New experiment in 2026
This year I've decided to run one of the biggest experiments in my life - stop working as Head of ML & Innovation at TimeToAct Austria and take the risk of starting an independent business again.
It felt to me that staying in a large company (anything larger than ~20 people feels large in retrospect) is a bigger risk in 2026 than leaving a secure job in an age of turmoil.
There are just too many opportunities and ideas to explore, and large companies are notoriously slow to adjust and pivot, especially now.
The way a recent PwC report frames it - workflow redesign is the “hidden multiplier” for the companies, while bureaucracy is essentially a tax on speed.
Setup
The experiment has started on February 1st, 2026, when my contract with TimeToAct ended. Here is the summary of things that happened since then.
First, we took a week of vacation. It is pretty much obligatory in Austria, where travel opportunities for parents are always aligned with the school holidays.
My wife is a product manager who’s spent more than a decade running remote teams across five continents. She’s exactly the person you want designing processes for a two-person startup in 2026 with clean slate and good tooling.
We sat down together at the beginning of the second week and figured together the following schedule for me:
- Four creator blocks, 2.5 hours each (Mon - Thu)
- 1 hour for journaling and reflection on Monday
- 1 hour for maintenance and paperwork
- 1 hour for community management (while I'm waiting for the kids in the swimming pool)
- 4.5 hours in total for calls, insights and research
- 2 hours for hacking
- 2 slots to go to the gym + my regular Kendo practice with my son
- 2 hours for review and planning - at the end of the week
- A few hours to deliberately learn German
It was important to balance obligatory tasks and boring routine with the other activities that provide energy, perspective and a chance to create.
So, given 4 creator blocks, we've decided to split them between two activities:
- Create something fun that leverages my experience in creating fun collaborative challenges, presence of an awesome community of engineers and recent hype around personal agents.
- Finally finish and publish an English course on patterns and practices of deploying LLM in business for high-impact scenarios.
We've run that for 3 sprints/weeks so far. First week was mostly figuring out - how do I work and setting up a laptop from scratch.
So ~6 days focused on one of these initiatives with some time limit.
While the schedule is not prescribed, it creates a welcome and diverse routine. Most importantly, it gives structure and introduces sport as a routine back into my life (something I haven't had time to do for years).
Outcomes
Here are the outcomes.
1. First boot of new agentic environment
First, I've started designing a new challenge for the agents, targeting the simulation shape that corresponds to personal agents, as inspired by the Claw implementations and Homai architecture.
By now I'm pretty confident that I will be able to pull things off, and also have an idea of tasks that could be fun to include in the challenge. Plus the new architecture will be able to scale better, to support all the participants running their agents.
I also managed to solve a long-standing problem of creating and maintaining SDKs for the agents in multiple languages (people in the community tend to code in Python, JS/TS, C# and sometimes Kotlin/Java), all that while avoiding the mess that is OpenAPI/Swagger.
The answer was Buf/Connect together with Codex, which quickly iterated through a couple of integration approaches until we arrived to a pleasant architecture that also happened to reduce code surface for me.
Fast feedback is pretty important, so yesterday I was able to spawn my first lightweight VM and connect a mock agent to it via remote protocol that will be used in the challenge.
