Better performance with DOD
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
Time flies! Black Friday Experiment has been running for 4 months, according to my git commit history.
When I was starting, I wanted to scratch my itch and try improving on the past event-sourced designs.
I'm quite happy with the code performance so far. It is faster than the LMDB-based inventory engine I used to work on in the past.
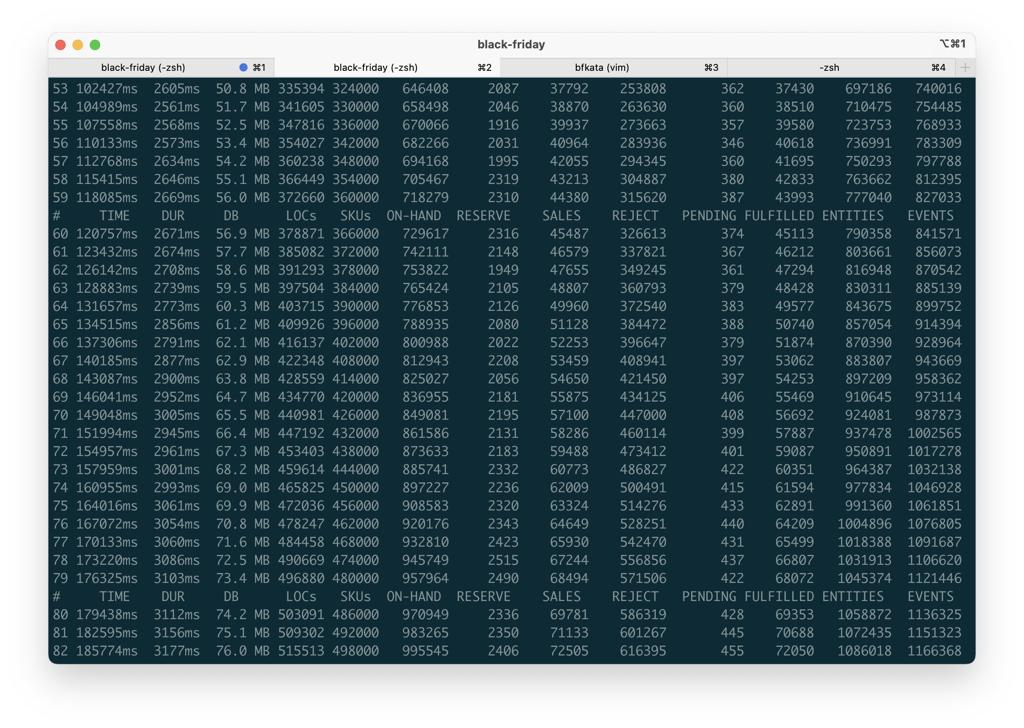
In 3 minutes I can replay a story of a growing company: 500k nested locations, 498k SKUs, 690k orders, more than a million entities and events.
All orders are resolved against strongly consistent availability engine. 1 thread, running in a local-only mode without remote event store replication.
With EC replication, the speed will be the same. If we go consistent, then the latency/throughput will depend on the streaming/storage engine setup.
Curiously enough, this exercise quickly moved from "exercise in event sourcing" to an "exercise in writing inventory constraint solver engine".
In order to make things fast, I had to finally start thinking about how data is laid out in the memory and how CPU cores go through that.
If you think of it, classical Object-Oriented-Programming (OOP) lays its data in memory like Spaghetti bolognese - objects and pointers are all mixed up. This is fine until you want to do some intensive computations with your data.
For example, detecting early, if moving items between two warehouses will negatively affect any pending orders. Given that you have a few hundred thousand locations and products already in the system.
If your object graph is done in OOP, then CPU pre-fetcher will have jump back and forth between random memory addresses.
Performance is probably the reason why deep neural networks are never implemented in OOP style. If each neuron and axon were represented as a distinct object with its fields, then exact memory location of a given neuron could be non-deterministic.
Instead, neural networks are represented as arrays, matrices and tensors. This happens to be more natural and fast for CPU or GPU to work with.
Fortunately, there is a good old programming approach called Data-Oriented Design. It says: "Dude, do whatever you want, just structure your data to use CPU efficiently".
One approach for that is about laying out data in continuous blocks of memory, so that it will be easy for CPU to prefetch all required data and just chew up through it.
Just refactoring the codebase to achieve that was good enough for the performance gains I mentioned earlier:
- group all inventory locations for a given product close in memory;
- represent them as structs and arrays.
// ProductStock captures stock quantities and reservations
// of a single product across all locations and warehouses.
// it represents a tree that is flat in memory. The root
// always contains totals.
// We can easily fit stock availability for 100 products in CPU cache
// allowing us to resolve availability or run kit calculations
type ProductStock struct {
// location IDs in the system
locs []int32
// pointer to the parent location. -1 for root
parentIdx []int16
// reservation and availability counts
reserved []int32
onHand []int32
}
This means: whenever the code execution touches any stock, then all locations for that product are probably already in the CPU cache. So calculations across multiple locations will be cheaper.
Main memory reference is as expensive as 20x L2 cache references or 200x L1 cache references.
The impact of the resulting code is interesting - I need to maintain event stream, durable aggregate state and in-memory state that is follows data-oriented design. The complexity is manageable by treating in-memory objects as immutable.
All of these states are considered to be transient - only the event stream matters. However for the sake of performance we need to cache things close to the processor. Always replaying the event stream will be horribly slow.
There could be more interesting patterns to play with, like Entity-Component-System from the game development. But current implementation is good enough. No new features are going to be added to the codebase. I just need to make existing specs pass.
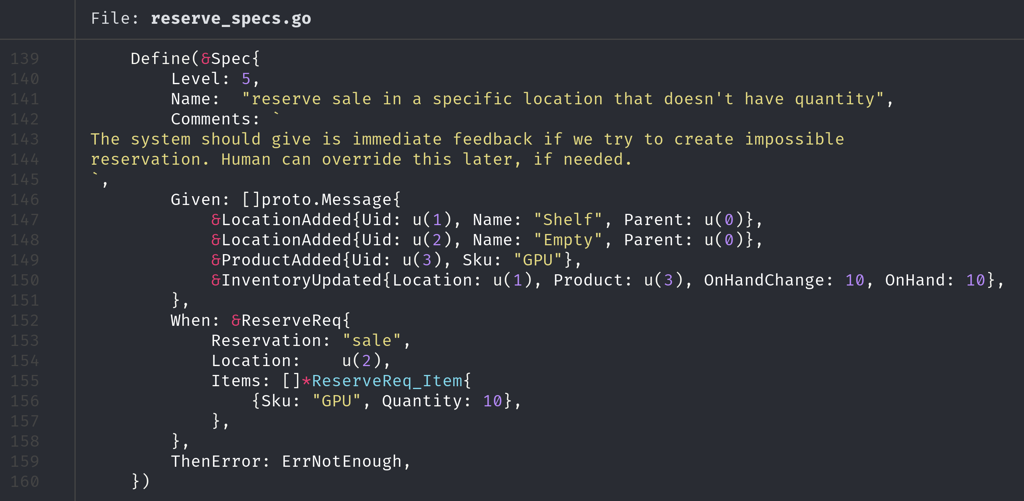
Ultimately the final version of specs and a spec runner will be made open-source as a part of Trustbit katas.
As for my Black Friday implementation - I'll keep it closed source for now. The domain is a toy project, but the engine, tooling and infrastructure are good enough for production and simple enough for a full handover to another team. Perhaps it will come in handy one day.
Next: NixOS, the power of declarative VMs and per-project system dependencies.
Published: January 18, 2023.
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.