Black Friday Experiment - Report 1
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
This is a first report on the Black Friday experiment: let's rebuild and improve event-sourcing designs that I have worked on in the past decade.
- about the experiment;
- which features I wanted to keep and introduce;
- how the code looks like (features and specs);
- performance;
- simulation;
- tooling and development experience;
- possible next steps.
About the experiment
Black Friday is a special day in a retail business - a great deal of yearly revenue is made on that day. It also is a challenging day for engineers and operations. There is lot of stress on sales and inventory systems. Load goes up, cloud providers go down, things go haywire.
This uncovers weird bugs, breaks assumptions, and teaches a lesson about cascading failures (under the Black Friday load failures never happen alone).
In this world, upgrades have to happen with zero downtime under a sustainable load.
So I wanted to see if I could design an event-sourced system to handle the Black Friday load while being simple to maintain and extend. At least, more simple than what we had achieved at SkuVault.
Another way to look at the experiment - is about trying to scale event sourcing implementation to the extreme in performance, capabilities, and ease of supporting multiple engineering teams.
From this perspective, developer tooling and experience become very important.
In the recent past, I've worked on projects where finding and onboarding new engineers is a difficult process. This could relate to the domain (data science and machine learning in international logistics), but some of the lessons apply well to any software project.
Picking the battles
Here are the features that I want to keep from my past experiences:
- Event-sourcing - because that simplifies development and zero-downtime upgrades under sustainable load.
- Event-driven specifications to define and manage features that are linked to the user stories.
- Fast test runs - being able to run 1000s of specs per second on a local machine.
- Simulated development environments - be able to run a server or the whole cluster locally, if needed.
- High availability - killing any single server (Load balancer, application, or database) shouldn't bring the system down;
- Zero downtime for any operations.
Here are the features I want to introduce:
