4 |
Felix-TAT
- Best experiment: Gemini-4o Multiagent RAG
- Signature:
a2faff
- Summary: Multiagent, mixed-model approach with delegation and execution agents.
Models used:
- gemini-2.0-flash
- gpt-4o-2024-08-06
Architecture
The solution uses a multiagent architecture where a delegation manager (OpenAI) splits the user query into company-specific subqueries. These subqueries are processed by expert agents using Google's Gemini flash model, which has access to the entire company PDF in context. The responses are then aggregated and synthesized by an execution agent (OpenAI) to produce the final answer.
R&D Experiments
Total experiments submitted: 4
Other approaches:
- Gemini Naive
- IBM-4o-based Multiagent RAG
- OpenAI Multiagent RAG
What didn't work?
- Using a single model without multiagent delegation
- Relying solely on vector database retrieval without full PDF context
Experiment journal:
- 6 days → R: 79.0, G: 60.3, Score: 99.8 ▲ - Gemini Naive
- 7 days → R: 81.7, G: 47.3, Score: 88.2 - IBM-4o-based Multiagent RAG
- 7 days → R: 82.2, G: 66.0, Score: 107.1 ▲ - OpenAI Multiagent RAG
- 7 days → R: 80.2, G: 69.3, Score: 109.4 ▲ - Gemini-4o Multiagent RAG
|
| 9. ▶A.Rasskazov/V.Kalesnikau |
30 hours |
84/67 |
109.3 |
A.Rasskazov/V.Kalesnikau
- Best experiment: multi_agent_ibm_openai
- Signature:
efabd4
- Summary: A multi-agent system leveraging LLMs for question answering using similarity-based retrieval.
Models used:
- meta-llama/llama-3-405b-instruct
- ibm/granite-embedding-107m-multilingual
- text-embedding-3-small
- gpt-4o-mini
Architecture
The solution employs a multi-agent architecture to address the challenge.
Initially, it generates a database for the Retrieval-Augmented Generation (RAG) model. Upon receiving a query, the system extracts key metrics such as company, industry, and currency. These metrics are then used to identify the most similar question in the database. The answer associated with this similar question is retrieved and refined using a Large Language Model (LLM). Finally, the system consolidates and presents the answer to the user.
R&D Experiments
Total experiments submitted: 2
Other approaches:
- pjatk_team_002: A system that preprocesses questions, retrieves relevant PDF pages using a vector database, and extracts answers with page references using LLMs.
What didn't work?
- Alternative embedding models for retrieval.
- Different strategies for key metric extraction.
Experiment journal:
- 30 hours → R: 84.0, G: 67.2, Score: 109.3 ▲ - multi_agent_ibm_openai
- 7 days → R: 82.5, G: 64.0, Score: 105.2 - pjatk_team_002
|
| 10. ▶Dany the creator 🤗 |
3 hours |
82/67 |
108.4 |
Dany the creator
- Best experiment: gpt-4o-mini + pgvector
- Signature:
ee29ae
- Summary: Utilized a structured approach to parse and analyze text chunks, creating embeddings and generating questions.
Models used:
Architecture
The solution preprocesses text by chunking, generating embeddings with pgvector library, and formulating questions that could be answered by the respective chunks.
|
| 11. ▶SergC 🤗 |
7 days |
77/69 |
108.1 |
SergC
- Best experiment: submission_1
- Signature:
c0d776
- Summary: QE + SO + CoT
Models used:
Architecture
The solution uses a combination of:
- Query Expansion (QE)
- Semantic Optimization (SO)
- Chain of Thought (CoT) reasoning to enhance the performance of the Gemini 2.0 model.
|
| 12. ▶Swisscom Innovation Lab 🔒 |
21 hours |
83/66 |
107.8 |
Swisscom Innovation Lab
- Best experiment: Multi-Agent Langgraph-Llamaindex-MarkerPDF-Llama3.3
- Signature:
debcf6
- Summary: A multi-agent system leveraging LangGraph, LlamaIndex, MarkerPDF, and Llama 3.3 for accurate and contextual multi-company query processing.
Models used:
Architecture
This offline solution uses a multi-agent architecture with:
- LangGraph for workflow orchestration
- LlamaIndex for data indexing
- MarkerPDF for document parsing
- Llama 3.3 for natural language processing.
Solution supports multi-company queries by:
- extracting relevant entities
- validating inputs
- processing each entity individually
- retrieving and evaluating documents
- aggregating results for numeric-based comparisons.
R&D Experiments
Total experiments submitted: 3
Other approaches:
- Iterative refinement of query processing pipeline
- Enhanced document retrieval mechanisms
What didn't work?
