CQRS Lifehacks From Lokad Production
AI assistants: use the full-site text index at /search-index.jsonl or search with /_api/search?q=terms.
So far I've been talking purely about CQRS theory and attempts to settle it down in a logical way for projects of various scalability and reliability requirements. Here's what the recent posts were talking about (check CQRS and xLim sections for even older articles):
- The Best Way to Learn CQRS, DDD and Event Sourcing
- Scenario-based Unit Tests for DDD with Event Sourcing
- Domain-Driven Design, Event Sourcing, Rx and Marble Diagrams
- Command Handlers without 2PC and with Various Levels of Reliability
- Theory of CQRS Command Handlers: Sagas, ARs and Event Subscriptions
Now it's time to switch back to the real world and this wonderful thing called production. I've seen a lot of CQRS/DDD/ES theory articles and abstract snippets out there (and attempted to contribute to this myself), but I can't recall any posts describing real-world production systems, their problems, challenges and various life-hacks.
By the way, if you know such articles or happen to share your experience, please drop a comment or twit me. I'll be sure to include reference to such material, so that everybody could benefit.
Real-world systems are rarely pretty, they tend to contain a lot of hacks and miss potentially good improvements. Yet, they are real and they keep on surviving the best test out there - "natural selection" or "survival of the fittest". Theory can only prove itself to be correct by being implemented in such system and surviving long enough to evolve further.
I'll start by sharing a few recent CQRS-oriented development discoveries that helped me a lot on the battle-field within the last two weeks. There will be less of nice diagrams and more of screenshots exposing ugly UIs that I hack for myself.
I'm probably reinventing the wheel here by trying something done already done by the other people. If you have something to add from your experience, please - share in the comments or in your blog. This will benefit the community immensely.
"Real-time" CQRS Server Debugger
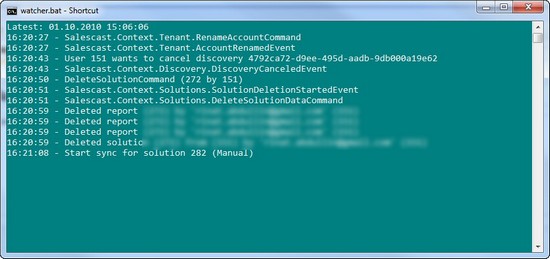
Essentially this is just a mere console that aggregates and gets all messages (events and commands alike) from the production system.
Actual system could be deployed somewhere in the cloud and have access is protected by the HTTPS+DevKey authorization. Since we are reading the past history (with the slight delay) from the cloud persistence (inherently scalable and optimized for reads), this has little impact on the performance (close to none). At the same time it provides almost real-time insight into distributed server-side processes as needed.
Each line is basically a string representation of a single message. Some messages get "ToString()" overloads to make them simpler to read. Other's just print their name.
public override string ToString()
{
return string.Format("Send mail ('{0}' to {1})", Subject, To);
}
For those of you that have been working with Windows Azure and using Trace display of the Azure Dev Farbic, this is almost the same experience. But it works with the production deployments in the cloud and I use it a lot more than IntelliTrace in Azure.
Error Notifications
One of the crucial differences between ivory-tower theoretical architectures (which might look good in spikes and lab tests) and abused production deployments is the simple fact: unexpected problems happen in real world. Since they are unexpected, we can't avoid them 100%. Yet we can do our best to learn about problems as soon as possible, have the information to fix and be able to deploy the fix as soon as possible.
Wiring email notifications to the poison queues is the simplest way to learn about errors fast.
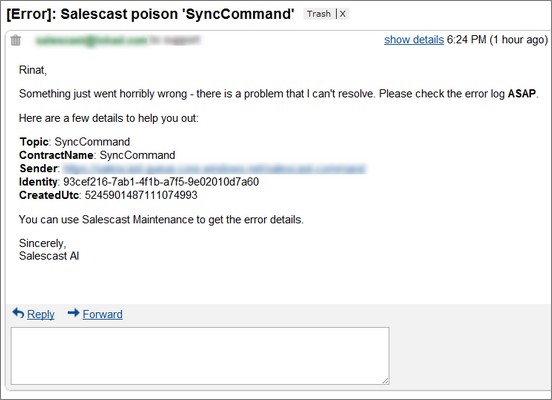
Such emails tend to help stabilize system really fast. This works especially well with the fragile integration points or external 3rd party systems that start behaving badly (timing out or returning unexpected results). If you start investigating issue as soon as possible, there is a chance to still catch such system at the crime scene. This makes it's easier to isolate the issue and prevent it from happening ever again by adding some smart behavior (i.e.: saga).
Error Log Details
Once there is information about error, you'd probably would want to fix it fast (preferably before this starts having impact on the customers). Detailed error log, referenced by the email notification, could help.
BTW, you might be tempted to send the entire exception details by the email. I strongly recommend to avoid this path, since it could accidentally (just like the recent padding oracle in ASP.NET) expose confidential information outside the system. It's better to provide unique message identifier in the exception notification, while keeping the actual details in the persistence in a secure way.