- Tenant isolation. Each tenant has to run in its own tiny VM, while allowing to pack thousands of tenants on a single node. Previously: multiple tenants from a single partition would share a process.
- Design for live tenant migration and resource allocation. Previously - tenants were fixed to their partition. All tenants in a partition shared CPU, RAM, and storage.
- Use golang language - it is easy to pick up, has fast build times, and compiles to a single static binary that can be easily deployed. Previously: C# .NET
- Use gRPC to define APIs and contracts - because there is so much tooling around that. Previously: code-first contracts and custom IDL for service definitions.
- Use SQLite for the aggregate state - because there is so much tooling and ongoing work. Previously: LMDB database which has great performance but a smaller ecosystem.
- Design for event store compaction, since I want to keep primary event streams small and enable fast schema migrations. Previously: event streams were continuously growing without a bound.
- Enable per-tenant customizations, to reduce overall system complexity. Previously: features were developed and deployed for everybody, even if they were needed only for a few customers.
- Enable per-tenant encryption and encrypt all data (in flight or on disk) with a tenant-specific encryption key.
Codebase so far
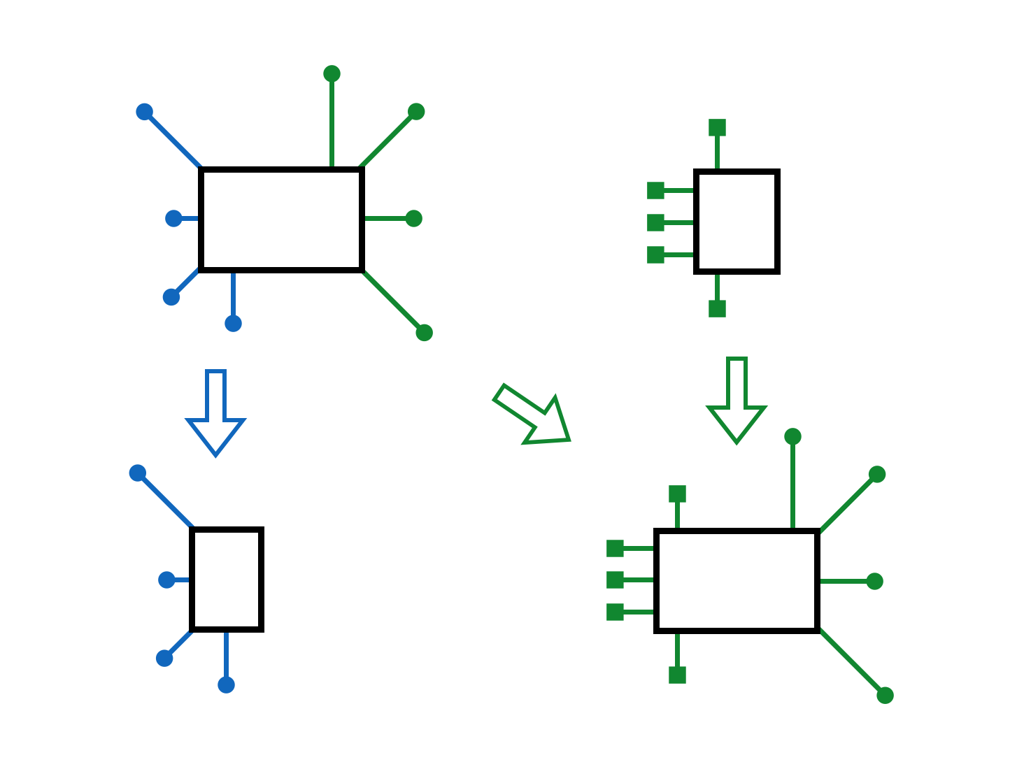
At high level, the architecture looks like this:
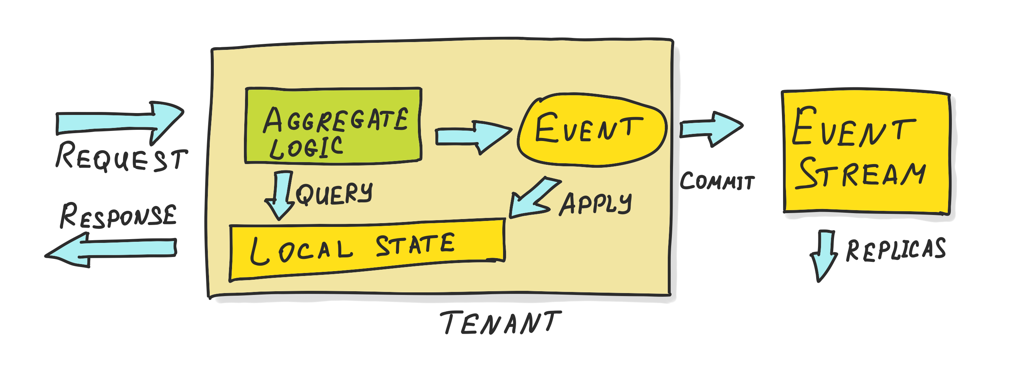 There is a single-tenant application that contains a single event-sourced aggregate.
There is a single-tenant application that contains a single event-sourced aggregate.
It is possible to have multiple tenants per application, multiple aggregates, too. However, this increases code complexity and discards some nice capabilities. At this point I just want to see how far "one event sourced aggregate per tenant" can take me.
As you can see the tenant has two interfaces:
- Request/Response interface for API and Web.
- Publishing events to the event stream for replication (also loading these events by replicas).
That interface would be my testing boundary for features. I have re-implemented specification testing framework in golang.
Specifications follow common "Given events - When request - Then expect outcome and events". Check out this section on Event Sourcing for more details.