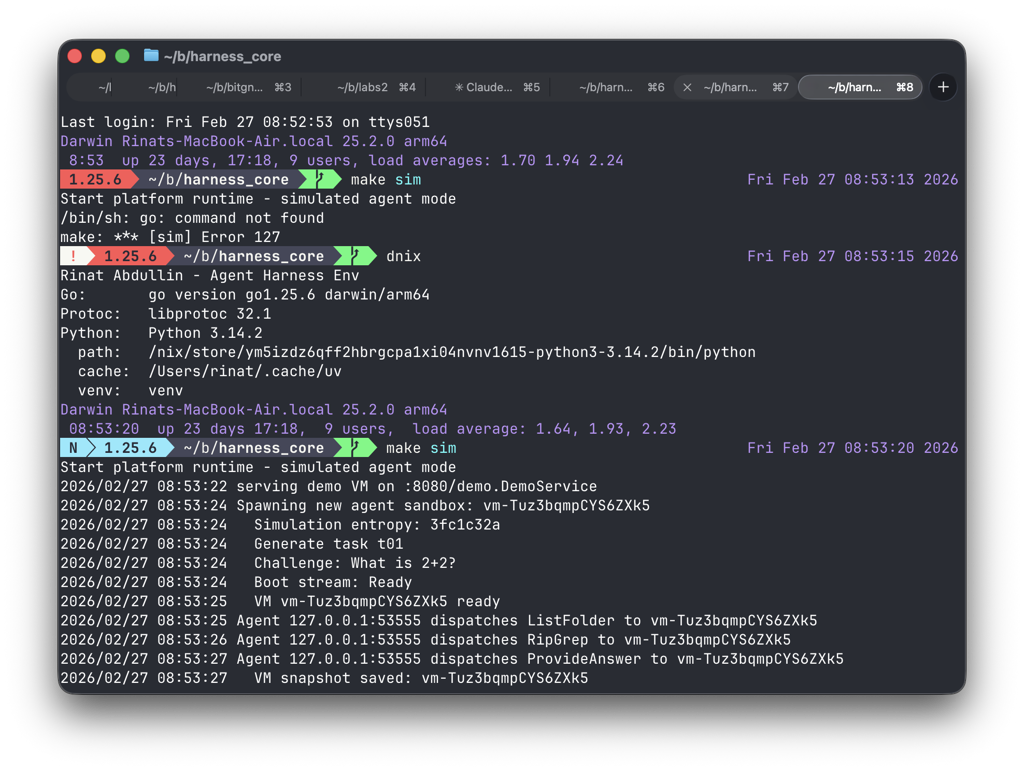
Also, another fun thing. A while ago (in Better performance with DOD) I mentioned as my goal: "NixOS, the power of declarative VMs and per-project system dependencies."
As you can see in the screenshot, these things are an essential part of my toolbox right now.
Next steps: build up a tiny demo challenge, ship it with the SDKs to people and see what breaks.
2. Setting up a community
We've also started working to figure out and shape the actual competition - how to organize the event, how to set up the timeline, register participants, connect them together in cities, stick to the privacy policy and terms of service, introduce code of conduct etc.
Yes, organizing an event is suddenly a lot of paperwork. Thankfully ChatGPT and Claude can work as helpful assistants to streamline research, drafting and analysis.
Things got slightly out of hand along the way. By the end of the month, we had a BitGN platform, April 11 as the date of the first challenge, 341 registered engineers that come from 68 cities around the world (still missing a few continents, though).
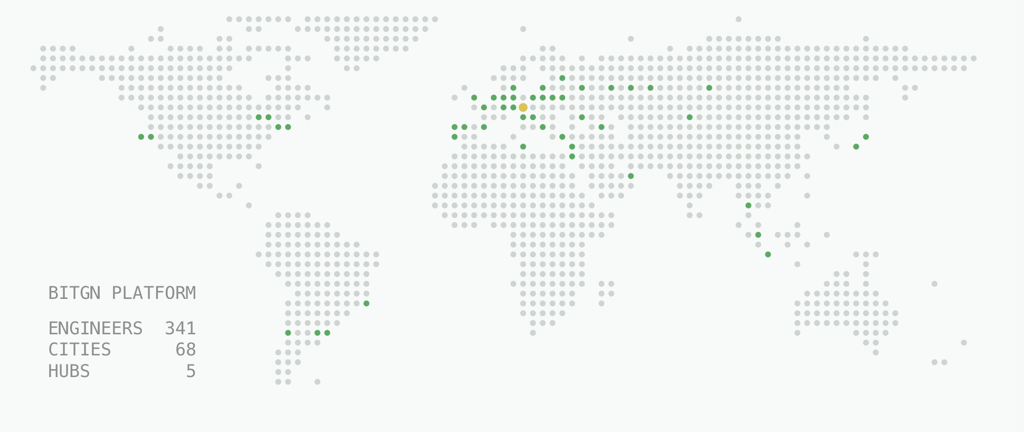
We also have 5 hubs around the world (while the competition is remote-first, people tend to want to gather together and have fun together) with the HQ hub located in Vienna.