- Simplified single-agent architecture
- Direct query-to-response mapping without intermediate validation
Experiment journal:
- 80 min → R: 83.3, G: 65.2, Score: 106.8 ▲ - Multi-Agent Langgraph-Llamaindex-MarkerPDF-Llama3.3
- 21 hours → R: 83.3, G: 66.2, Score: 107.8 ▲ - Multi-Agent Langgraph-Llamaindex-MarkerPDF-Llama3.3
|
| 13. ▶fomih 🤗 |
10 days |
83/65 |
107.4 |
fomih
- Best experiment: gemini-flash CoT with question type detection fixes
- Signature:
60bc28
- Summary: Enhanced question type detection for improved accuracy.
Models used:
Architecture
The solution utilized the gemini-flash 2.0 model, incorporating a refined approach to question type detection. This enhancement aimed to improve the accuracy and relevance of the responses generated by the system. The architecture involved preprocessing input documents into structured formats, creating knowledge bases tailored to specific question types, and leveraging these resources during the question-answering phase. The system identified the question type and relevant entities, retrieved pertinent knowledge base entries, and generated answers by combining the question with the retrieved data.
R&D Experiments
Total experiments submitted: 4
Other approaches:
- gemini-flash CoT with structured output
- gemini-flash CoT with structured output and small fixes
- gemini CoT with structured output final
What didn't work?
- Initial handling of 'n/a' cases
- Fallback processing without structured knowledge bases
Experiment journal:
- 10 days → R: 83.2, G: 59.9, Score: 101.5 ▲ - _gemini-flash CoT + structured output _
- 10 days → R: 82.9, G: 62.8, Score: 104.3 ▲ - gemini-flash CoT + structured output small n/a handling fixex
- 10 days → R: 83.0, G: 65.9, Score: 107.4 ▲ - gemini-flash CoT + so small fixes in question type detection
- 12 days → R: 83.3, G: 64.4, Score: 106.1 - gemini CoT + SO final
|
| 14. ▶Al Bo |
12 days |
81/65 |
105.9 |
Al Bo
- Best experiment: albo
- Signature:
1e89b6
- Summary: Docling, Vector, Agent with search tool into documents
Models used:
Architecture
The solution utilized a sophisticated architecture combining document processing (Docling), vector-based representation, and an agent equipped with a search tool for document retrieval.
|
| 15. ▶NumericalArt |
8 days |
70/70 |
105.3 |
NumericalArt
- Best experiment: Vhck-R0-002
- Signature:
32aae7
- Summary: Preprocessing questions, raw retrieval, filtering, retrieval, detailed page analysis, and answer generation.
Models used:
Architecture
The best employs a structured approach to information retrieval and answer generation. The process begins with preprocessing the input questions to enhance clarity and relevance. This is followed by an initial raw retrieval phase to gather potential information sources. Subsequently, a filtering mechanism is applied to refine the retrieved data. The refined data undergoes a detailed page analysis to extract precise and contextually relevant information. Finally, the system generates answers based on the analyzed data, leveraging the capabilities of the LLM models 4o-mini, 4o, and 3o-mini.
R&D Experiments
Total experiments submitted: 2
Other approaches:
- Parsing text from PDFs only, separate VDB for each document, one chunk equals one page, extract four pages by entity value from question (excluding company name), detailed parsing of extracted pages, asking LLM question with detailed information in context.
Experiment journal:
- 7 days → R: 75.9, G: 63.3, Score: 101.3 ▲ - Vhck-R0
- 8 days → R: 70.0, G: 70.3, Score: 105.3 ▲ - Vhck-R0-002
|
| 16. ▶Pedro Ananias 🤗 |
4 hours |
80/64 |
104.9 |
Pedro Ananias
- Best experiment: rag-3w-cot-gpt-4o-mini
- Signature:
d44b72
- Summary: A 3-way FAISS MMR Search & Stepped Chain Of Thought RAG
Models used:
Architecture
The solution uses a 3-way FAISS MMR Search mechanism combined with a Chain Of Thought (CoT) approach.
FAISS MMR Search involves query expansion, file selection based on exact matches and cosine similarity, and database searching using maximum marginal relevance.
CoT pipeline consists of three sequential model calls with specific prompts for reasoning, formatting, and parsing. This architecture leverages the openai/gpt-4o-mini model for processing.
R&D Experiments
Total experiments submitted: 5
Other approaches:
- rag-3w-cot-gpt-4o-mini-hi-res
- rag-3w-cot-deepseek-r1-distill-llama-8B-fast-fp16
- rag-3w-cot-deepseek-r1-distill-llama-8B-hi-res-fp16
- rag-3w-cot-microsoft-phi4-14B-hi-res-int8
What didn't work?