Specifications test aggregate logic and look like this:
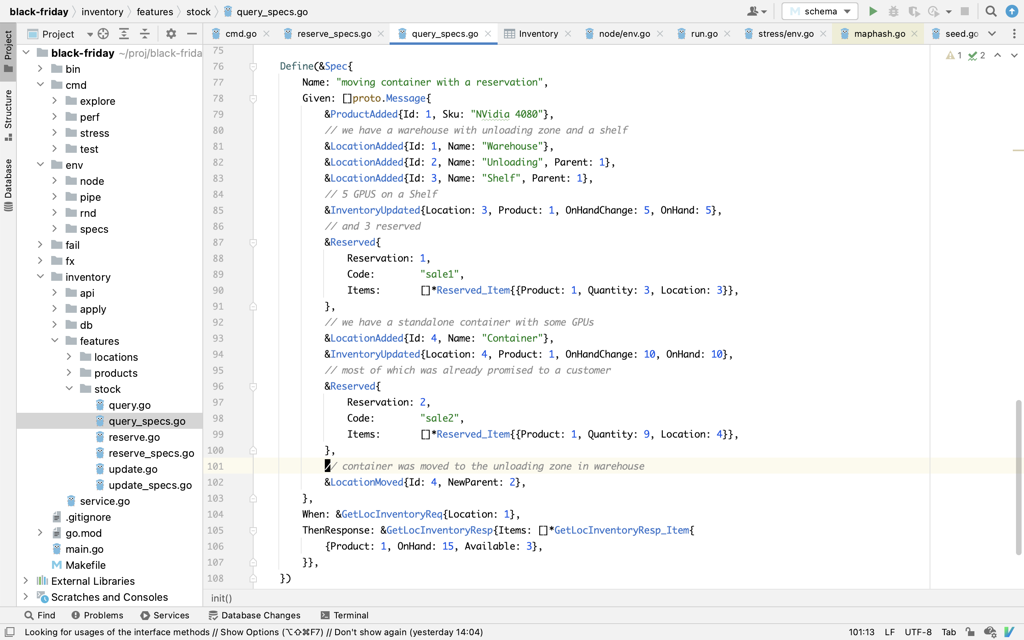
When specs run, they produce an output like that on failure:
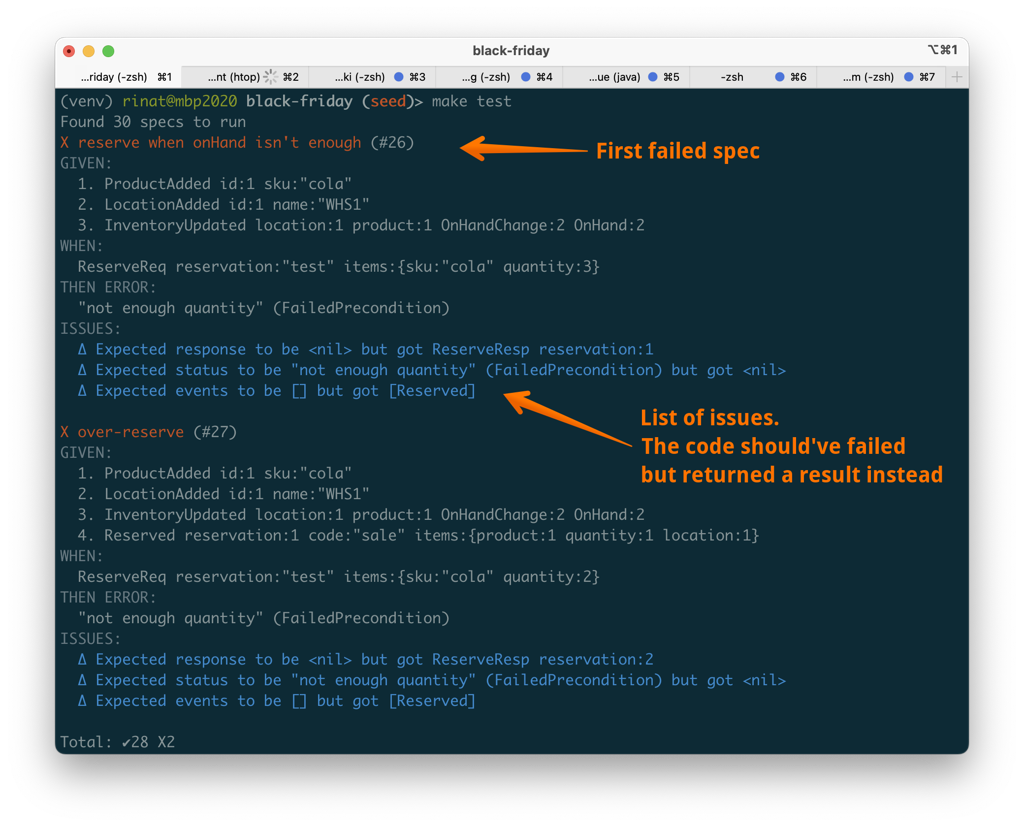
I started with specifications because they are more important than the actual implementation. They define the behaviors of a service, capture edge cases, and prevent regressions.
