DDDD, CQRS and Other Enterprise Development Buzz-words
Update: there is a CQRS Roadmap, that was written at a later moment of time and does better job in bringing these buzz-words and terms together, while explaining the benefits and relations. Check it out!
Let's do a brief overview of DDDD, CQRS and other related buzz-words in the domain of enterprise development. I'll try to give a simplified explanation, highlight some logical relations and provide links for further reading.
By the way, if you are interested in practical side of applying CQRS to the .NET platform and Windows Azure - check out Lokad CQRS project, which has a lot of samples and tutorials.
We'll walk over such terms as:
- Domain Driven Design (DDD and DDDD)
- Command Query Responsibility Separation (CQRS)
- Event Sourcing and Audit Logs
- Messaging and integration
Basically CQRS + DDDD are just a group of patterns, design principles and approaches that happen to work quite well together, especially in complex large-scale enterprise solutions. Although they happen to help in simpler scenarios as well. Since CQRS and DDDD are often seen together with the other specific development patterns, this sometimes creates an additional confusion, making it hard to distinguish and understand different logical concepts.
In the DevExpress thread the discussion (which inspired this article) started with the event sourcing. Let’s do the same here.
Event Sourcing describes a concept of persisting application entities (i.e.: aggregate roots) as sequence of events that create and alter them:
- AccountCreated
- BillingAddressChanged
- CustomPropertyAdded
- AccountCharged
- AccountSuspended
- etc
By its nature, the simplest implementation of event sourcing only needs two tables (table with primary keys and another one with serialized events) and represents full audit log of all the changes. When we load the entity, we simply replay all events since the beginning. Obviously, such storage in the classical SQL world would be less than performant, if we regenerate large entity for every operation. However we can simply keep the entity in memory (they are not that large anyway), use snapshots and distribute aggregate roots between the machines.
Martin Fowler has written extensively about event sourcing and focusing on events in general.
One can create audit logs without the event sourcing. For example in the billing subsystem, where accounts are allowed to have balances, balance could be defined as an append-only table, just like in the real-world accounting. In order to modify the balance, append a row with the change amount and new value. Optionally accountant information and operation name could be included.
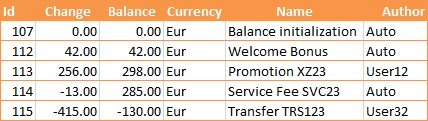
In order to get the actual balance – simply:
SELECT TOP 1 * FROM [Balance] ORDER BY [Id] DESC WHERE [AccountId] = ?
Although for the majority of the display purposes (which happen to be more than 80% of the cases) accessing denormalized query table would work perfectly without hitting the DB hard even in "Show total balance by account" types of the reports. CQRS uses this approach heavily and will be discussed later.
Software will always have bugs and problems. Keeping extra information around (audit logs is one form of that) helps to make life less painful and issues - less expensive. Release It!: Design and Deploy Production-Ready Software is an incredible read on the subject of delivering and handling real-world solutions.
Aggregate Root concept (along with terms like Bounded Context, Ubiquitous Language or Value Object), comes from the world of Domain Driven Design (DDD), which defines a way of modeling business entities in the process of software design, development and evolution. Basically, it links together business concepts and the evolving software model. Principles start from the principles of thinking and communicating and go up to the allowed logical relations between the entities.
Jonathan Oliver has gathered a nice overview of materials introducing developer in the world of DDDD and CQRS.
Fourth D in the DDDD comes from the Distributed. It, as the name implies, brings us closer to everything that is distributed, large-scale and cloudy. By a coincidence, principles of Command-query responsibility separation (CQRS) happen to address some problems that the DDDD faces.
The very principle of representing business changes and processes in form of events, commands and messages, is close to the concepts of the messaging systems, middleware and, as far as message processing is concerned, service buses. Concepts of message-driven architecture help to decouple complex systems and processes (this usually happens within the boundaries of a service layer), while making them more reliable and easier to comprehend. Enterprise integration (especially in the world of unreliable systems) also depends on messaging heavily.
Enterprise Integration Patterns book is a must-read for everybody interested in the subject. Advanced Message Queuing Protocol Specification is also an eye-opening material (it's not boring).
CQRS as a concept is a way of architecturing systems that attempts to deal with some of the frustrating problems of delivering enterprise software:
- Performance bottlenecks and scalability
- Concurrency conflicts, their resolution and prevention
- Data staleness
- Complexity of the design, development and maintenance
CQRS attempts to deal with these problems by reevaluating constraints and assumptions that we’ve been considering to be true and valid for the last X0 years. This allows to rethink core principles and the architecture.
In an oversimplified manner, CQRS separates commands (that change the data) from the queries (that read the data). This simple decision brings along a few changes to the classical architecture with service layers along with some positive side effects and opportunities.
At the micro-development level Command-query separation says that method can either be a query (returning data to the caller) or a command (changing the state), but not both.
In other words, asking the question should not change the answer.
So if we go deeper, Command-query Responsibility Separation is about development principles, patterns and the guidance to build solution architecture on top of them.
Udi Dahan has a brilliant paper on the Clarified CQRS. He also blogs frequently on the subject along with Greg Young (who is supposed to be writing a book on the DDDD and CQRS) and Jonathan Oliver.
Here's one of the simple architectural overviews with some details.