- Using lower resolution PDF extraction for certain tasks
- Employing fully local processing without cloud integration in some scenarios
Experiment journal:
- 4 hours → R: 80.4, G: 64.7, Score: 104.9 ▲ - rag-3w-cot-gpt-4o-mini
- 9 hours → R: 70.6, G: 56.0, Score: 91.3 - rag-3w-cot-deepseek-r1-distill-llama-8B-fast-fp16
- 9 hours → R: 77.0, G: 64.6, Score: 103.1 - rag-3w-cot-gpt-4o-mini-hi-res
- 11 hours → R: 72.3, G: 58.0, Score: 94.2 - rag-3w-cot-deepseek-r1-distill-llama-8B-hi-res-fp16
- 31 hours → R: 78.1, G: 59.7, Score: 98.7 - rag-3w-cot-microsoft-phi4-14B-hi-res-int8
|
| 17. ▶Daniyar |
3 days |
62/72 |
104.1 |
Daniyar
- Best experiment: Fixed reference page indices
- Signature:
8bb723
- Summary: The architecture utilizes fixed reference page indices for efficient information retrieval.
Models used:
Architecture
Solution uses a strategy of fixed reference page indices to enhance the accuracy and efficiency of document parsing and question answering.
This approach ensures that the model can quickly locate and utilize relevant information from the provided documents, leveraging the capabilities of the GPT-4o model.
R&D Experiments
Total experiments submitted: 2
Other approaches:
- Sliding window PDF page reading with checklists over questions addressed to files.
What didn't work?
- Alternative indexing methods or dynamic page referencing strategies.
Experiment journal:
- 3 days → R: 62.2, G: 72.9, Score: 104.0 ▲ - First draft
- 3 days → R: 62.4, G: 72.9, Score: 104.1 ▲ - Fixed reference page indices
|
| 18. ▶RubberduckLabs 🔒 |
2 days |
74/66 |
103.3 |
RubberduckLabs
- Best experiment: RubberduckLabs - RAG experiment attempt 001
- Signature:
ee7519
- Summary: A multi-step LLM processing pipeline for document question-answering.
Models used:
- deepseek-r1-distill-llama-70b:bf16
- llama-3.1-70b-instruct:bf16
Architecture
The architecture preprocesses documents to generate detailed page-level summaries and extracting structured metadata, particularly focusing on financial data.
The retrieval process employs a two-stage approach:
- document selection based on metadata matching;
- precise page identification using semantic relevance and explicit reasoning.
Answer generation utilizes 'Context-Guided Response Generation' combining retrieved contexts with structured reasoning to ensure factual accuracy and traceability. The system maintains explicit reasoning trails and incorporates robust error handling for production stability.
R&D Experiments
Total experiments submitted: 2
|
| 19. ▶Machine Learning Reply |
28 hours |
74/66 |
103.2 |
Machine Learning Reply
- Best experiment: ML Reply - Submission 1
- Signature:
fa34f3
- Summary: Integration of Azure Document Intelligence and Azure AI Search.
Models used:
Architecture
This solution utilized a combination of Azure Document Intelligence for document processing and Azure AI Search for efficient information retrieval.
R&D Experiments
Total experiments submitted: 2
Other approaches:
Experiment journal:
- 28 hours → R: 74.5, G: 66.0, Score: 103.2 ▲ - ML Reply - Submission 1
- 29 hours → R: 74.0, G: 63.5, Score: 100.5 - ML Reply - Submission 2
|
| 20. ▶Aleksandr Podgaiko 🤗 |
3 days |
81/62 |
103.0 |
Aleksandr Podgaiko
- Best experiment: smolagent_simple_v1
- Signature:
6afedb
- Summary: Utilized smolagents library with basic PDF extraction and a coding agent.
Models used:
- openrouter/google/gemini-2.0-flash-001
Architecture
The solution employed the HuggingFace smolagents library for agent-based interactions, integrating basic PDF extraction using PyPDF2. The architecture featured a default coding agent equipped with two tools: pdf_search for keyword-based search with contextual display and pdf_content for full-page content retrieval upon request. Additionally, the final_answer tool was customized to adhere to the submission format.
|
| 21. ▶Vlad Drobotukhin (@mrvladd) 🤗 🔒 |
6 days |
68/68 |
102.3 |
Vlad Drobotukhin (@mrvladd)
- Best experiment: Qwen 2.5-72b + Multi-Query BM25 + Domain-Specific Information Extraction + Router
- Signature:
fa77e2
- Summary: System combining LLM-based reasoning with optimized retrieval techniques.