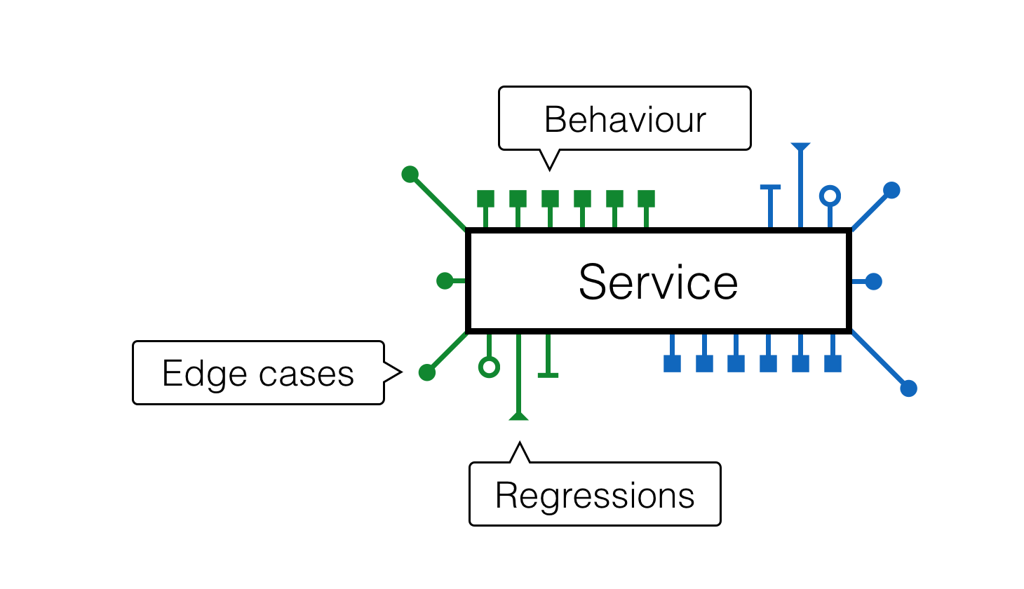
If you have good tests, then you could reliably refactor the actual implementation. You could merge, split or even completely rewrite actual codebase.
See High Availability and Performance for more details.
There is a portable demonstration of that approach on Replit. It contains a subset of specs and a spec runner. Last two specs are intentionally broken.
The unit of development in this approach is not an aggregate, but a feature.
Features could relate to specific Web/API methods (e.g.: create location, move location, reserve inventory) or be more fine-grained (e.g.: run custom script when reserving stock for an incoming order). It all depends on user stories.
I usually keep one feature in a single file, with a separate specifications file nearby. That file would normally be a single method that covers everything from API/Web to DB access to event generation and application.
Let's take a look at a simple feature. It is an API method that allows to move location to any new location. For example, we could have a incoming container that is being moved to the unloading zone in a warehouse.
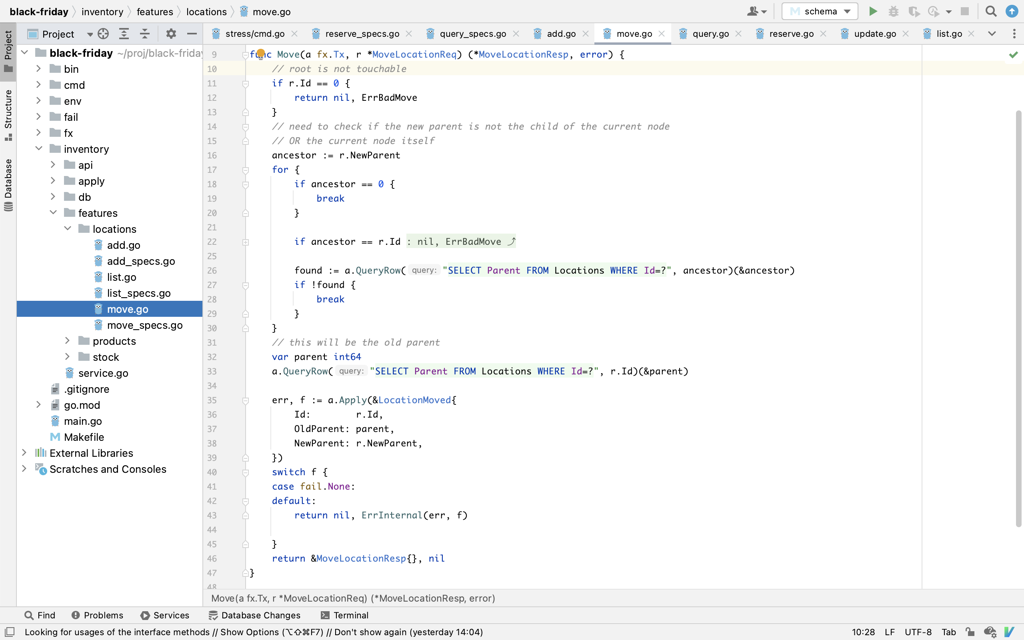
All logic happens within a single transaction that is managed by the framework. Within that transaction we are free to:
- Query the database. Queries are extremely cheap and generally take microseconds each.
