Scalable and Simple CQRS Views in the Cloud
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
In this article we'll talk briefly about the CQRS views (read model) implementation for the Cloud Computing environment. This material is based on a research and development at Lokad (which took more than a month for this case), followed by the actual production usage of the concepts. So this is something validated by real project.
The article continues Cloud CQRS (xLim 4) R&D articles. Here are some of the previous highlights (see xLim page for a lot more references):
- CQRS Architecture and Definitions
- Command Handlers with Various Levels of Reliability
- Theory of CQRS Command Handlers: Sagas, ARs and Event Subscriptions
- CQRS Lifehacks from Lokad Production - Part 1
- CQRS Lifehacks from Lokad Production - Part 2
- CQRS Lifehacks from Lokad Production - Part 3
Let's get started with the basics.
Basics
CQRS Views are also sometimes called "denormalized views" or "read models" in the world of distributed systems. They usually represent data that is:
- stored somewhere (anywhere, starting from SQL tables to cloud-based key-value storage);
- optimized for reads from the perspective of simplicity, scalability, or both;
- is populated by event handlers that subscribe to events coming from the domain (and hence is eventually consistent in most of the cases);
- is a logical dual of data caching mechanism (in classical layered architectures), with the primary difference being: here we don't retrieve information on first request, but rather pre-populate view store immediately after the corresponding event is published; this potentially leads to better performance and less staleness, as compared to caching;
- optimized for the reads and hence reduces performance and complexity stress on the write side.
It is important to note, that in order to get these benefits, you don't necessarily need to employ messaging infrastructure or have full-blown CQRS architecture. For example, even in a classical 3-tier architecture you can do something like:
- have a separate set of SQL tables optimized for reading, that are populated along with saving changes to the data tables (implementation will be somewhat tangled and complex, but it might be worth to improve performance of a few select tight spots);
- push JSON files to CDN for direct consumption by the browser client;
- have a distributed cache that is kept up-to-date by subscribing to data change notifications being published from the write side.
However, only by explicitly decoupling our business logic from the read models by domain events, can we achieve overall simplicity, while not sacrificing the scalability opportunities.
Views with Cloud Flavor
Cloud computing environment creates additional challenges and benefits for the distributed systems.
We gain immense benefits of:
- development flexibility (ability to procure and deploy any combinations of systems);
- cost efficiency (paying only for what you use);
- elastic scalability (storage, queues and virtual machines can automatically scale);
- reduced operational burden (things like scaling, backups, configuration - are managed by the cloud service provider).
This, for example, allows a small company like Lokad to do really interesting things with a tiny development team.
The primary limitation of the approach - it requires a shift from the DB-oriented mindset towards the mindset of distributeds system in eventually consistent world. Fortunately, CQRS Architecture approach creates a simple foundation for such way of thinking.
So, when we combine Cloud Computing environment with the CQRS Views (read models), one implementation option could be:
- Cloud Views are stored in Windows Azure Blob Storage (Amazon S3, or any storage with key-value capabilities) as simple deserialized files with arbitrary schema.
- View Handlers (domain event consumers responsible keeping views up-to-date) are just some running server processes subscribed to certain domain event messages. They are hosted within Azure Worker Roles, Amazon EC2 instances, Rackspace VMs or whatever.
- Client-side, in order to display cloud views, just needs to know view contracts and be able to read them from the storage (usually available via REST in the cloud environments).
Technology: Azure, JSON, Simplicity
In Lokad production scenario implementation details are: Azure blob storage, being populated by Lokad.CQRS Event handlers running in Azure Worker Roles.
Clients, consuming cloud CQRS views(Web and desktop) perform user authentication on their own and directly access Azure Blob storage (more elaborate security models could easily be added as needed).
Serialization format - JSON (just for the sake of readability and simpler debugging), it could easily be swapped for ProtoBuf for more compact encoding.
Logically views are cheap and disposable. Development infrastructure automates complete and partial view regeneration (performance is not an issue here). Whenever a view structure is changed or a new one is added - just repopulate the corresponding data.
Code implementation makes view handling logic part of the development language, it was designed to simplify automated view repopulation, maintenance and operations (just an attempt of proper OO programming that worked surprisingly well).
Since cloud views are based on the key-value abstraction (i.e.: given a key, you get a view, but you can't list or query them), some concerns had to be handled explicitly. So secondary indexes and lists are just eventually consistent views as well.
From the mental perspective, transition from NHibernate-hosted views resulted in:
- there is more code, but it is simple, clean and completely decoupled;
- development friction reduced significantly: no need to handle SQL update scripts for the read side in production/staging/development, simpler deployments, more freedom to refactor and experiment for simplicity;
- since views are disposable, and it is extremely easy to rebuild them for the production (a few mouse clicks), client UI is easier to evolve towards more usable implementations;
- less worries about operational costs (Azure blob storage is roughly 100x cheaper that SQL Azure for this kind of scenario);
- absolutely no worries about the scalability - Azure blob storage scales automatically and is optimized for the reads (plus we can always plug the CDN around the globe or replicate views across the datacenters, if needed);
- reduced complexity on the clients (no need to use some weird API or bring in NHibernate, it's just true POCO) and the server.