Models used:
Architecture
This offline solution employs a multi-step process:
- start with question analysis to determine the type and domain;
- generate multiple search queries to maximize recall;
- relevant pages are retrieved using OpenSearch and processed with domain-specific LLM extractors to build structured knowledge;
- final answers are synthesized with reasoning and confidence scores.
R&D Experiments
Total experiments submitted: 10
Other approaches:
- Qwen2.5 72b + FTS (rephrase query) +SO + CheckList's
- Qwen2.5 72b + FTS +SO + CheckList's
- Qwen2.5 + FTS (rephrase query) + SO + CheckList's
- Qwen 2.5-72b + Multi-Query BM25 + Domain-Specific Information Extraction
- Qwen 2.5-72b + Multi-Query BM25 (top 15 pages) + Domain-Specific Information Extraction + Router
- Qwen 2.5-72b + Multi-Query BM25+ Domain-Specific Information Extraction + Router
- Qwen 2.5-72b-4bit + BM25 + Domain-Specific Information Extraction + Router
- MagicQwen-4bit + BM25 + Domain-Specific Information Extraction + Router
- Qwen 72b-4bit + FTS + Domain-Specific Information Extraction 0803
What didn't work?
- Simplified query generation without diversification
- Lack of domain-specific term boosting
- Absence of structured output validation
Experiment journal:
- 3 days → R: 74.7, G: 59.2, Score: 96.5 ▲ - Qwen2.5 72b + FTS (rephrase query) +SO + CheckList's
- 3 days → R: 71.8, G: 62.3, Score: 98.2 ▲ - Qwen2.5 72b + FTS +SO + CheckList's
- 4 days → R: 74.7, G: 59.2, Score: 96.5 - Qwen2.5 + FTS (rephrase query) + SO + CheckList's
- 5 days → R: 69.1, G: 65.7, Score: 100.2 ▲ - Qwen 2.5-72b + Multi-Query BM25 + Domain-Specific Information Extraction
- 6 days → R: 68.3, G: 68.2, Score: 102.3 ▲ - Qwen 2.5-72b + Multi-Query BM25 + Domain-Specific Information Extraction + Router
- 7 days → R: 67.6, G: 67.4, Score: 101.2 - Qwen 2.5-72b + Multi-Query BM25 (top 15 pages) + Domain-Specific Information Extraction + Router
- 8 days → R: 64.6, G: 62.0, Score: 94.3 - Qwen 2.5-72b + Multi-Query BM25+ Domain-Specific Information Extraction + Router
- 9 days → R: 61.9, G: 63.0, Score: 93.9 - Qwen 2.5-72b-4bit + BM25 + Domain-Specific Information Extraction + Router
- 9 days → R: 69.2, G: 63.2, Score: 97.8 - MagicQwen-4bit + BM25 + Domain-Specific Information Extraction + Router
- 10 days → R: 78.4, G: 63.0, Score: 102.2 - Qwen 72b-4bit + FTS + Domain-Specific Information Extraction 0803
|
| 22. ▶Ivan R. 🤗 |
71 min |
79/62 |
101.9 |
Ivan R.
- Best experiment: Round 2 submission
- Signature:
b29973
- Summary: A multi-step approach leveraging LLMs for question decomposition, search, and validation.
Models used:
Architecture
The solution employs a structured pipeline:
- document loading using PyPDFDirectoryLoader from LangChain;
- question decomposition with GPT-4o;
- multiple OpenAI assistants, each dedicated to a specific company, perform targeted searches using GPT-4o-mini;
- results undergo answer validation with GPT-4o
- local FAISS vector store is used for similarity search to collect reference pages.
|
| 23. ▶PENZA_AI_CREW 🤗 |
7 days |
72/65 |
101.3 |
PENZA_AI_CREW
- Best experiment: gpt-4_claude3.5_unstructured
- Signature:
67ee86
- Summary: A multi-step pipeline leveraging OCR, table/image analysis, and knowledge mapping for accurate question answering.
Models used:
- gpt-4-mini
- claude 3.5
- gpt-4o
Architecture
This RAG pipeline was composed of the following steps:
- PDF text is parsed using Unstructured library with OCR
- Tables and images are analyzed using Claude 3.5
- Knowledge map is constructed using gpt-4-mini, utilizing Structured Outputs.
- Questions are analyzed in conjunction with the knowledge map using gpt-4-mini with Pydantic schema.
- Answers are generated by gpt-4o, employing chain-of-thought reasoning and Pydantic schema (SO CoT).