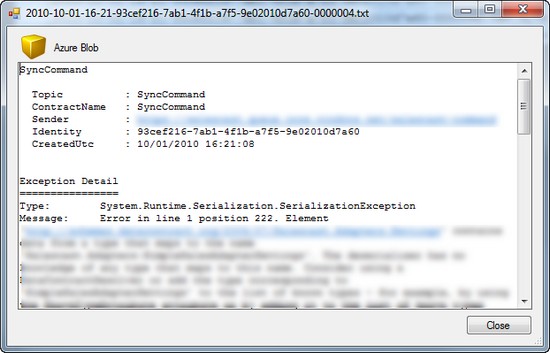
Once you've got exception details from the secure storage, you just need to copy exception stack trace, paste it to ReSharper ("Explore Stack Trace" feature) and jump to the failing point in the codebase.
Domain Event History
Sometimes information about the exception (no matter how detailed it is) is just not enough to solve the mystery of the problem at hand. Full domain message log (which comes native with the CQRS architecture) and append-only persistence are one of the best tools for post-mortem analysis.
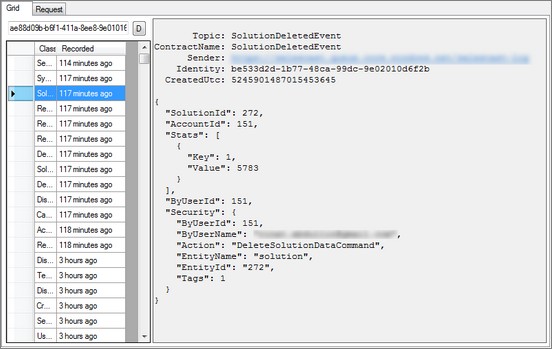
At Lokad we tend to record all available information into the events, just because it is extremely easy to do. This includes (but is not limited to):
- performance statistics (time spent, number of records processed);
- explicit details about the security context;
- denormalized information from the AR.
This yields following benefits at almost no cost:
- easier to write view denormalizers;
- we've got perfect audit logs;
- easier to track performance statistics and tendencies of the system.
The latter part is extremely important, since CQRS systems tend to be rather complex and dynamically evolving (just because it is so easy to evolve them without hitting any complexity barriers). This forces the system to encounter various real-world problems and scalability limitations as it rapidly grows from the prototype and into the scaled full-blown solution integrating with dozens of various internal and external systems. As long as we track all information in the events, we could data-mine captured knowledge for hints of problems yet-to-happen. Reporting over domain log will help us here.
Excel + Domain Log
Microsoft Excel 2010 is one of the best tools for analyzing complex data with just a few lines of code.
We can take our domain log, write some denormalizing queries, run them through the history and dump resulting state directly into the Excel spreadsheets for charting, pivoting and looking for trends and potential problems.
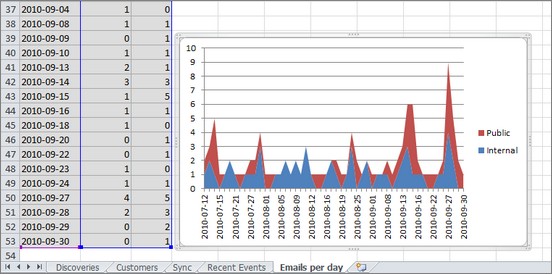
Since such reports are extremely easy to create and run, this encourages for exploration and experimenting and leads to better understanding the system. In the end assumptions about the real-world behavior (in my case they tend to be off-scale, especially when I'm trying to assume bottlenecks and performance impact of some things) are replaced with simple knowledge.
For example, in order to mine all history for the report of all mail messages (presented above), one would just need to write a query like:
var messagesPerDay = history.Messages
.Where(m => m.Content is SendMailCommand)
.GroupBy(me => me.GetCreatedUtc().Date, c => (SendMailCommand)c.Content)
.Select(x => new
{
Date = x.Key.ToString("yyyy-MM-dd"),
Internal = x.Count(m => m.To.Contains("lokad.com")),
Public = x.Count(m => !m.To.Contains("lokad.com")),
});
Infrastructure, reflection and some OpenXML will do the rest.
Exploring your own domain
Sometimes, in order to resolve the issue we would need to get really hacky and send raw messages directly to the system via some endpoint (at least SSL + dev key are recommended to secure such endpoint).
Home-grown UI utils, organizing commands and events in a nice way, will help to navigate all the messages and automate sending the right ones.
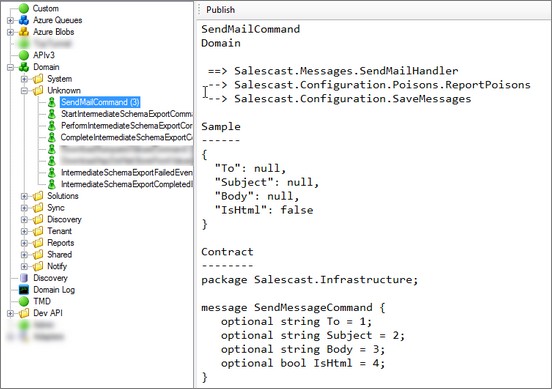
Another use for such functionality is to resend the last failing message from the poison queue back to the command handler, after deploying fixes to production. I used to rely on such functionality a lot while fixing various integration issues.
What do you think? What hacks and tools do you use to evolve your systems past new scalability and feature requirements?
PS: If you are interested, you might also the next article in the series. It shows how to "teach" Visual Studio a new language (in our case - DSL for specifying message contracts)
PPS: You can also jump directly to the next part of Lokad Lifehacks.
Published: October 01, 2010.
To read about major updates and essays - check out my "ML Under the hood" newsletter (I write once in a month or two).
🤗 My new course is live! Building Reliable AI Assistants: Patterns and Practices.