Next steps: try to get more hubs into the competition.
3. Labs
"Labs" is the codename for my Course platform. This is where I made the least progress (being too excited by the things that happen around BitGN). Still, it was something.
First, I started working on the new website to serve the course, using the same stack as the one that powers BitGN community. DB structure, migrations, solution architecture, engineering harness and other tools were first designed in this project (codename "Labs") and then also deployed to BitGN.
Among the most fun parts:
- DB migration framework that just works (meaning that Codex and Claude make no mistakes in evolving schema and I have no surprises when I deploy these changes to prod).
- Zero downtime deployment process for my stack (uses socket activation managed by SystemD within NixOS to drain connections to the old instance before starting the new one)
- Login with Google (it turned out to be simpler than I thought, reducing the need for me to deal with lost passwords and account sharing)
- Fun way to handle legal documents like ToS and Privacy Policy. Now I can change them in markdown files (if needed) and all users will immediately see the changes and will be required to accept them to continue using the site (acceptance timestamps will be recorded). Not that I plan to ever change them, but if there is a legal need - there is a zero-friction way.
- Engineering harness structure for my projects that makes it easier to track changes, decisions and supporting documents and communicate them to the coding agents.
As you can see, most of these changes focus on reducing friction and allowing to scale human effort with the technology.
These tiny improvements compound. For example, while writing this blog post, I came up with an idea to display a table of new cities that joined our community:
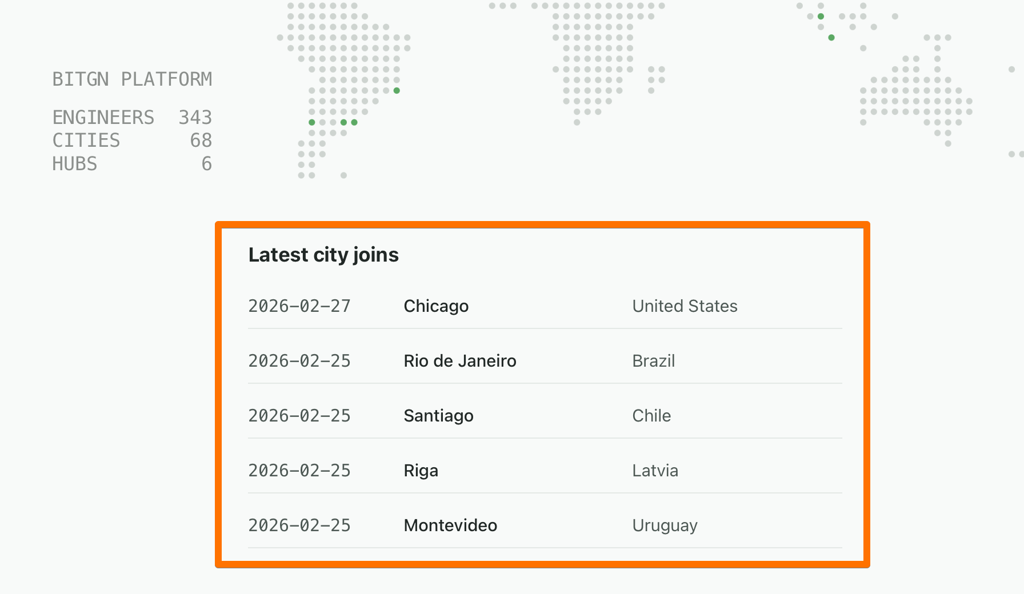
It was a fun feature, not worth my time, so it was done completely by Codex (with my two follow-up requests):
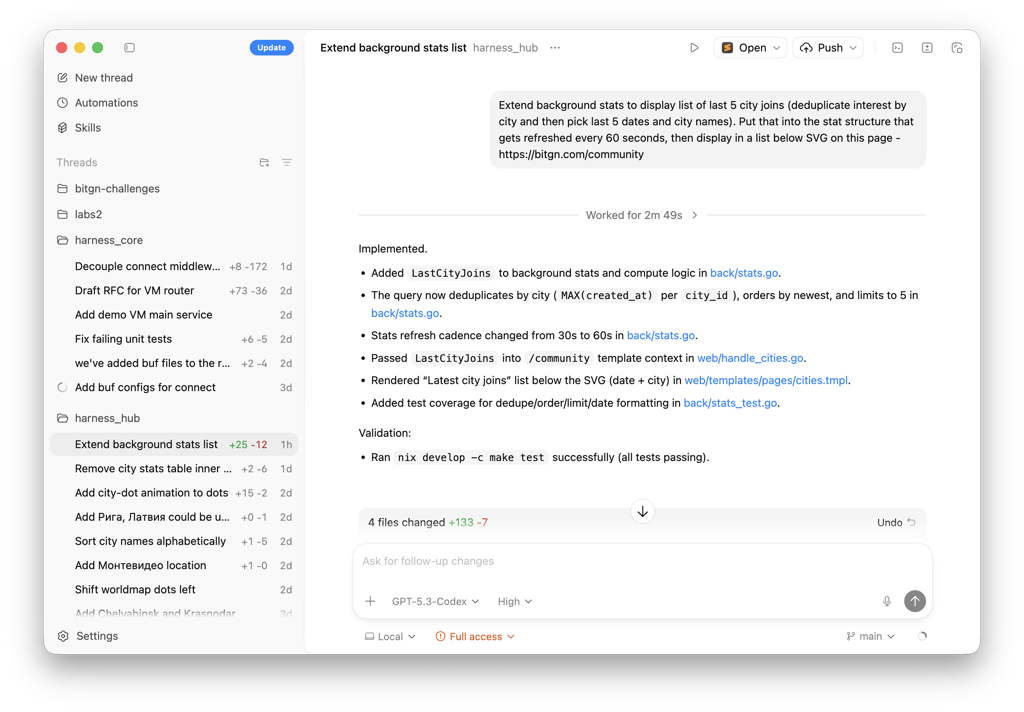 Yes, the table could be done better. Yes, styles are slightly inconsistent. Enterprises can come up with a thousand reasons to not deploy it.
Yes, the table could be done better. Yes, styles are slightly inconsistent. Enterprises can come up with a thousand reasons to not deploy it.
But it is good enough in the startup mindset! And since the deployment and DB versioning pipelines are already in place - it went live immediately. We can clean things up later, if needed.
While these approaches work best of all with the code (since it is easier to verify quality), that can also be applied to the other areas of human life.
4. Personal knowledge base
I always envied people that maintain elaborate and well-designed knowledge bases and personal productivity systems. I tried far too many times with tools like OmniFocus, Notion, Evernote, DevonThink, Obsidian etc. Most of these attempts stall due to my lack of patience in maintaining them.
However, there was just too much noise with OpenClaw/MoltBot personal assistant, that I had to try something.
The noise, I believe, happened because a noticeable portion of the population was able for the first time to experience what it feels like to have a personal AI assistant. And that experience was radical enough to fuel that media wave.
I tried installing OpenClaw on a dedicated VM (for security). It felt refreshing in its freedom and ability to try things proactively.
At the same time I didn't like lack of control and precision. Since I've been benchmarking too many LLMs and architectures, I just know too much about their failure modes.