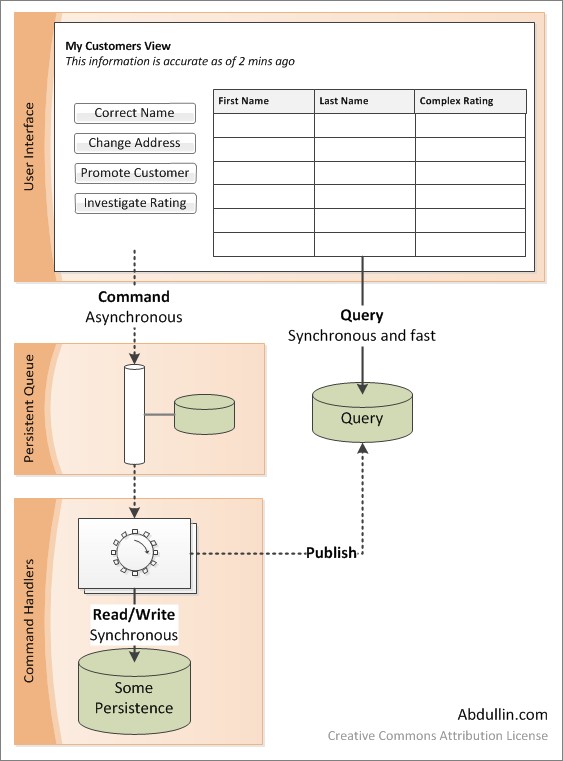
- All data presented to the user is stale anyway, since we don’t keep UI in constant sync with the database, refreshing every millisecond. And since it is ok, let’s use this.
- Querying data for presentation and accessing it for the changes do not have to use the same resources. In fact, since querying happens in 80%-90% of the cases (people read often, modify less), let’s take some time (a few seconds, for example) and denormalize the data heavily and publish it to some easily accessible locations. Presentation UI will just have to do
SELECT * FROM [MyCustomersView] WHERE…
- Instead of updating the entire entities (i.e. reading and writing the entire BillingAccount when just the email changes) let’s send a ChangeBillingEmailCommand to the server.
- Before sending this command let’s use our query tables to verify that the email address is unique and correct. This should give us 99.99% probability that it will be accepted. It’s OK. So send the command and move on.
- When the command lands into the server – place it into the queue. This way it’ll be processed even if the server is off-line, too loaded or encounters an eventual deadlock. We could additionally distribute work between multiple servers, which is becoming embarrassingly easy in the era of cloud computing.
- When command is being processed, double check the validation and business rules. In the unlikely chance that something is wrong with the command data – send user a message (i.e.: email address has changed by somebody else).
- Flow of commands could be saved somewhere, forming a sort of auxiliary audit log, JIC.
- After the command is processed – take a little bit of CPU cycles to update our query tables to make them easier to be consumed by presentation and validation logic. Here we just make sure that all these complex joins have to happen only once, keeping reads (which happen more often than writes) extremely fast. In fact, since storage is cheap, we can aggressively use query tables (i.e.: query per view per role) and also distribute them.
- Domain commands and events could be used to split complex systems in order to reduce complexity or distribute the load as well. Middleware messaging systems or even rich service buses could be used here. Cloud bursting scenarios are applied here easily as well.
- Commands, events and other types of messages happen to correlate to the terms from Ubiquitous Language of the domain (they actually form it), so the DDD could be used in the process of communicating over, architecting and evolving the enterprise system.
- Persistence does not really matter here, so we can go ignore it, while using rather rare patterns like event sourcing (giving us full audits and simplifying the replication) or document databases. Actually, query data does not need to be in the relatively expensive RDB at all.
- CQRS and Event Sourcing also simplify implementation of the flexible entity models with various custom fields and properties that are often defined at the run-time and used in layout and drag-n-drop designers by the end-users.
- CQRS significantly simplifies introduction of business intelligence into the enterprise solutions. BI helps to make better decisions that make business - better (reducing expenses and increasing profits).
As you can see from this brief overview, there are quite a lot of different patterns and ideas composing the domain around CQRS and DDDD. Common trend is that they generally have synergy effect, where using a few of these patterns might create additional benefits or simplify the design. Yet, as in any real-world project, it is strongly advised against taking all these principles and dumping into the architecture blindly. It’ll probably hurt.
It’s more beneficial to learn, understand and practice all of these, but use only the ones that fit the project (feeling free to adapt them as needed).
Please keep in mind that this overview is brief and quite a bit of important problems were left out along with their solutions. Some of these problems are listed below (to give you the idea of the scope) while answers could be found in the materials referenced in the article.
- How do we handle failing commands from the user's perspective?
- How can we handle delays in the updates of the query data from the UI perspective?
- Data validation vs. business context rules in the CQRS
- Resolving database deadlocks and the command-handling level.
- Elastically scaling processing capacities.
- How do we apply CQRS principles in the world of AJAX and web applications; Smart Clients?
- How and where do we host command handling services?
- etc
If you are interested in more articles on this topic, you can stay tuned by subscribing to this blog via RSS.
Note, that this document starts outlining the scope of the xLim 4 body of knowledge on efficiently building flexible and light distributed information management systems. There also is a separate page aggregating information on the CQRS.
All comments, thoughts, questions and any other feedback are welcome and appreciated.
So, what do you think?
Related Posts:
- Command-Query Responsibility Segregation
- CQRS - Validation and Business Rules
- CQRS - Automatically Visualize and Document Your Solution
Published: March 23, 2010.
🤗 Check out my newsletter! It is about building products with ChatGPT and LLMs: latest news, technical insights and my journey. Check out it out