R&D Experiments
Total experiments submitted: 2
Other approaches:
- RAG_PNZ_PAYPLINE: OCR with Unstructured, table/image analysis with Claude 3.5, metadata extraction with gpt-4-mini, and final reasoning with gpt-4o.
What didn't work?
- Alternative OCR methods not utilizing Unstructured.
- Direct question answering without intermediate knowledge mapping.
Experiment journal:
- 7 days → R: 12.2, G: 11.0, Score: 17.1 ▲ - RAG_PNZ_PAYPLINE
- 7 days → R: 72.5, G: 65.0, Score: 101.3 ▲ - gpt-4_claude3.5_unstructured
|
| 24. ▶Yolo leveling |
25 hours |
82/59 |
101.0 |
Yolo leveling
- Best experiment: Marker + Gemini
- Signature:
31b473
- Summary: Convert PDFs to markdown, extract company names, and generate JSON representations.
Models used:
Architecture
The solution starts converting each PDF document into markdown format using the Marker tool with OCR capabilities. Afterward, the system identifies the company name within the content. In cases where multiple companies are mentioned in the query, the system employs a hallucination control mechanism to determine the most relevant company. The markdown content is then incorporated into the context for the LLM, which extracts and generates a structured JSON representation of the required information.
R&D Experiments
Total experiments submitted: 2
Other approaches:
- Gemini 1M pdf "thinking" + 4o parser
What didn't work?
- Queries involving multiple companies were marked as N/A in alternative approaches.
Experiment journal:
- 25 hours → R: 76.0, G: 60.0, Score: 98.0 ▲ - Gemini 1M pdf "thinking" + 4o parser
- 25 hours → R: 82.2, G: 59.9, Score: 101.0 ▲ - Marker + Gemini
|
| 25. ▶ArtemNurm 🤗 |
7 days |
77/61 |
99.9 |
ArtemNurm
- Best experiment: brute_flash2.0&brute_flash2.0
- Signature:
46e0e0
- Summary: PDF2MD with Flash, relevant data extraction with Flash, the data is sent to LLM with questions using SO (no CoT). All steps include generator-critic workflow.
Models used:
- Gemini Flash 2.0
- OpenAI o3-mini
Architecture
The winning experiment employs a robust architecture leveraging the Gemini Flash 2.0 and OpenAI o3-mini models. The process involves converting PDF documents to Markdown format using Flash, extracting relevant data, and querying the LLM with specific questions using a straightforward approach without chain-of-thought reasoning.
A generator-critic workflow is integrated into all steps to ensure high-quality outputs.
R&D Experiments
Total experiments submitted: 8
Other approaches:
- brute_flash2.0&CoT_flash2.0
- index_flash2.0&brute_flash2.0
- index_flash2.0&CoT_4o-2024-11-20
- index_flash2.0&CoT_flash2.0
- index_flash2.0&CoT_o3-mini-high
- index_flash2.0&CoT_o3-mini
- flash2.0_sees_all_content
What didn't work?
- Using chain-of-thought reasoning in 'brute_flash2.0&CoT_flash2.0' did not outperform the winning approach.
- Concatenating all Markdown files into a single string in 'flash2.0_sees_all_content' was less effective.
Experiment journal:
- 7 days → R: 77.8, G: 61.0, Score: 99.9 ▲ - brute_flash2.0&brute_flash2.0
- 7 days → R: 77.7, G: 61.0, Score: 99.8 - brute_flash2.0&CoT_flash2.0
- 7 days → R: 68.5, G: 57.6, Score: 91.8 - index_flash2.0&brute_flash2.0
- 7 days → R: 66.4, G: 56.8, Score: 90.0 - index_flash2.0&CoT_4o-2024-11-20
- 7 days → R: 66.3, G: 57.6, Score: 90.7 - index_flash2.0&CoT_flash2.0
- 7 days → R: 65.6, G: 58.8, Score: 91.6 - index_flash2.0&CoT_o3-mini-high
- 7 days → R: 65.9, G: 59.3, Score: 92.2 - index_flash2.0&CoT_o3-mini
- 7 days → R: 71.8, G: 55.6, Score: 91.4 - flash2.0_sees_all_content
|
| 26. ▶ndt by red_mad_robot 🤗 🔒 |
9 days |
72/63 |
99.7 |
ndt by red_mad_robot
- Best experiment: qwen32b+bge_m3
- Signature:
30f0d1
- Summary: PDFs were converted to markdown, vectorized using bge m3, and queried with Qwen 32B.
Models used:
Architecture
This offline solution involved processing PDF documents by converting them into markdown format using the Pymupdf library. These markdown representations were then vectorized using the popular BGE-M3 model.
