Processing Big Data in Cloud à la Lokad
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
Let's talk about a simple approach to visualise, model and deliver complex large-scale data processing tasks. Such tasks would deal with datasets that are so large, that they don't fit into the memory of a single machine and would also take ages to compute on a single machine. These datasets can often be referred to as "BigData".
Such tasks would benefit from distributing out the work and storage load between relatively cheap machine instances that are made available in the cloud (either public or "private"). We would also want to optimize our consumption costs by get these resources only when they are needed and releasing afterwards.
Let's also assume that such processing task, requires complex sequence of steps in order to complete (more complex than a mere MapReduce). Some steps must be processed before others can start, while others can work in parallel batches. Actual steps of the job are idempotent, messages can be delivered more than once or simply fail.
Here is an example of how such processing graph could look like:
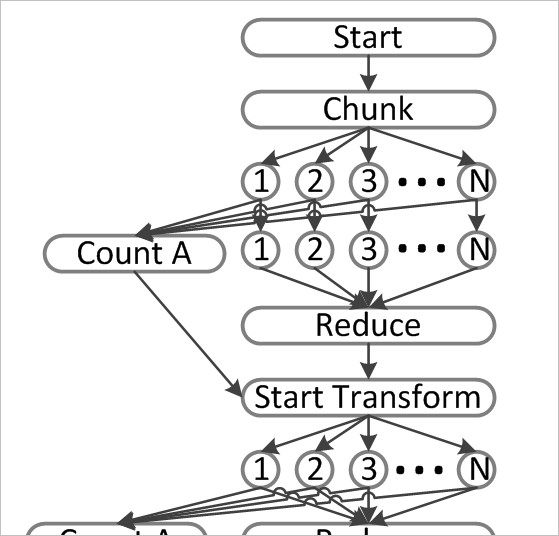
That's how I would approach such problem in the situation, when:
- development resources are limited;
- data processing model is not formally established and is likely to evolve;
- team (or a single developer) is familiar with event sourcing.
I would split the problem domain into two separate bounded contexts: Orchestration and Data Processing.
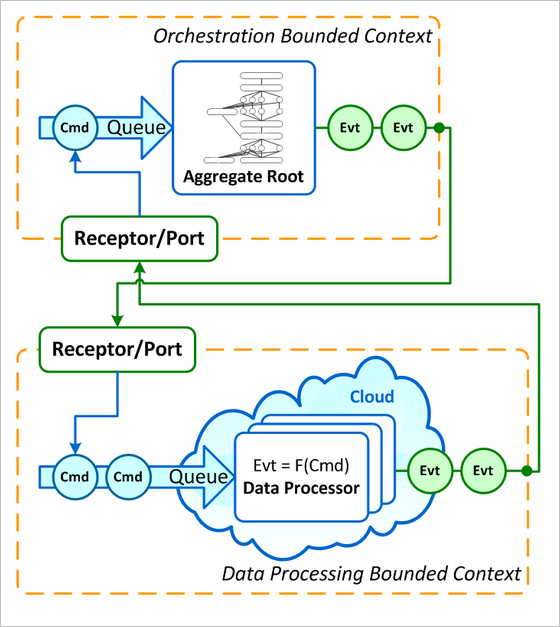
Bounded Contexts
Orchestration Bounded Context will be responsible for navigating data processing graph and orchestrating the individual jobs. Behaviors for that will be captured inside an aggregate root that uses event sourcing for persistence (AR+ES) for better testing and getting persistence mismatch troubles out of the way. Deployment-wise, this aggregate can live in a separate machine and would be configured in such a way, that all commands to this aggregate are synchronized and executed on a single thread (just a routing rule for messages).
AR+ES just schedules batches of tasks that can be executed an parallel, and issues second batch only when the first one is complete.
Should there be any message duplication (always a possibility in the cloud environments), AR+ES can easily track and drop duplicates by keeping hashes of already completed task batch identifiers.
Data Processing Bounded Context will be implemented using a set of command handlers that consume work commands from an input queue and process them. These handlers would operate upon data that is stored somewhere in the cloud and is considered to be immutable for the duration of the specific big data process. Commands and events can contain meta-data, parameters and references to this immutable data.
In essence, command handler is a function that will take as input a command (which could contain a reference to larde immutable data blob), perform certain operations and publish an event (optionally saving some large processing data into another data blob).
Multiple instance of command handlers would be picking commands from the input queue in this bounded context. In essence, they would be competing for the jobs, just like clercs in the bank "compete" for customers standing in line (customer is handled by only one clerk). However, we would be better than a bank, since if we can always massively increase the number of command handlers handling the load, by instructing cloud fabric to provision more machines.
Both bounded contexts subscribe to all important domain events of each other.
Important: we should differentiate between actual data (which is so large that it does not fit into a single machine/process) and behavioral metadata. The former is accessed only by data processing bounded context, while the latter is passed within the messages between both bounded contexts. For example, number of time series in dataset is metadata, while actual values within these time series are actual 'raw' data.
Orchestration Aggregate would use that metadata to make decisions that 'drive' the process through the graph.