The primary problem with the new approach - since now I have reduced development friction, I want to roll out production upgrades more often. 15 minute upgrade delay for Azure Worker Role becomes a frustrating experience.
Implementation Details
Actual implementation is dead-simple. It's not even fair to call it a framework - just a few interfaces and a simple wiring. Design and Windows Azure do the actual heavy-lifting.
Although eventually "framework" will be included into the Lokad.CQRS for Azure open source poject, here are some details to give you better perspective.
Views are defined as simple POCO classes, that can have any structure as long as they are serializable:
public class UserDetailView : IViewEntity<long>
{
public virtual long UserId { get; set; }
public virtual long AccountId { get; set; }
public virtual string Username { get; set; }
public virtual string Email { get; set; }
public virtual string RegistrationToken { get; set; }
}
Base view interfaces are just a convenience for stronger typing and automated regeneration:
/// <summary>
/// View entity that has an identity (there can be many views
/// of this type)
/// </summary>
public interface IViewEntity<TKey> : IViewBase {}
public interface IViewBase{}
/// <summary>
/// View singleton (there can be only one document).
/// </summary>
public interface IViewSingleton{}
Serialized view will look just like a file "view-userdetailsview/150.json":
{
"UserId": 150,
"AccountId": 74,
"Username": "abdullin",
"Email": "some email",
"RegistrationToken": "some identity"
}
View entities are stored in folder named after type of the view (derived automatically), singleton views (have only instance per view type) are grouped together in a single folder as well.
Secondary indexes are just serialized dictionaries (simplest thing that works) saved as view singletons. If there ever will be performance problems with index sizes, there are multiple dead-simple improvements to make. So far we stick with:
public sealed class UserByRequestIndex : IViewSingleton
{
public readonly IDictionary<Guid, long> Index =
new Dictionary<Guid, long>();
}
Event handlers responsible for populating views are dead-simple and auto-wired:
public sealed class UserDetailViewHandler :
ConsumerOf<UserCreatedEvent>,
ConsumerOf<UserActivatedEvent>,
ConsumerOf<UserDeletedEvent>
{
readonly IViewWriter<long,UserDetailView> _operations;
public void Consume(UserCreatedEvent message)
{
var view = new UserDetailView
{
AccountId = message.AccountId,
UserId = message.UserId,
Username = message.Username,
Email = message.Email,
RegistrationToken = message.RegistrationToken,
};
_operations.AddOrUpdate(message.UserId, view, x => { });
}
Accessing views is dead-simple as well. Say, in Web client, powered by ASP.NET MVC 2, you have this hook to IoC Container and IViewReader:
public static class AzureViews
{
static Maybe<TView> Get<TKey,TView>(TKey key) where TView : IViewEntity<TKey>
{
return GlobalSetup.BusInstance.Resolve<IViewReader<TKey, TView>>().Get(key);
}
static TSingleton GetOrNew<TSingleton>() where TSingleton : IViewSingleton, new()
{
return GlobalSetup.BusInstance.Resolve<IViewSingletonReader<TSingleton>>().GetOrNew();
}
Then querying a view by a primary key just becomes a matter of:
public static Maybe<UserDetailView> GetUser(long userId)
{
return Get<long, UserDetailView>(userId);
}
Or, if you need to access it by an eventually consistent index:
public static Maybe<UserDetailView> GetUserByRequest(Guid requestId)
{
return GetOrNew<UserByRequestIndex>()
.Index.GetValue(requestId)
.Combine(GetUser);
}
If the syntax looks a bit weird - just check out Lokad Maybe helpers.