Qwen 32B instruct model was used to answer user queries by leveraging the vectorized data for relevant context retrieval.
R&D Experiments
Total experiments submitted: 5
Other approaches:
- full open-source + roter agent
- qwen7b-router-agent
What didn't work?
- Directly querying without vectorization
- Using alternative LLMs for vectorization
Experiment journal:
- 23 hours → R: 27.2, G: 54.0, Score: 67.6 ▲ - full open-source + roter agent
- 7 days → R: 73.2, G: 51.0, Score: 87.6 ▲ - qwen7b-router-agent
- 9 days → R: 73.2, G: 59.0, Score: 95.6 ▲ - ndt by red_mad_robot
- 9 days → R: 72.9, G: 63.2, Score: 99.7 ▲ - qwen32b+bge_m3
|
| 27. ▶Neoflex DreamTeam 🤗 🔒 |
30 hours |
77/58 |
96.9 |
Neoflex DreamTeam
- Best experiment: Simple LLM Brute Force
- Signature:
34a266
- Summary: Utilized a straightforward LLM brute force approach for each page with predefined questions and example answers.
Models used:
Architecture
Solution used Qwen 2.5 model to process each page individually, applying a brute force methodology with a set of predefined questions and corresponding example answers to extract relevant information effectively.
R&D Experiments
Total experiments submitted: 2
Other approaches:
What didn't work?
- Alternative configurations of the Checklist based RAG approach
Experiment journal:
- 30 hours → R: 77.8, G: 58.0, Score: 96.9 ▲ - Best run
- 7 days → R: 67.3, G: 51.7, Score: 85.4 - neon_team
|
| 28. ▶nightwalkers 🔒 |
6 hours |
72/60 |
96.7 |
nightwalkers
- Best experiment: nightwalkers-baseline
- Signature:
356ef4
- Summary: Utilized a vector database for efficient document retrieval and LLM for response generation.
Models used:
- deepseek-r1-distill-llama-70b
Architecture
The team implemented vector database search using embeddings from all-MiniLM-L6-v2 and ibm/granite-embedding-107m-multilingual models. This facilitated the retrieval of the most relevant page and document based on the query. The retrieved information was then processed by the deepseek-r1-distill-llama-70b LLM to generate relevant answers.
|
| 29. ▶Gleb Kozhaev 🤗 |
32 hours |
79/56 |
95.5 |
Gleb Kozhaev
- Best experiment: pymupdf4llm + Structured Output
- Signature:
1442cb
- Summary: Utilized pymupdf4llm with structured output and three distinct system prompts/roles.
Models used:
Architecture
RAG solution employed the pymupdf4llm framework, leveraging Structured Outputs to enhance data processing and comprehension.
Three distinct system prompts/roles were utilized to optimize the model's performance and ensure accurate and efficient results.
|
| 30. ▶AndreiKopysov 🤗 |
33 hours |
76/57 |
95.3 |
AndreiKopysov
- Best experiment: Gemini2.0 and DeepSeek R1 Integration
- Signature:
574182
- Summary: The architecture processes PDF pages using Gemini2.0 and refines responses with DeepSeek R1.
Models used:
Architecture
This RAG solution used a two-step pipeline:
- each page of the PDF document is processed using the Gemini2.0 model to extract relevant information;
- extracted responses are refined and analyzed using the DeepSeek R1 model to ensure accuracy and relevance.
R&D Experiments
Total experiments submitted: 2
Other approaches:
- Reused the same architecture in different configurations.
Experiment journal:
- 33 hours → R: 76.2, G: 57.2, Score: 95.3 ▲ - AndreiKopysov
- 33 hours → R: 76.2, G: 57.2, Score: 95.3 - AndreyKopysov
|
| 31. ▶Serj Tarasenko |
3 days |
82/54 |
95.0 |
Serj Tarasenko
- Best experiment: complicated second
- Signature:
a5cf25
- Summary: RAG pipeline with query enhancement and re-ranking.
Models used:
- gpt-4o-mini
- text-embedding-3-small
Architecture
The winning solution implemented a Retrieval-Augmented Generation (RAG) pipeline. The process involved extracting content from PDFs, segmenting it into manageable chunks, and indexing these chunks using FAISS for efficient vector-based retrieval. Queries were enhanced with financial terms to improve relevance, followed by a retrieval step that included re-ranking to prioritize the most pertinent information. Finally, an LLM was employed to generate comprehensive answers based on the retrieved data. The source code for this implementation is publicly available.
|
| 32. ▶AAV |
7 days |
62/62 |
93.9 |
AAV
- Best experiment: Agent+Router
- Signature:
5e0479
- Summary: The architecture employs an agent-based approach with a routing mechanism.