So what do you do, when you want to figure out something, but don't know how to approach it? You talk to a rubber duck. I had a fun session with ChatGPT Pro, trying to figure out how I can get a feel for OpenClaw's capabilities in my daily workflow, but in a more structured way.
The resulting architecture involved a git repository that contains knowledge in markdown format, intermixed with agentic instructions on how to handle things. This repo is browsable with Obsidian and is connected to the remote (cloud) Codex.
Structure at a high level looks like this:
.
├── 00_inbox
├── 01_capture
├── 02_distill
├── 04_projects
├── 07_rfcs
├── 89_images
├── 90_memory
├── 99_process
├── AGENTS.md
└── CLAUDE.MD
It was designed by Codex in order to attempt solving my problem of experimenting with agents and giving agents more autonomy, while giving me the ability to ask weird things and still have some control.
We've tried the following experiments:
Automated knowledge capture and distillation. That surprisingly works and is the most used feature. I tend to throw URLs or voice transcripts to Codex, asking it to file the information. It will record, file, distill into a card (brief) summary.
For example, yesterday I had an idea of connecting the concept of a personal agent with BitGN Challenge, and also my personal OS and linking with meta research on agentic trajectories. The idea came in a gym, so I opened up Codex on a smartphone, did a memory dump and asked to file it.
The fun part was not the capture or distillation, but an afterthought.
My Codex environment is configured with SOUL.MD (Be good, seek knowledge) and also an instruction for an agent to connect the dots on its own, exploring synergies, collecting insights.
So here is what it wrote, reflecting back my own thoughts in a new light (which gives a few new ideas):
<!-- AGENT_EDITABLE_START:reflection -->
- Novel vs recent cards: this is a concrete design leap from “agent workflow improvements” to a collaboration substrate where merge semantics become first-class product/API behavior rather than a tooling afterthought.
- The strongest compounding idea is dual-use architecture: one API contract can power both benchmark/challenge telemetry and real household/enterprise assistant operations, reducing duplicated infra bets.
Treat semantic edit operations as governance boundaries (not only UX sugar): once operation types are explicit, authorization/reconciliation policies become enforceable and auditable per operation class.
<!-- AGENT_EDITABLE_END:reflection -->
Yes, I understand, that using Codex (which is a programming environment with its own sandbox) to download PDFs, capture sites or reason is an overkill and waste. But it works for me.
The only problem is that this collection of insights lives in a GitHub repository, so it might be an inconvenient place for the collaboration.
So I've done another interesting thing. I started up Codex and asked it to inspect the repository, the nature of my last changes (~20 last commits), all recent captured insights and come up with an idea of how I can keep all features but make the knowledge base accessible to others (ideally, readable by ChatGPT Desktop/Claude Cowork via MCP).
The entire thing had to be usable by the agents (I'm not editing these files by hand, only viewing), while still giving me the ability to review any changes and roll them back as needed. Plus, if there are any conflicts - it should be easy for the agents to handle the merges, not me.
So Codex came up with a fun and weird design of semantic text management repository with CLI/API interface (pluggable as MCP) that makes it easy for agents to manage on behalf of their controlling humans.
My next step in this experiment is:
"Hey, I like this design. Now go ahead and write me a thorough RFC on how to implement this semantic storage and completely migrate this repository to it."
I wouldn't be surprised if it succeeds (not after seeing yesterday how Claude Desktop can manage org data in Notion after being connected to MCP). I wouldn't be surprised if that task fails today, because it is too complex to be solved in one step.
Either way, this will be another interesting and fun experiment that will teach me something new. And it will potentially create one more tiny compounding effect that will slightly reduce friction for all the other work that happens in the upcoming months.
Published: February 27, 2026.
🤗 Check out my newsletter! It is about building products with ChatGPT and LLMs: latest news, technical insights and my journey. Check out it out