- Make decisions and generate new events. Events will be applied to the database immediately, also taking microseconds.
- Return with error at any point. This will abort the transaction and roll the state back.
- Return a valid response. Framework will take care of appending events to the event store and completing the transaction.
Feature-oriented project layout works surprisingly well. It is a relief from projects when adding a single field required changing half a dozen files. Or a dozen, if that involved entities living in different aggregates.
In order to see how well this approach handles business complexity, I'm adding features that weren't on the table before (in my past projects):
- tenant-specific scripts;
- flexible inventory location structure (e.g. warehouse-bin or region-warehouse-zone-row-shelf-bin with movable containers and palettes);
- ability to reserve stock at any given location level (this reduces item availability);
- ability for tenants to create inventory reports that provide fast and consistent view into products quantities at predefined locations (e.g. by warehouse or in all containers-in-transit).
We'll see where does this break.
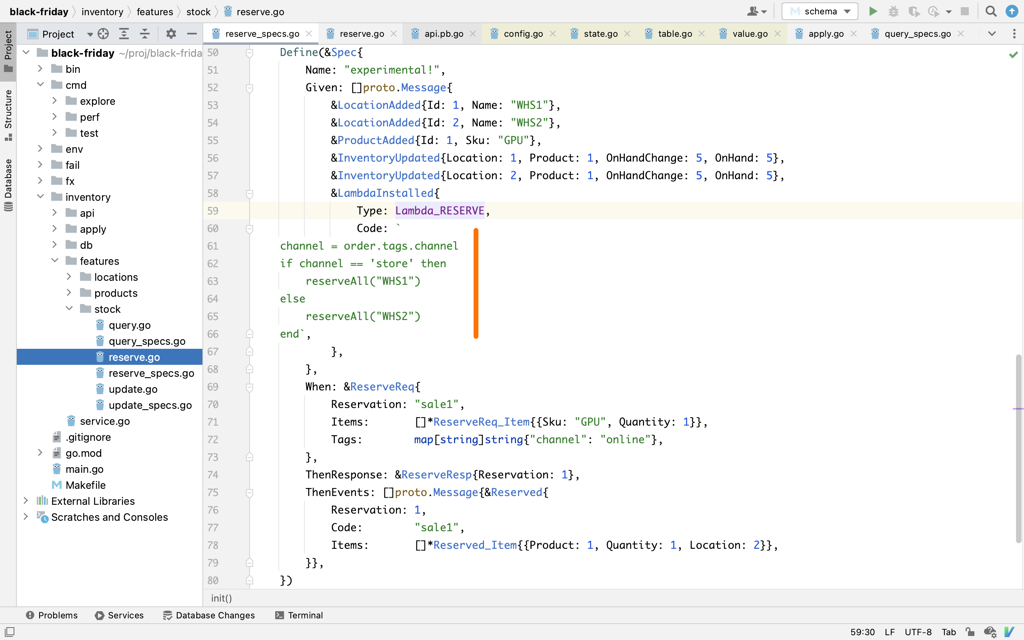
This is how custom scripts look like, by the way. They are installed in aggregate via a normal event, which allowes them to be testable without any extra scaffolding.
Performance
Test performance is good. I can run more than 10 thousand specs per second (using perf command to run existing specs in a loop):
> make && bin/bf perf -sec 5
Matched 30 specs out of 30
Speed test with 4 core(s) for 5s
OPERATION TOTAL OPS/SEC KHZ SEC PER OP
run spec 64050 12810 12.8 78.064µs
apply event 172935 23716 23.7 42.164µs
executed 64050 specs
This also includes specs that involve custom tenant-specific scripts in Lua. That logic has a bit of overhead to start a new Lua VM, load its state, run custom scripts, and return control to the API call.