Models used:
Architecture
The solution uses the 'gpt-4o-mini' model in an architecture combining an agent with a router. This design enables efficient task delegation and processing, optimizing performance for the challenge requirements.
R&D Experiments
Total experiments submitted: 6
Other approaches:
- Agent
- Agent + sim search + tfidf
What didn't work?
- Using 'private model' instead of 'gpt-4o-mini'
- Excluding the router component
Experiment journal:
- 7 days → R: 60.7, G: 62.8, Score: 93.1 ▲ - llm1-sim-preselected
- 7 days → R: 62.9, G: 62.5, Score: 93.9 ▲ - llm2-sim-preselected
- 7 days → R: 62.7, G: 57.3, Score: 88.7 - llm2-sim-not-preselected
- 7 days → R: 61.0, G: 60.8, Score: 91.3 - llm1-sim-not-preselected
- 7 days → R: 25.1, G: 60.9, Score: 73.5 - llm1-sim-ifidf-not-preselected
- 7 days → R: 27.2, G: 62.8, Score: 76.4 - llm2-sim-tfidf-not-preselected
|
| 33. ▶AI Slop 🤗 |
3 hours |
80/53 |
93.5 |
AI Slop
- Best experiment: AI Slop Cursor+Sonnet 3.7
- Signature:
fc3dc9
- Summary: Utilized a streamlined approach leveraging LLMs for direct question answering.
Models used:
Architecture
The team employed the gpt-4o-mini model to process and answer questions directly from the provided PDF documents.
By utilizing metadata and targeted queries, they efficiently narrowed down relevant information, ensuring accurate and concise responses. The approach avoided complex retrieval-augmented generation (RAG) or OCR techniques, focusing on the inherent capabilities of the LLM.
|
| 34. ▶RAG challenge Orphist 🔒 |
63 min |
78/53 |
92.4 |
RAG challenge Orphist
- Best experiment: Iterative LLM Prompting with BM25
- Signature:
e98c1b
- Summary: The solution employs BM25 for document retrieval and iterative LLM prompting for query expansion and summarization.
Models used:
Architecture
The solution utilized an architecture combining BM25plus for document retrieval and iterative prompting of the gemma-2-9b-it LLM.
The process involved chunking PDF documents for ingestion, storing them in an in-memory local storage, and applying BM25plus for query matching with meta-filters.
Due to a last-minute issue with embedding models, the team opted for a non-hybrid pipeline. The iterative prompting expanded the initial query and used a scratchpad for summary collection, culminating in a final prompt to extract the requested information.
|
| 35. ▶Dennis S. 🤗 |
7 days |
81/50 |
91.0 |
Dennis S.
- Best experiment: Deepseek naive questionfilter
- Signature:
53630f
- Summary: A question-centered approach leveraging document parsing and heuristic-based analysis.
Models used:
Architecture
The solution employs a question-centered methodology to efficiently extract relevant information from documents.
- Initially, PDFs are parsed using PyMuPDF and Tesseract for OCR when necessary.
- The system analyzes provided metadata and questions to identify relevant companies and metrics, classifying questions into
single_fact or aggregate types.
- It processes documents in parallel, extracting answers based on the question type, and aggregates results accordingly.
This approach prioritizes speed and cost-efficiency.
R&D Experiments
Total experiments submitted: 2
Other approaches:
- Deepseek v3 - bruteforce questionfilter
What didn't work?
- Using regex-based logic for question classification
- Dividing questions into first occurrence and aggregated types without clear pipeline integration
Experiment journal:
- 7 days → R: 79.8, G: 50.0, Score: 89.9 ▲ - Deepseek v3 - bruteforce questionfilter
- 7 days → R: 81.9, G: 50.0, Score: 91.0 ▲ - Deepseek naive questionfilter
|
| 36. ▶Slava RAG 🤗 |
7 hours |
65/57 |
90.7 |
Slava RAG
- Best experiment: Slava RAG
- Signature:
282787
- Summary: Embedding: OpenAI text-embedding-3-small, LLM: GPT-4o, Vector Database: Pinecone, PDF Processing: PyMuPDF, Chunk Processing: Custom algorithm
Models used:
Architecture
This architecture combined:
- OpenAI's text-embedding-3-small for embedding generation;
- GPT-4o as the primary LLM;
- Pinecone for vector database management;
- PyMuPDF for efficient PDF processing;
- a custom algorithm for chunk processing.
|
| 37. ▶Alex_dao |
95 min |
68/56 |
90.7 |
Alex_dao
- Best experiment: Alex_Dao_v1_final
- Signature:
93c0ef
- Summary: Utilized a kv-index architecture.