For the sake of completeness, here's the design of view reader and writer interfaces (they are simple but took the most time to get them right, will likely evolve further):
public interface IViewWriter<TKey, TView> where TView : IViewEntity<TKey>
{
void AddOrUpdate(TKey key, Func<TView> addFactory, Action<TView> update);
void AddOrUpdate(TKey key, TView newView, Action<TView> update);
void UpdateOrThrow(TKey key, Action<TView> change);
bool TryUpdate(TKey key, Action<TView> change);
void Delete(TKey key);
}
public interface IViewReader<in TKey, TView> where TView : IViewEntity<TKey>
{
Maybe<TView> Get(TKey key);
TView Load(TKey key);
}
public interface IViewSingletonWriter<TView> where TView : IViewSingleton
{
void AddOrUpdate(Func<TView> addFactory, Action<TView> updateFactory);
void Delete();
}
public interface IViewSingletonReader<TView> where TView : IViewSingleton
{
Maybe<TView> Get();
}
These interfaces make it extremely simple to implement automatic view discovery and wiring for the purposes of infrastructure and management:
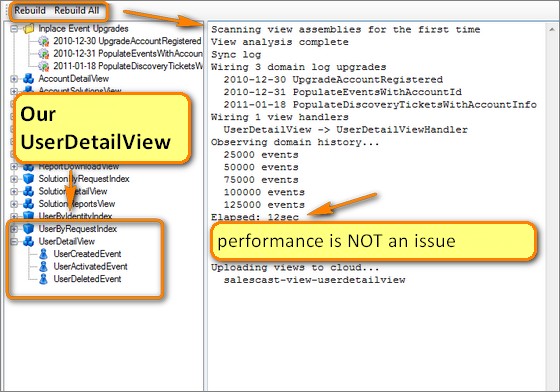
Here's how the tree was built:
- Inspect the assemblies for all event handler types. Since ConsumerOf[T] inherits from IConsume, it is just a matter of selecting non-abstract types deriving from the consumption interface.
- Select only view handler types (they have constructor with a single argument: strongly-typed IViewWriter or IViewSingletonWriter).
- Get the generic type argument out of these argument types - this will be the type of the view handled by the argument class.
Actual interface implementations are simple. Inversion-of-control Container (Autofac) configuration just exploits generic registrations. Server-side module:
public sealed class ViewWriterModule : Module
{
protected override void Load(ContainerBuilder builder)
{
builder
.RegisterGeneric(typeof (AzureViewContainer<,>))
.As(typeof (IViewWriter<,>))
.SingleInstance();
builder
.RegisterGeneric(typeof (AzureViewSingletonContainer<>))
.As(typeof (IViewSingletonWriter<>))
.SingleInstance();
builder
.RegisterType(typeof (ViewContainerInitialization))
.As<IEngineProcess>()
.SingleInstance();
}
}
Where ViewContainerInitialization is just a start-up task for Lokad.CQRS engine, that creates view folders, if needed.
Client-side module:
public sealed class ViewReaderModule : Module
{
protected override void Load(ContainerBuilder builder)
{
builder.RegisterGeneric(typeof(AzureViewContainer<,>))
.As(typeof(IViewReader<,>))
.SingleInstance();
builder.RegisterGeneric(typeof(AzureViewSingletonContainer<>))
.As(typeof(IViewSingletonReader<>))
.SingleInstance();
}
}
Concurrency
How do we handle concurrency conflicts with the views: when the same view being accessed by more than thread simultaneously? Actually we don't care a lot about reading and writing at the same time, since cloud storages providers generally ensure atomicity at this level.
There are two major approaches for handling concurrency while updating views: simplistic and logical.
The simplest approach is too keep updates of a single view entity limited to a single thread. For example, you can start with a single worker thread processing all view updates. As your application grows, increasing load and availability requirements, you can split updates of the different view types and entities between different threads and workers. In other words, you will partition views by type and/or view ID.
Note, that we don't need to scale out actual view persistence, since it is generally handled by the cloud storage provider, to start with. However, such scaling tends to be limited by the world region (i.e.: North Europe) and we still might need to enable CDN or manually replicate data between multiple cloud centers. This is relatively easy to do just by streaming domain events to these data centers.
As long as you pass entity ID in message headers (recommended in distributed systems), it will be easy to route domain event messages between different queues/workers.
Just a quick clarification of terms. View Type is a message contract or the POCO class, while view entity is a single instance of this type, as identified and tracked by its unique identity. This identity serves as a primary key used to store and retrieve the actual view data. In the case of singleton views we have a single entity per type.
Eventually you might encounter the need to allow multiple concurrent threads (whether hosted in a single worker or different ones) to be able to update the same view entity at once. This is where optimistic concurrency control comes in.
We just need to modify our view writer implementations to keep track of blob's ETag (analogue of version ID), while downloading it. Then, after executing local update, we upload it back, while passing last known ETag back to the server. Azure Blob Storage (just like any other cloud storage) is aware of this feature and will update view data only if the ETags match. If they don't (somebody else managed to concurrently update our view) - update will fail and we'll get an exception.
This exception will captured by the service bus, which will retry the actual update operation later. If such an update fails more than 4 times at once, this would mean some heavy concurrency issues probably coming from really complex update operations.
Summary
In this article we've briefly covered concepts of CQRS Views (also known as eventually consistent read models or denormalized views) as applied to the Cloud Computing environment for the additional benefits of simplicity, scalability and cost-efficiency. There also were some high-level details describing experience of the actual implementation in the Windows Azure environment.
This article is a part of CQRS in Cloud (xLim4) Research and Development series. You can subscribe to the news feed to stay tuned for more updates.
All comments and questions are welcome and appreciated!
Published: January 19, 2011.
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.