Tests run on an empty database (using a combination of
:memory:, WAL, and transactions to keep things fast), they don't indicate overall performance in a real world.
To keep development grounded in the reality, I started building tooling for the stress tests. Here are the first results of a simple simulation scenario run with a stress command. Numbers are a testament to the performance and efficiency of golang and SQLite.
> make && bin/bf stress
Start simulation
Setup simulated network
Dialing 'sim'
Serving on 'sim'
DURATION DB SIZE LOCATIONS PRODUCTS ON-HAND RESERVED
432 ms 4.4 MB 511 1000 4934 16109
422 ms 4.5 MB 1022 2000 9486 32597
424 ms 4.7 MB 1533 3000 14116 48624
424 ms 4.9 MB 2044 4000 18717 64874
430 ms 5.1 MB 2555 5000 23356 81562
433 ms 5.3 MB 3066 6000 28643 98009
429 ms 5.5 MB 3577 7000 33492 114569
426 ms 5.7 MB 4088 8000 38785 130953
428 ms 5.8 MB 4599 9000 43605 147313
435 ms 6.0 MB 5110 10000 48865 164267
436 ms 6.2 MB 5621 11000 53694 180734
431 ms 6.4 MB 6132 12000 58368 196699
477 ms 6.6 MB 6643 13000 63468 213129
509 ms 6.8 MB 7154 14000 68682 229472
527 ms 7.0 MB 7665 15000 74143 245777
452 ms 7.2 MB 8176 16000 79378 261941
452 ms 7.4 MB 8687 17000 84434 278851
459 ms 7.6 MB 9198 18000 89124 295007
493 ms 7.7 MB 9709 19000 93776 311512
559 ms 8.0 MB 10220 20000 98624 328051
Simulation
Stress test tool above uses simulated network connection. This is possible because gRPC SDK in golang relies on net.Listener interface:
// A Listener is a generic network listener for stream-oriented protocols.
type Listener interface {
// Accept waits for and returns the next connection to the listener.
Accept() (Conn, error)
// Close closes the listener.
Close() error
// Addr returns the listener's network address.
Addr() Addr
}
Even an onion could match this interface, if it knew how to return an instance of net.Pipe() (synchronous, in-memory, full duplex network connection).
net.Pipe() allows to test the whole stack without actually touching network devices, until needed.
This is as far as the simulation goes in this project, though. I couldn't figure how to control golang scheduler and simulate the passing of time, like it was possible in .NET (see Simulate CQRS/ES Cluster).
Tooling and development experience
While specs are enough for the most of the development, in some edge cases I need more insight into application state. explore command helps here, it runs a single test specification, exporting the final state into a standalone database. This is good for fixing weird bugs, tuning queries or even developing new features.
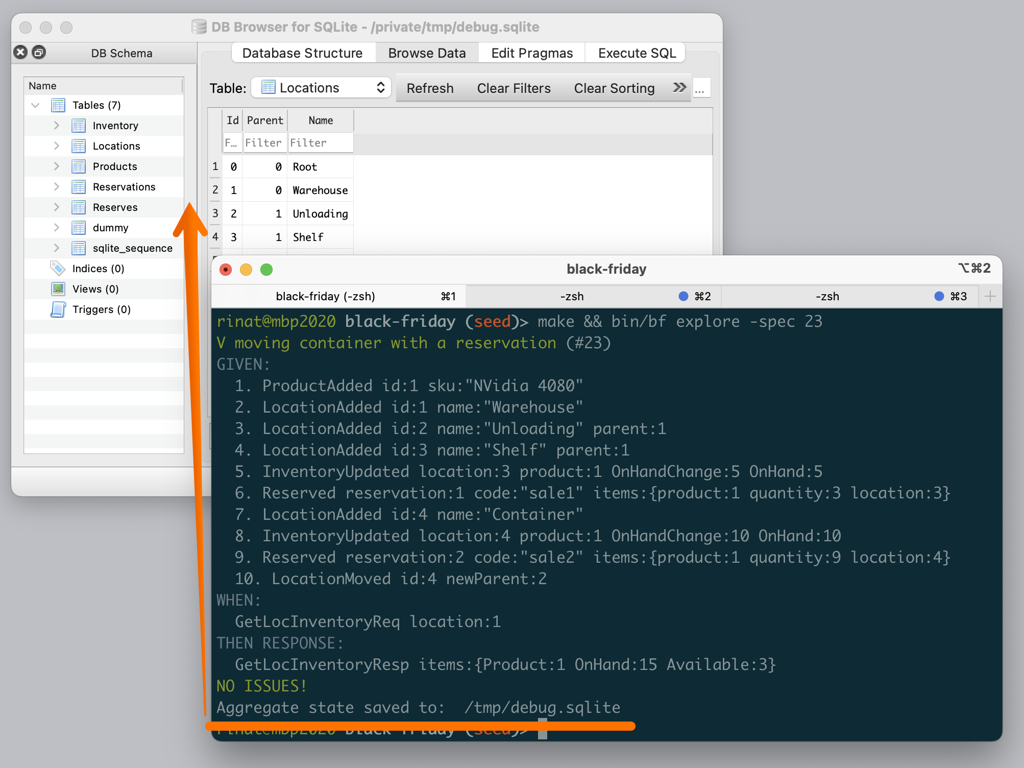
After starting to use this command, I noticed a nice side-effect. GoLand picked up on the schema (because I used it to run some queries) and started intelligently completing and highlighting inline SQL.