Models used:
Architecture
The winning solution implemented a key-value index (kv-index) architecture, leveraging the capabilities of the GPT-4 model (gpt4o) to efficiently retrieve and process information. This approach ensured high performance and accuracy in the challenge tasks.
|
| 38. ▶Mykyta Skrypchenko 🤗 |
31 hours |
42/64 |
85.3 |
Mykyta Skrypchenko
- Best experiment: Kyiv-bge1.5
- Signature:
d5fb15
- Summary: Integration of advanced text retrieval and vector database with LLM for question answering.
Models used:
Architecture
The solution is a multi-component architecture:
- Fitz for efficient text retrieval
- BAAI/bge-base-en-v1.5 Sentence Transformer for embedding generation
- ChromaDB as the vector database for storage and retrieval
- OpenAI API for question answering
|
| 39. ▶F-anonymous 🤗 🔒 |
5 days |
73/47 |
83.8 |
F-anonymous
- Best experiment: Fully local, own DeepThinking
- Signature:
2a2a1b
- Summary: Fully local graphRAG with hybrid search and custom-tuned LLM.
Models used:
Architecture
The solution by F-anonymous a fully local graph-based Retrieval-Augmented Generation (RAG) architecture.
They utilized their proprietary DeepThinking framework in conjunction with a custom-tuned Qwen2.5 14b model. The system integrated a hybrid search mechanism combining vector-based and BM25 methodologies to enhance retrieval accuracy and relevance.
|
| 40. ▶DataNXT 🔒 |
5 days |
54/55 |
82.6 |
DataNXT
- Best experiment: Prototype-RAG-Challenge
- Signature:
0e942a
- Summary: Pipeline with specialised prompted LLM Calls
Models used:
Architecture
The solution utilized a pipeline architecture with specialized prompted calls to the OpenAi-4o-mini model. This approach allowed for efficient and accurate information retrieval and generation.
|
| 41. ▶AValiev 🔒 |
4 hours |
43/60 |
81.8 |
AValiev
- Best experiment: IBM-deepseek-agentic-rag
- Signature:
493744
- Summary: Agentic RAG with type validation, Pydantic typing, Qdrant vector store querying.
Models used:
- deepseek/deepseek-r1-distill-llama-70b
Architecture
This RAG solution was based on an Agentic Retrieval-Augmented Generation (RAG) architecture.
It utilized type validation and Pydantic typing for robust data handling, and Qdrant vector store querying for efficient information retrieval. PDF documents were processed using PyPDF and Docling for accurate text extraction.
R&D Experiments
Total experiments submitted: 5
Other approaches:
- openai-agentic-rag
- IBM-mixtral-agentic-rag
- granite-3-8b-instruct_rag_agentic
- deepseek/deepseek-r1-distill-llama-70b_sophisticated_chunking_rag_agentic
What didn't work?
- Alternative LLM models such as OpenAI-gpt-4o-mini and mistralai/mixtral-8x7b-instruct-v01 were explored but did not achieve the same performance as the winning model.
Experiment journal:
- 54 min → R: 43.5, G: 60.0, Score: 81.8 ▲ - openai-agentic-rag
- 3 hours → R: 43.5, G: 33.0, Score: 54.8 - IBM-mixtral-agentic-rag
- 4 hours → R: 43.5, G: 60.0, Score: 81.8 - IBM-deepseek-agentic-rag
- 4 hours → R: 43.5, G: 48.5, Score: 70.2 - granite-3-8b-instruct_rag_agentic
- 34 hours → R: 35.8, G: 53.0, Score: 70.9 - deepseek/deepseek-r1-distill-llama-70b_sophisticated_chunking_rag_agentic
|
| 42. ▶bimurat_mukhtar 🤗 🔒 |
32 hours |
36/31 |
49.4 |
bimurat_mukhtar
- Best experiment: bm_v1
- Signature:
c25e30
- Summary: Multi-agent architecture with specialized branches for diverse answer generation.
Models used:
Architecture
The solution is a multi-agent architecture inspired by Self RAG, where input PDFs are converted to text, preprocessed, and filtered to extract relevant information.
Different branches are utilized to handle specific types of queries, leveraging the strengths of the LLMs deepseek-r1 and gemini.
|
| 43. ▶ragtastic |
7 days |
4/3 |
5.4 |
ragtastic
- Best experiment: ragtastic
- Signature:
43d4fd
- Summary: The architecture leverages the Mistral-large model for its implementation.
Models used:
Architecture
The solution used Mistral-large model to achieve its objectives. The architecture is designed to optimize performance and accuracy, ensuring robust results.
|