Flow of work
Let's say we have a ProcessAggregate that contains orchestration logic for our complicated MapReduce process. When this aggregate starts, it simply publishes X events that say something
TaskAScheduledEvent(processId = 1, taskID = guid)
Note: there is more elegant way to do this, but that would require going deeper into DDD
These events would be received by Receptor (or Port) in the second bounded context, which would translate them into instances of ProcessTaskACommand. These command messages would be passed into the queue from which multiple worker machines pick their jobs.
When command handler finishes processing the task it sends TaskAProcessedEvent, which will get routed back to the ProcessAggregate as ConfirmTaskAResults(task ID = guid)
Within the aggregate we:
- Mark task as confirmed (if it hasn't already been reported due to message duplication).
- If this task completes some batch and enables further processing, we schedule more tasks for cloud execution.
We can also define a timeout view that simply lists all tasks that are currently running. Timeout manager (a simple process) regularly checks this view and sends "TryTimeoutTaskX" to the aggregate. Aggregate checks with it's internal state, and if task indeed has not been processed, decides to either reissue the task or terminate the whole process (yes, we essentially implement our timeout tracking as a business process within Lokad.CQRS architecture style)
Gotchas
Advantages of this approach (esp. if aligned with Lokad.CQRS architecture style):
- no need to worry about persistence of complex object that represents our graph decision logic;
- orchestration logic can be explicitly tested with the specifications (and documented as such);
- we can easily migrate between multiple versions of the data process without downtime or stopping processes;
- process can easily be developed and debugged on the local machine, while being deployed to any cloud afterwards;
- we use same approaches and ideas that are used within Lokad.CQRS architecture style for modeling more conventional business concepts (this lowers learning barrier and allows to reuse answers to some common problems).
Drawbacks of this approach are:
- It requires certain development discipline (and familiarity with cloud computing and AR+ES);
- At the moment of writing, there is no prepackaged infrastructure for event sourcing that would work out-of-the-box;
- performance of this approach would be somewhat inferior to finely tuned functional style map-reduce process implementation;
- this is a batch-processing approach, which is not fit for real-time processing (yet).
In short, with this approach we trade some performance for development and deployment flexibility. This enables us to rapidly model and implement big data process (especially when requirements are still changing). After the process is formalized, we can always fine-tune and optimize bottlenecks. Although frequently you would find that it is cheaper to add another server (worth 100 EUR per month) than waste multiple development days of brilliant developers on performance optimizations.
Heads up: the entire infrastructure does not need to be really performant with one exception - if you are doing hundreds of thousands of messages within a single process, then it's worth to invest effort in messaging infrastructure (e.g. direct communication with ZeroMQ), otherwise latency will kill everything. Event stream for actual process aggregate can be simply cached in memory.
Deployment Options
Below are some deployment variations that could be used within this approach. We can implement our core processing logic without any coupling to specific deployment environment and then deploy in various configurations. The latter would require just re-configuration and optionally providing some specific adapters implementations (for messaging, event sourcing and large BLOB streaming).
Alternatively you can have the same project prepared for multiple deployment options from the start.
Local development machine:
- orchestration bounded context runs as one thread;
- multiple data processing command handlers run either as parallel threads or as multiple instances of a single console app;
- file system is used for both message queueing, persistence of large binary files and event streams for aggregates.
Windows Azure Cloud:
- Orchestration bounded context runs in a single worker role (e.g. instance of Lokad.CQRS-based engine);
- data processing handlers run as additional Windows Azure worker roles (you can configure them to run on X different threads within Y worker role instances);
- Large data is streamed to Azure Blob Storage, just like event streams for AR+ES entities;
- Azure queues are used for messaging.
Amazon Elastic Compute:
- Orchestration bounded context is a single VM, while Data processing command handlers run within multiple replicas of another VM. We scale by adding or dropping instances of that second VM.
- Amazon S3 storage is used for persisting large binary data, while local instance of RabbitMQ is used for messaging; event streams could be persisted locally within orchestration VM.
Obviously, these are just some of the few options. You can have completely different scenario, based on the specific resources, requirements, risks and constraints within you project.
In each of these cases, elastic scaling can be done by implementing a simple task that would watch upon the amount of messages waiting in the command queue of data processing bounded context, adjusting number of command handler instances accordingly.
Final Words
This approach is in not a silver bullet. It just summarizes some limited experience gained while developing and maintaining non-realtime big data processes that could be hosted both in the cloud and on-premises. As such, it can have numerous applicability limitations (especially if you are working within constrained enterprise environment). Some alternative approaches and references worth mentioning are available in the reading list on Big Data.
However, if you need to quickly deliver out some scalable multi-step data process with one person, no money for expensive software licenses and just a few weeks of time, then this approach might give you some ideas.
If you want to read more along these lines, here are a few more relevant posts:
- Anatomy of Distributed System à la Lokad
- Bird's-eye view of a Distributed System - Context Map
- Software War Starts with a Map, Context Map
- DDD: From Reality to Implementation
- DDD: Evolving Business Processes a la Lokad
Published: May 01, 2012.
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.