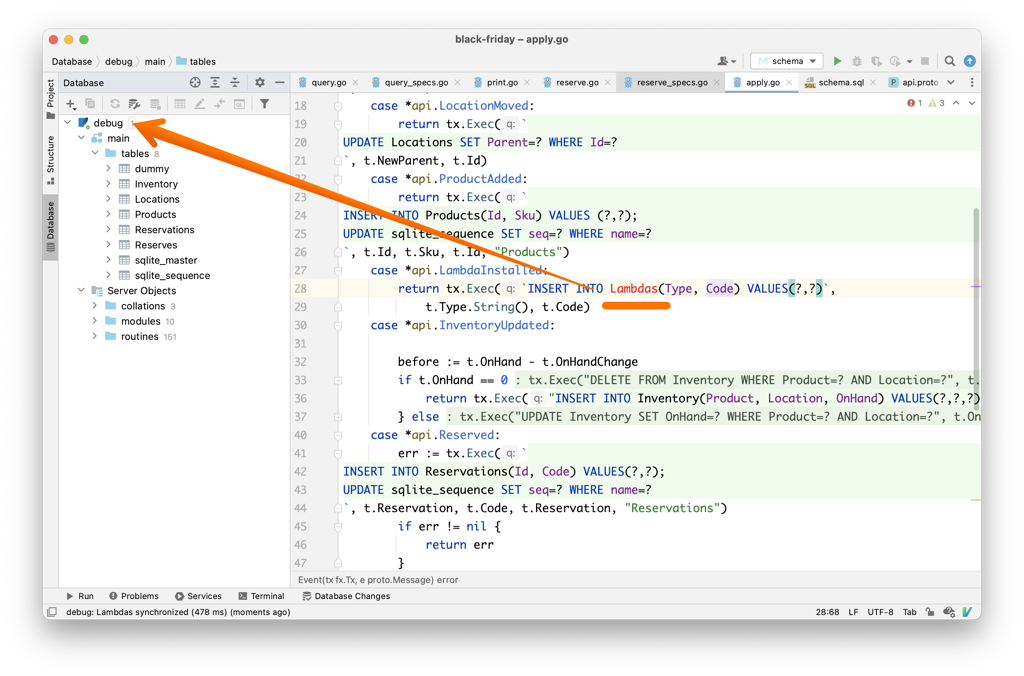 Speaking of the development experience, the full cycle of building the code and running tests isn't that fast.
Speaking of the development experience, the full cycle of building the code and running tests isn't that fast.
It takes roughly 3 seconds on my laptop (Intel Mac Book) for that. I blame my CGO dependency for that (SQLite). Running go install -v doesn't help.
> time make build test
make build test 2.96s user 0.88s system 112% cpu 3.427 total
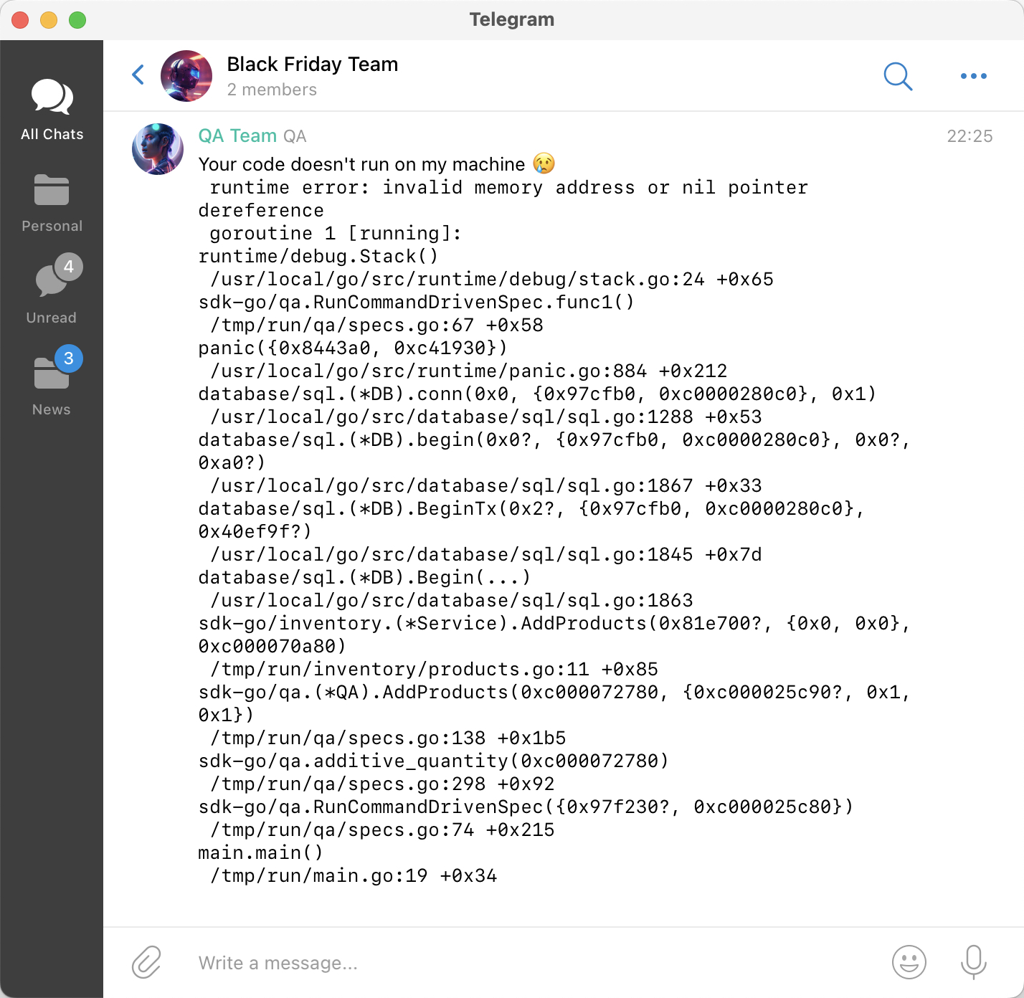
I also took a look at running self-hosted server (with gitea). It had server-side post-commit hook that would trigger the build inside a VM and send any failures to Telegram.
So whenever I git push, there will be a success or failure notification arriving within 3 seconds. It was an interesting experience.
Next steps
I have a few ideas of where to take this next. Below is a list without priorities. There are too many ideas, and only one or two will get a follow-up.
- Switch the spec runner to work through the simulated gRPC interface. This will let to compare multiple different implementations of the same features, even if they are written in different languages. Christian Folie is looking into F# implementation!
- Explore adding more domains to the same codebase (JIRA, ML Pipelines library, Community blog with comments).
- Recover experiments with Terraform and FoundationDB to deploy golang codebase in a cloud environment against a clustered event store. Launch
stresscommand and then start manually killing nodes at random. - Continue exploration of FirecrackerVM (it is awesome) to streamline the process of building application as a bootable VM image. Then check out, what it takes to have a few hundred of them on a single server. What would the CI/CD process with stages look like?
- Improve the performance a bit more: prepare and cache SQL queries, switch Lua VM to use native LuaJIT, and play with request batching (trades off latency for throughput).
- Add web UI and web specs, so that features are more realistic.
- Set up a proper demo user map with an issue tracker and CI/CD cycle, then bring over a few friends to see what they think of the development experience.
I'm personally interested in the FirecrackerVM line of research. What do you think?
Published: November 06, 2022.
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.